题目: Mask R-CNN - ICCV2017
作者: Kaiming He, Georgia Gkioxari, Piotr Dollar, Ross Girshick
团队: Facebook AI Research (FAIR)
Detectron - Code-Caffe2
Mask_RCNN - Code-Keras-Tensorflow
ICCV tutorial
ICCV oral
COCO workshop
目标问题:object instance Segmentation
关键点:
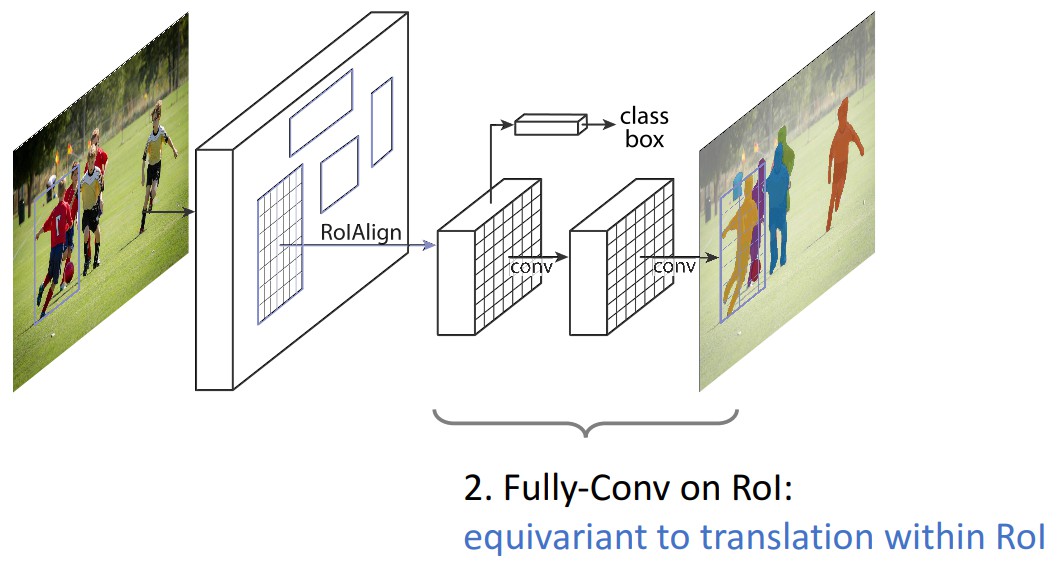
- RoIAlign Layer - RoIPool Layer 改进版本
- Mask Branch - 在 RoI 上的分割结果
- Decouple Mask and Class Prediction using Binary Sigmoid Activations vs Multi-class Softmax
Mask R-CNN 能有效的检测图片中的 objects,同时生成每个 instance 的高质量 segmentation mask.
基于 Faster R-CNN,在保留其现有的 bounding box 检测分支的基础上,并列地新增一个预测 object mask 的网络分支.
Mask R-CNN 较好的泛化能力,能够用于人体姿态估计等其它任务.
在 COCO 的 instance segmentation, bounding-box object detection, person keypoint detection 三类竞赛均取得 top results.
Instance Segmentation —— 正确的检测图片中的所有 objects,并精确地分割每一个 instance.
Object detection —— 正确的分类图片中的 objects,并定位各 object 的 bounding box.
Semantic Segmentation —— 对图片的每一个像素进行分类,输出mask,不需要区分 object instances.
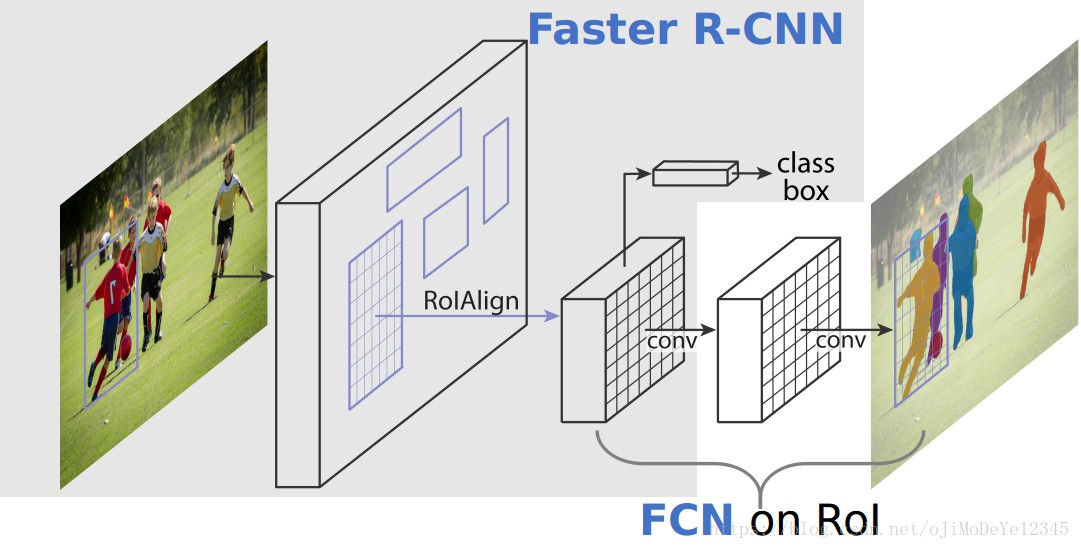
Figure 1. Mask R-CNN 实例分割框架. 基于 Faster R-CNN,在其分类和 bounding box 回归的网络分支基础上,并行地新增一个对每个 RoI(Region of Interest) 预测分割 masks 的网络分支.
- mask 分支采用 FCN 对每个 RoI 预测像素级的分割 mask.
