原文:A Framework For Contrastive Self-Supervised Learning And Designing A New Approach-2020.09.03
论文:A Framework For Contrastive Self-Supervised Learning And Designing A New Approach-2020
节选,学习.
关于对比学习和自监督学习,PyTorch Lightning 开源了相关的代码实现:SELF-SUPERVISED LEARNING,如:
[1] - Augmented Multiscale Deep InfoMax (AMDIM)
[2] - Bootstrap Your Own Latent (BYOL)
[3] - Data-Efficient Image Recognition with Contrastive Predictive Coding
[4] - Moco
[5] - SimCLR
[6] - SwAV
[7] - Exploring Simple Siamese Representation Learning (SimSiam)
1. 自监督学习
监督学习:给定输入 x 和标签 y.

图:左-输入x,右-标签y
自监督学习:仅有输入 x. 模型学习从输入的其他部分预测输入的一部分.

图:左-输入;右-标签
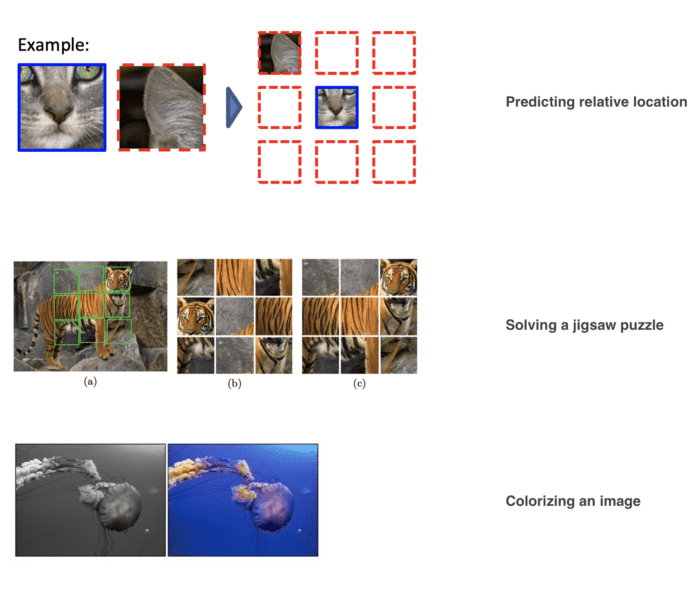
自监督学习问题比较通用,相关的前置任务(pretext task)如:
[1] - 预测两个图像块的相对位置 [predicting relative locations of two patches]
[2] - 拼图 [solving a jigsaw puzzle]
[3] - 图像上色 [colorizing an image]
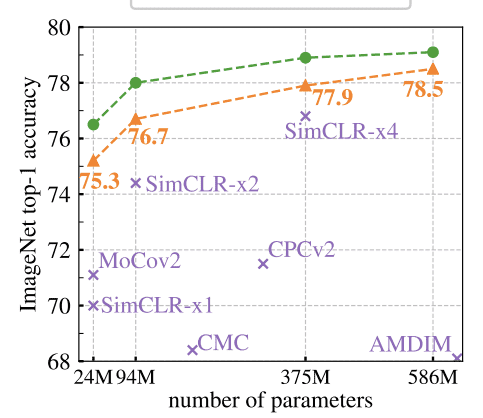
对比学习极大地缩小了在 ImageNet 上与监督学习方法的差距.
2. 对比学习
大部分机器学习算法的基本思想是,相似样本聚集,而与其他聚类的样本远离.
Learning a Similarity Metric Discriminatively, with Application to Face Verification - 2004
动画如:

对比学习三个部分:anchor、positive、negeative.
正样本对,两个样本相似;负样本对,不相似的第三个样本.

但是,自监督学习中,样本的标签是未知的,因此无法确定两张图片是否相似.
不过,如果假设每个图片是一个类,那么就可以想办法构建 triplets(正负样本对),也就意味着数据集大小为 N 时,会存在 N 个标签.

因此,就可以知道每张图片的标签了,可以采用数据增强生成 triplets.
2.1. 特征1 - 数据增强
第一种表征对比自监督学习方法的方式是,定义数据增强pipline.
数据增强pipline $A(x)$ 对相同的输入采用一序列的随机变换.

深度学习中,数据增强旨在构建原始输入的对噪声鲁棒的表示. 例如,即使图片旋转,或去除颜色,或像素抖动,网络模型也应该能识别.
而对比学习中,数据增强还有第二个作用,即,用于生成 anchor、positive、negative 样本,以送入编码器及提取特征表示.
2.1.1. CPC
CPC pipline 除了采用如颜色抖动、灰度化、随机翻转等变换,还进行一种特殊变换,即将图片划分为重叠子图像块.

图:CPC 的关键变换.
CPC 可以生成很多 positive 和 negative 样本集.

图:从 batch 图片中生成positive、anchor、negative 样本对[如,batchsize=3]
2.1.2. AMDIM
AMDIM 采用的方法略有不同. 其在标准的数据增强后[如,抖动、翻转等],再通过对相同图片进行两次数据增强,以生成一张图片的两个版本.