- RoIAlign 替代 RoIPool —— 由于 RoIPool 是映射原图RoI 到特征图 RoI,其间基于 stride 间隔来取整,导致将特征图RoI映射回原图RoI时,出现 stride 造成的误差(max pool 后特征图的 RoI 与原RoI 间的空间不对齐更加明显). 会影响像素级的 mask 分割. 因此需要像素级的对齐.
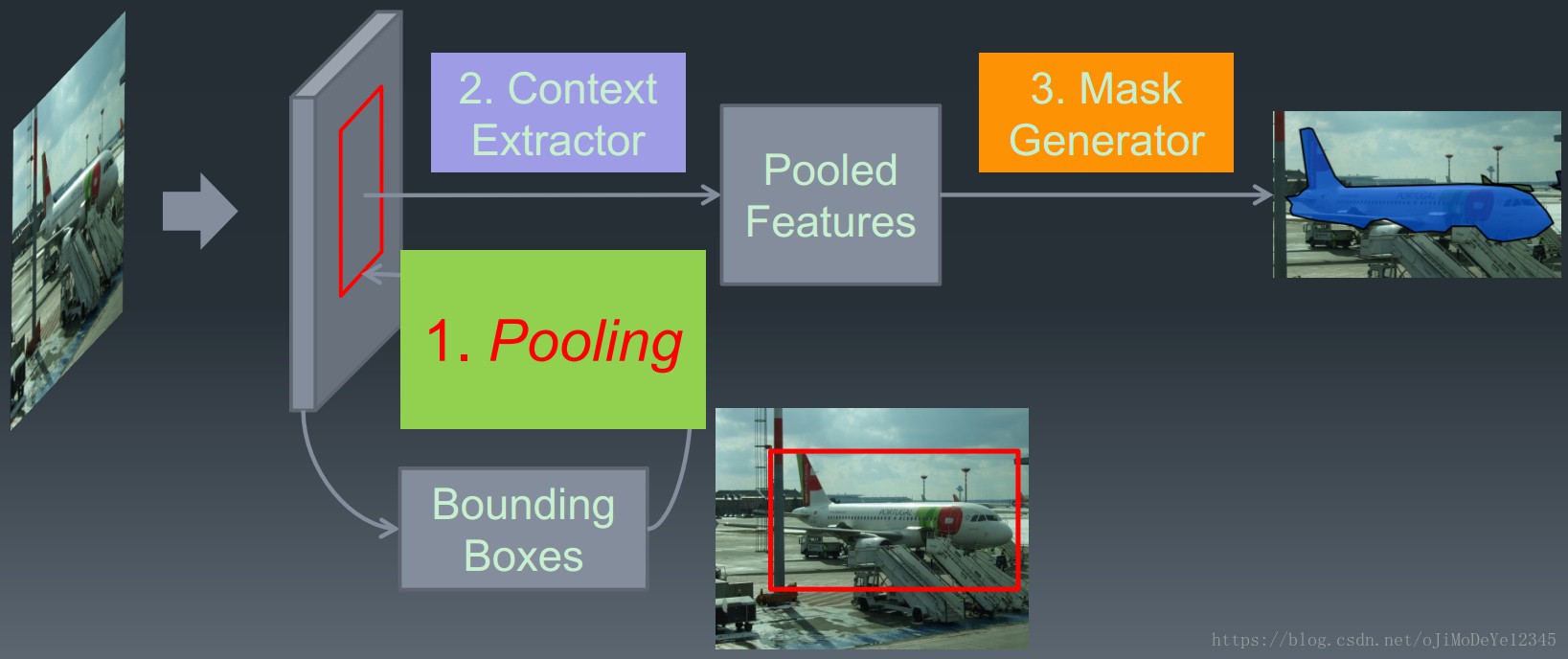
[From Face++]
1. Mask R-CNN
网络分支:
- 每个候选 object 的 class label - Faster R-CNN
- 每个候选 object 的 bounding-box offset —— Faster R-CNN
- 每个候选 object 的 mask - added
Faster R-CNN 包括两个阶段:
- 1st Stage —— Region Proposal Network(RPN),得到候选 object 的 bounding-boxes;
- 2st Stage —— 采用 RoIPool 从每个候选 box 提取特征,并进行分类和 bounding-box 回归.
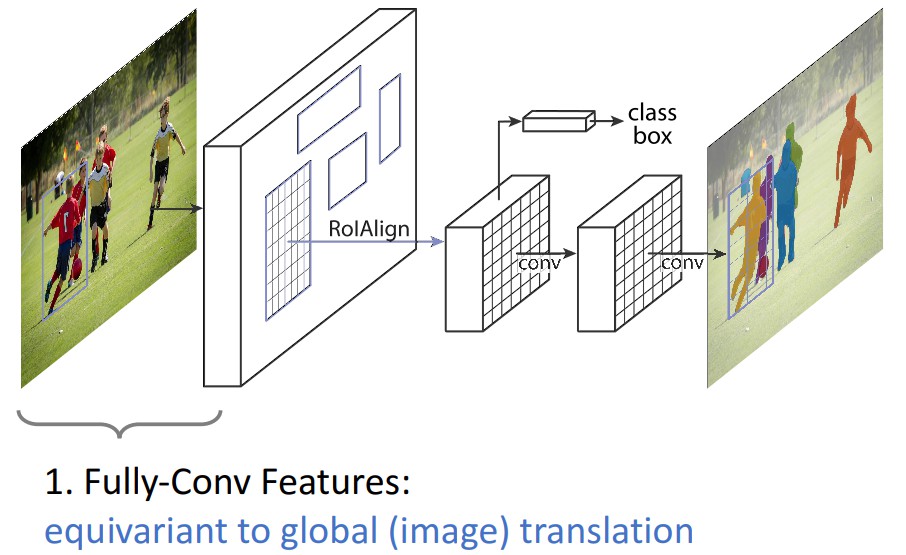
1.1 Loss 函数
训练时,对每个采样的 RoI 的 multi-task loss 为:
${ L= L_{cls} + L_{box} + L_{mask} }$
${ L_{cls} }$ - 分类 loss
${ L_{box} }$ - bounding-box 回归 loss
${ L_{mask} }$ - mask 分割 loss
mask 网络分支采用 FCN 对每个 RoI 的分割输出维数为 ${ Km^2 }$,即 K 个类别的 m×m 的二值 mask. 采用像素级 Sigmoid,定义 ${ L_{mask} }$ 为平均二值交叉熵损失函数(average binary cross-entropy loss). 一个 RoI 仅与 ground-truth 类别 k 相关,${ L_{mask} }$ 只与第 k 个 mask 相关,不受其它的 mask 输出的影响.
${ L_{mask} }$ 使得网络能够输出每一类的 mask,且不会有不同类别 mask 间的竞争. 分类网络分支预测 object 类别标签,以选择输出 mask,解耦了 mask 和 class 预测间的关系.
传统 FCNs 采用 per-pixel 的 softmax 和 multinomial cross-entropy loss,会造成不同类别的 mask 间的相互影响;
${ L_{mask} }$ 采用 per-pixel sigmoid 和 binary loss,避免了不同类别的 mask 间的影响. 有效的提升了 instance segmentation 效果.
1.2 Mask Representation
mask 编码了输入 object 的空间布局(spatial layout).
针对每个 RoI,采用 FCN 预测一个 m×m 的 mask.
mask 分支的每一网络层均可保持 m×m 的 object 空间布局,而不用压扁拉伸成向量形式来表示,导致空间信息损失.
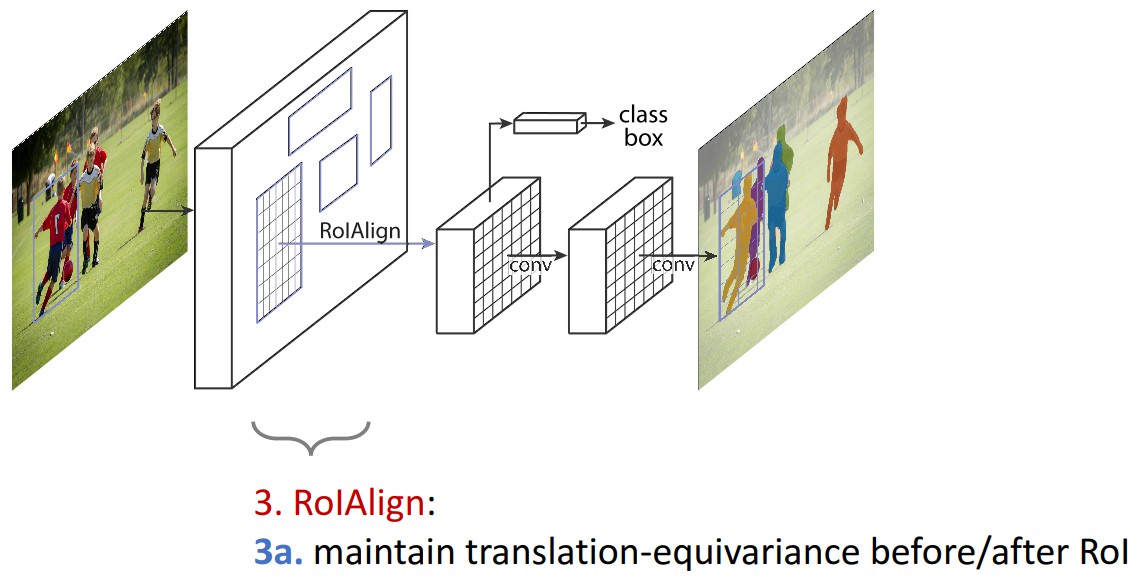
pixel-to-pixel 操作需要保证 RoI 特征图的对齐性,以保留 per-pixel 空间对应关系. 即 RoIAlign.
1.3 RoIAlign
RoIPool 用于从每个 RoI 中提取小的特征图(如 7×7),RoIPool 选择的特征图区域,会与原图中的区域有轻微出入. 首先,对浮点数 RoI 进行量化,再提取分块的直方图,最后利用 max pooling 组合. 导致 RoI 和提取的特征间的 misalignments. 对于平移不变性的分类任务,这种影响不大,但对于精确的像素级 masks 预测具有较大的负影响.