这种想法实际上是在论文 Discriminative Unsupervised Feature Learning with Convolutional Neural Networks-2014中提出的. 其是采用 seed 图片生成相同图片的许多版本.
2.1.3. SimCLR
可见视频:https://www.youtube.com/embed/Mrp2ntS2QxI
2.2. 特征2 - 编码器
第二种表征对比自监督学习方法的方式是,编码器的选择.
大部分方法采用的是 ResNets 及其衍生网络.
2.3. 特征3 - 表征提取
第三种表征对比自监督学习方法的方式是,提取特征表示所采用的策略.
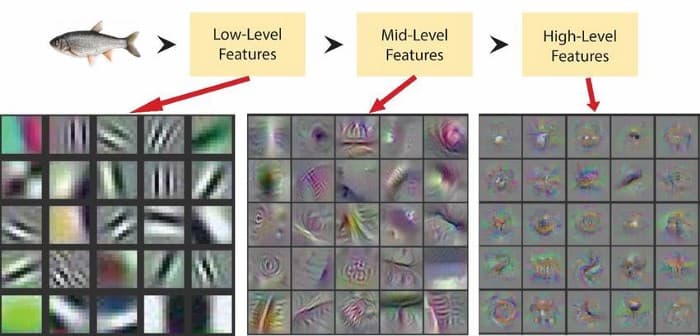
表征的定义:其是一组独特的特征,使得系统和人类能够理解是什么构成了那个对象,那个对象,而不是不同的对象.
A representation is the set of unique characteristics that allow a system (and humans) to understand what makes that object, that object, and not a different one.
如图,一种好的特征表示可能是角的数量.

2.3.1. CPC
CPC 提出了通过在隐空间(latent space)预测未来(future)的方式学习表征. 其包含两个方面:
[1] - 将每张图片看作是时间线,从左上角(过去)到右下角(将来)

[2] - 预测并不是在像素层进行的,而是采用编码器的输出(如,隐空间latent space)

图:从像素空间到隐空间
最后,通过将编码器H的输出作为投影head(论文作者称之为上下文编码器)生成的上下文向量的目标,来构造预测任务,以进行表示提取.

图:CPC 表示提取
2.3.2. AMDIM
AMDIM 的思想是,使用从 CNN 网络中间层提取的特征图的视图间(across views)的表示进行比较.
可以将其分解为两部分:单张图像的多视角;CNN的中间层.
[1] - AMDIM 的数据增强中,生成同一张图片的两个版本.

[2 ]- 每个版本的图片均送入相同的编码器,以每张图片的提取特征图. AMDIM 并未丢弃编码器生成的中间特征图,而是对其进行跨空间尺度(spatial scales)的对比. 如图,CNN中间层的接收野编码了输入的不同尺度的信息,
AMDIM 跨CNN中间层输出进行对比. 如图,跨编码器生成的三个特征图进行对比.

图:AMDIM 表示提取:AMDIM 采用相同的编码器提取 3 组特征图集合;然后,跨特征图进行对比.
2.3.3. SimCLR
SimCLR 采用了类似于 AMDIM 的思想,但有2处修改.
[1] - 仅使用最后一个特征图;
[2] - 将特征图井投影head 处理,再比较两个向量.
2.3.4. BYOL
BYOL 采用与 AMDIM 相同的思想(但仅采用最后一个特征图),但有两处改动:
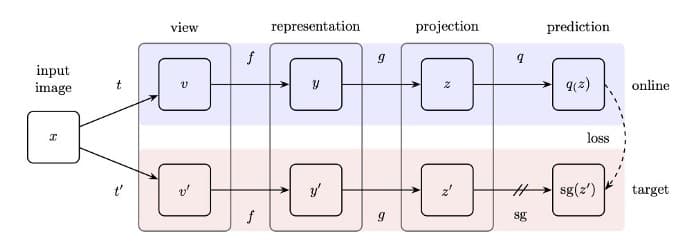
[1] - BYOL 采用了两个编码器,而不是一个. 第二个编码器实际上是第一个编码器的副本,以滚动平均的方式更新权重,而不是每次迭代中更新权重.
[2] - BYOL 不需要使用负样本. 相反,其依靠滚动权重更新来给训练提供对比信号.
2.3.5. Swav
将表示提取任务看作为在线聚类(online clustering)的一种,其中,强制保持相同图片不同数据增强的代码之间的一致性. 类似于AMDIM(仅使用最后一个特征图),但其不是直接将向量相互比较,而是根据一组 K 个预计算代码来计算相似度.

实际上,这意味着,Swav 会生成 K 个聚类,并且对于每个编码向量,其将于这些聚类进行比较,以学习新的表示.
2.4. 特征4 - 相似性度量
第四种表征对比自监督学习方法的方式是,所采用的相似度度量方式.
上面这些方法均采用的是点积(dot product)或余弦相似性(cosine similarity).
本文作者实验表明,相似性的选择很大程度是不那么重要的.
2.5. 特征5 - 损失函数
第五种表征对比自监督学习方法的方式是,所采用的损失函数.
除了 BYOL,均采用了NCELoss.
NCELoss 包含两部分,分子和分母. 分子鼓励相似的向量彼此靠近,分母把所有其他向量推的更远.
如果分母不存在,则损失变为一个常数,所学的特征表示也将没有用处.
看到这篇博文最后,只能感叹大厂才玩得起的钞能力.