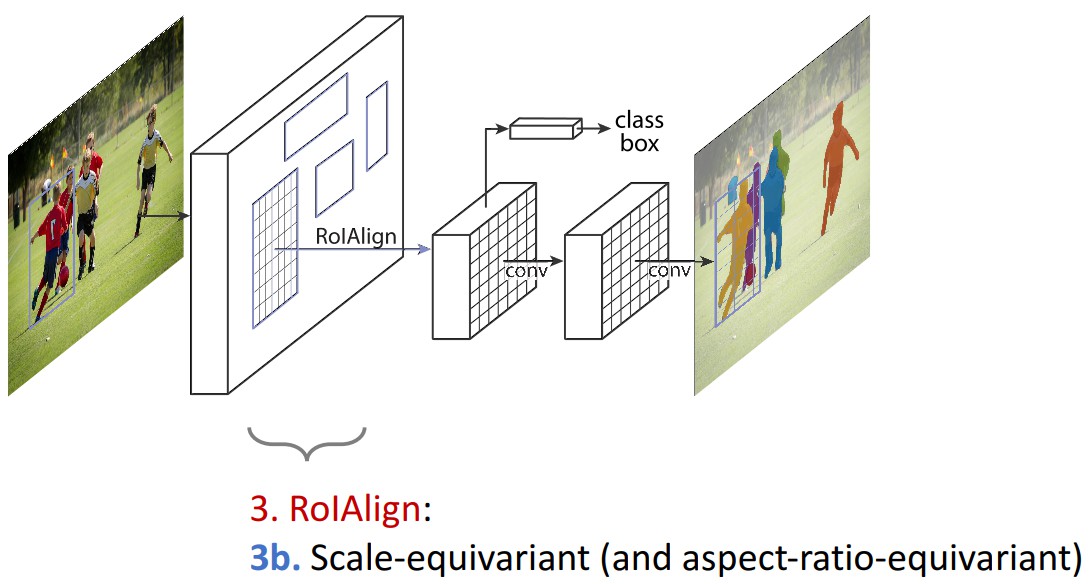
RoIAlign 能够去除 RoIPool 引入的 misalignments,准确地对齐输入的提取特征. 即: 避免 RoI 边界或 bins 进行量化(如,采用 ${ x/16 }$ 来替代 ${ rounding(x/16) }$[四舍五入处理] );采用 bilinear interpolation 根据每个 RoI bin 的四个采样点来计算输入特征的精确值,并采用 max 或 average 来组合结果.
如,假设点 (x,y),取其周围最近的四个采样点,在 Y 方向进行两次插值,再在 X 方向 进行两次插值,以得到新的插值. 这种处理方式不会影响 RoI 的空间布局.
假设有一个 128x128 的图像,25x25 的特征图,想要找出与原始图像左上角 15x15 位置对应的特征区域,怎么在特征图上选取像素?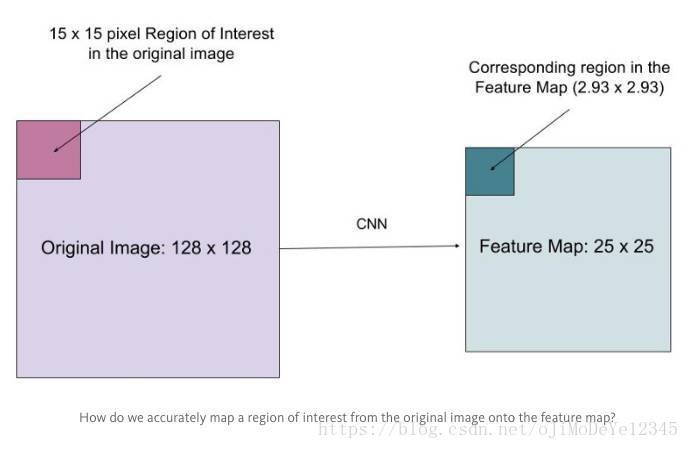
原始图像的每一个像素与特征图上的 25/128 个像素对应. 为了在原始图像选取 15 个像素,在特征图上我们需要选择 15 * 25/128 ~= 2.93 个像素.
对于这种情形,RoIPool 会舍去零头选择两个像素,导致排列问题. 但在 RoIAlign,这种去掉小数点之后数字的方式被避免,而是使用双线性插值(bilinear interpolation)准确获得 2.93 像素位置的信息,避免了排列错误. 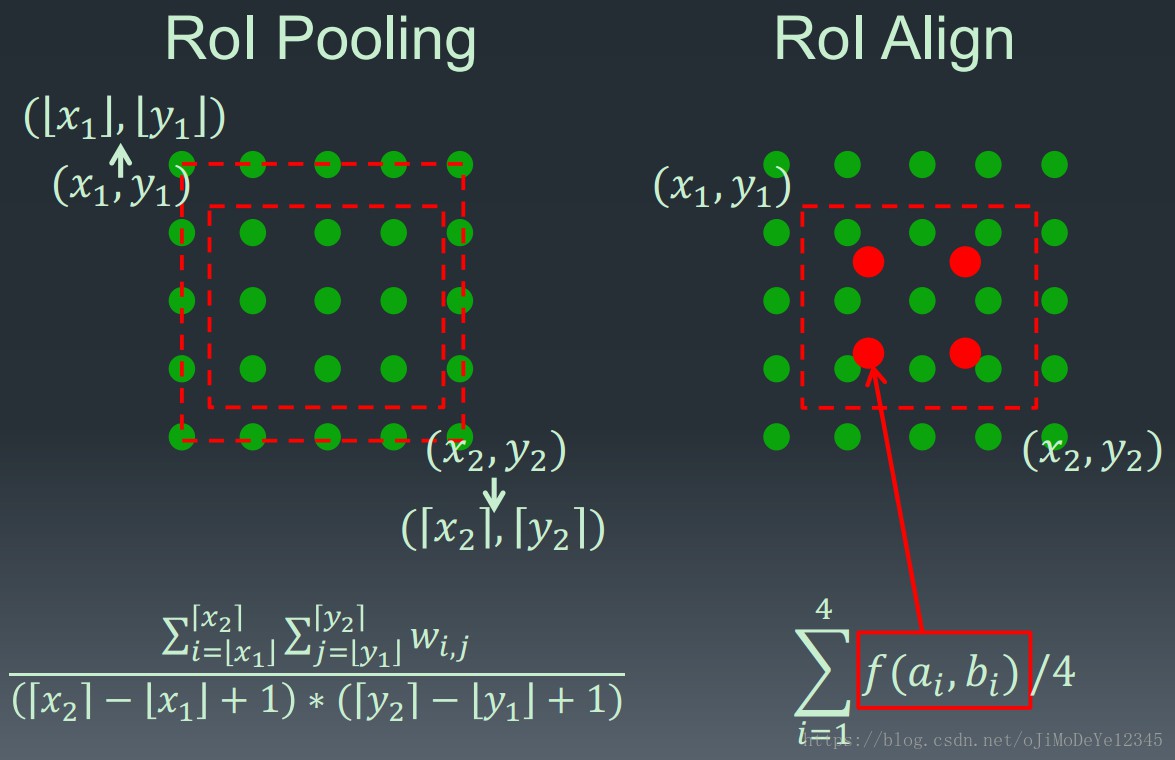
[From Face++]







1.4 网络结构
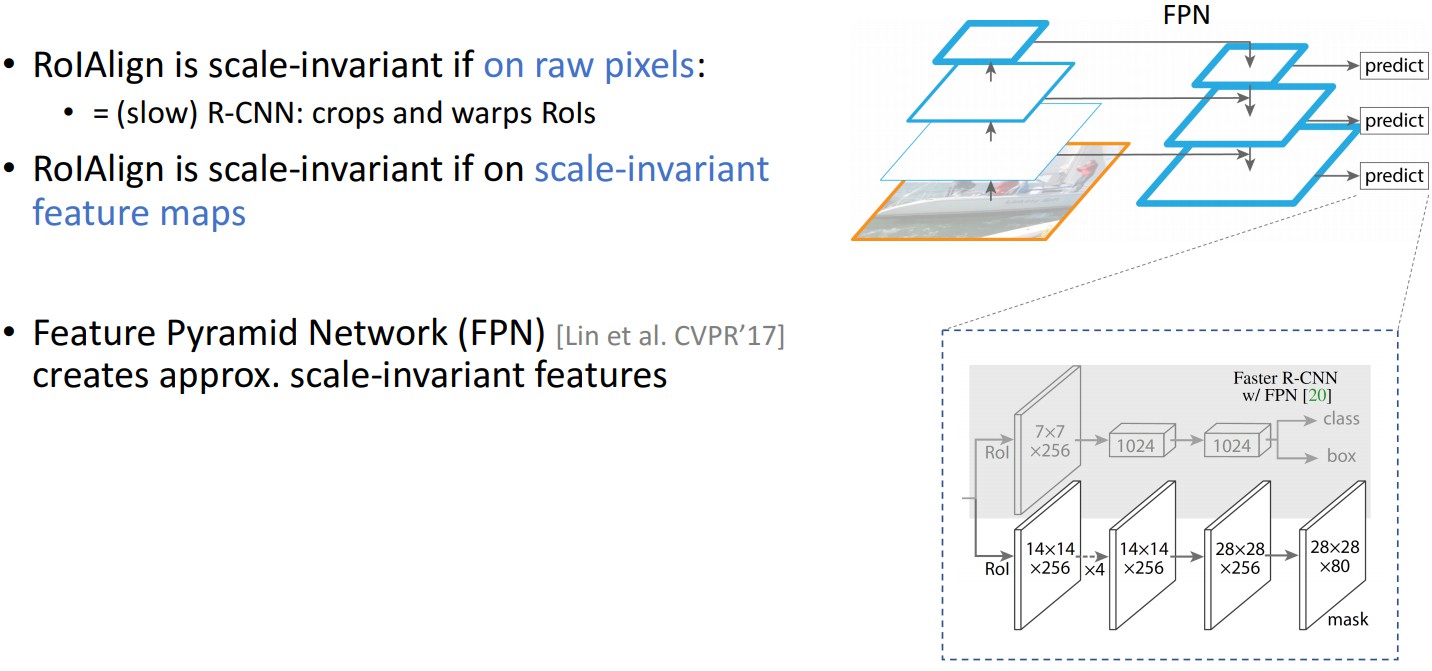
Backbone 卷积网络 —— 用于整张图片的特征提取 ,ResNeXt-101,ResNet-50,FPN(Feature Pyramid Network).
- Backbone1:Faster R-CNN 基于 ResNets,是从第 4 stage 的最后一个卷积层提取特征,这里记为 C4,即 ResNet-50-C4,ResNeXt-101-C4.
- Backbone2:ResNet-FPN
Head 网络 —— 用于对每个 RoI 分别进行 bounding-box 识别(分类和回归) 和 mask 预测.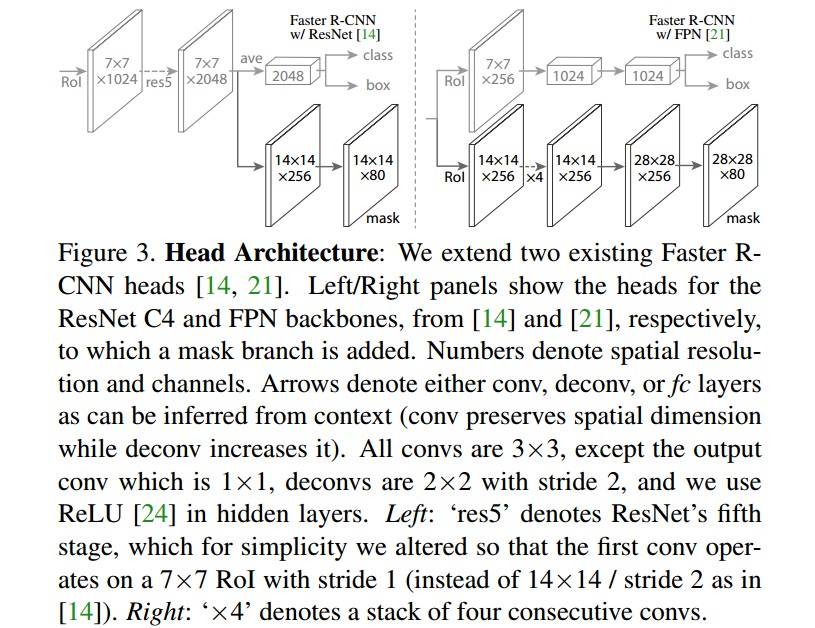
1.5 实现细节
超参数设置基于 Fast/Faster R-CNN.
[1] - 网络训练
训练阶段,Fast R-CNN中,如果 RoI 与 groundtruth box 的 IoU > 0.5,则 RoI 为 positive;否则,RoI 为 negative.mask loss ${ L_{mask} }$ 仅在 positive RoIs 上定义. mask target 是 RoI 与其对应的 groundtruth mask 的交集.
采用 image-centric 训练. 将图片的长宽较小的一边缩放到 800个像素.每个 GPU 的 mini-batch = 2,每张图片有 N 个采样 RoIs,positive 和 negative 的比例为 1:3.在 8 GPUs 上训练,batchsize=2, 160k 迭代,learning_rate = 0.02,每 120k 次迭代减少 10 倍.
weight_decay=0.0001,momentum=0.9.
[2] - 网络推断
测试阶段,采用的 proposals 的数量分别 为 300 (Faster RCNN) 和 1000(FPN).在这些 proposals 上,采用 bounding-box 网络分支和 NMS 来预测 box.然后,采用 mask 网络分支对最高 score 的100 个检测 boxes 进行处理. 这里是与训练时的并行处理不同的,但基于更少,更精确的 RoIs,能够加速推断效率,提升精度.mask 网络分支对 每个 RoI 预测 K 个 masks,但这里只使用第 k 个mask( k 是分类网络分支预测的类别标签). 得到的 m×m 的浮点型 mask 输出再 resized 回 RoI 的尺寸,并以 0.5 的阈值进行二值化.
2. 实验结果
2.1 实例分割 Instance Segmentation
实例分割结果对比: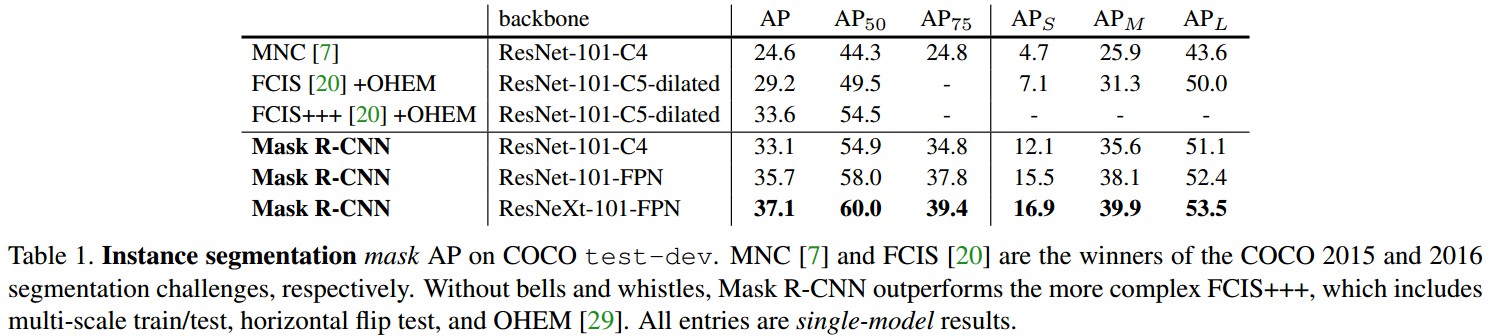



网络,Loss 和 RoIAlign 等的影响:
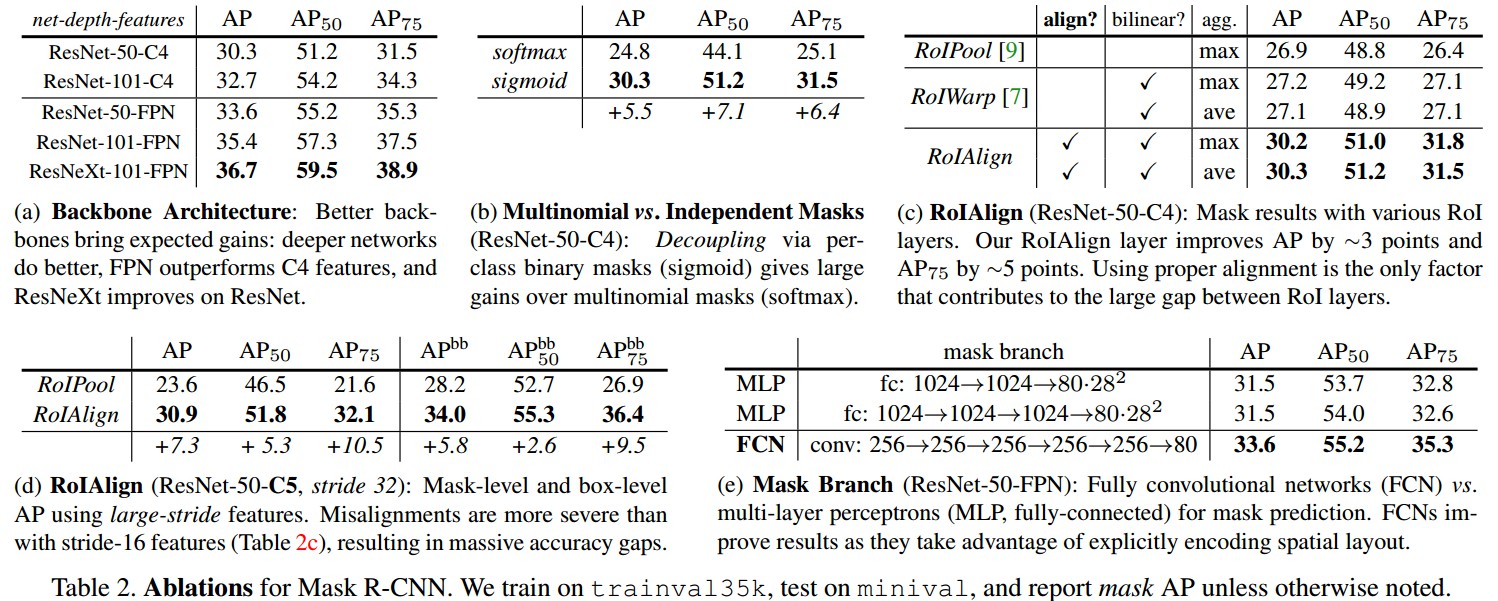
Bounding Box 检测 结果对比: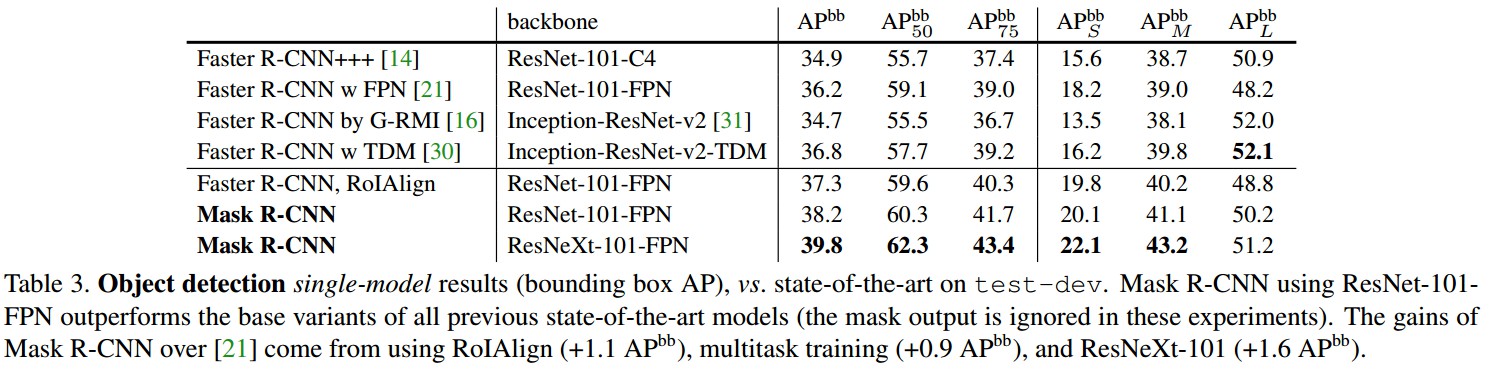
时间分析:
- 训练阶段:
COCO trainval 35k 数据集上,8-GPUs, ResNet-50-FPN 耗时 32 hours,ResNet-101-FPN 耗时 44 hours. - 测试阶段:
ResNet-101-FPN 在 Nvidia Tesla M40 GPU 每张图片 195 ms. ResNet-101-C4 耗时 400 ms.
2.2 人体姿态估计 Human Pose Estimation
说明 Mask R-CNN 的扩展性.
将 keypoint 的位置表示为 one-shot mask,采用 Mask R-CNN 来预测 $K$ 个 masks,每个 mask 分别对应一个 keypoint.
[1] - 对于一个实例的 K 个 keypoints 中的每一个,训练目标是得到 one-hot m×m 的二值mask,其中只有一种像素被标记为前景,其它为背景.
[2] - 训练时,对于每个可见的 groundtruth keypoint,最小化 m^2 -way softmax 输出的 cross-entropy loss(检测单个 keypoint). 这里类似与 instance segmentation,$K$ 个 keypoints 也是被独立处理的.
[3] - 基于 ResNet-FPN, keypoint 的 head 网络结构类似于 Figure3(右),如下:
主要由 8 个 3×3 512-d 卷积层,其后接 1 个 deconv 层和 1 个 2× bilinear upscaling,最终输出一个分辨率为 56×56 的特征图.
Mask R-CNN 发现,关键点定位的精确度需要相对高的分辨率输出.
[4] - 训练数据集 COCO trainval 35k 标注的 keypoints 数据
训练是图像的尺度随机的从 [640, 800] 中采样;
测试时图像采用单一尺度 800 像素;
训练 90k 次迭代, learning_rate=0.02,在 60k 和 80k 次迭代时降低 10 倍;
NMS 处理 bounding-box 的阈值 threshold=0.5.
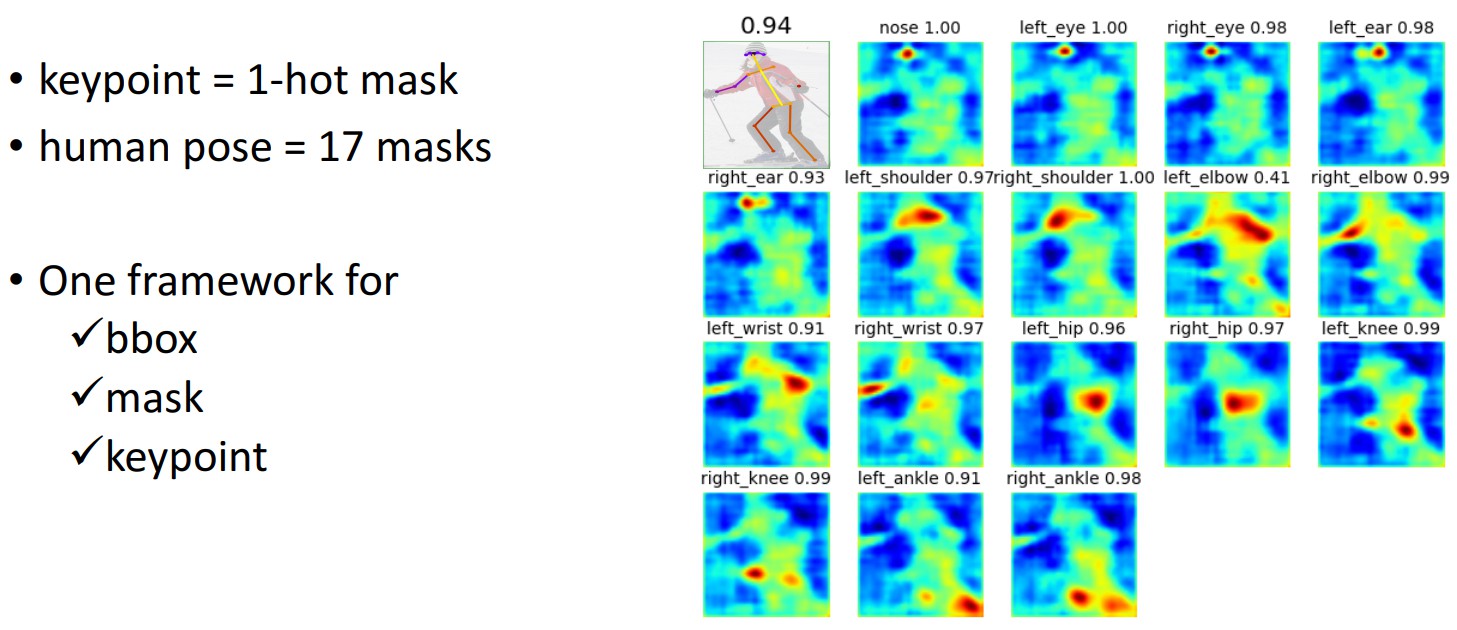
实验结果: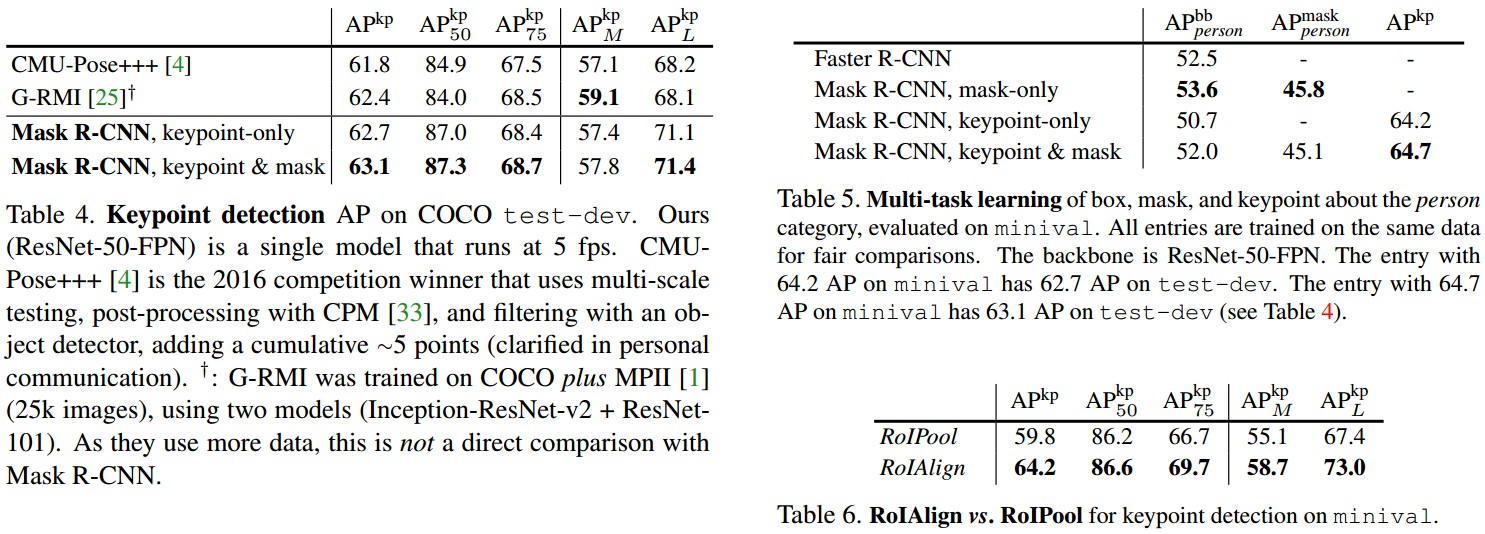

4 comments
大神,有点关于mask rcnn loss计算的问题想咨询您,您在1.1小节中写道“L_mask只与第 k 个 mask 相关,不受其它的 mask 输出的影响”那我就不明白了,既然只与真实的类别的那个mask相关,那为啥为每个 ROI生成 k个m*m的二值mask,只生成该ROI对应类别的mask不就行了吗?
每个 RoI 生成 k 个 mask 和你说的只生成对应类别的 mask 是一致的;因为对于每个类别,RoI都要生成其对应的 mask,一共 k 个类别,也就是每个 RoI 要生成分别对应每个类别的共 k 个二值mask.
也就是说,这个RoI生成mask时还不知道这个ROI对应的类别是哪个类别,所以这个RoI要生成所有类别的mask?等到并行分支的class分支得到是哪个类别后,然后再挑选出对应的类别的mask进行loss计算吗?
差不多是这种意思,可以根据源码单步调试的时候,更容易能明确些.