关于 RNN 和 LSTM 比较经典的基础知识及图例.
1. RNN
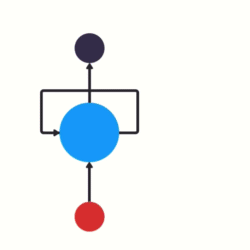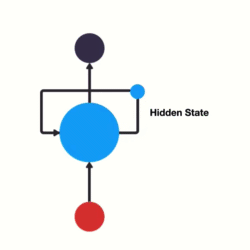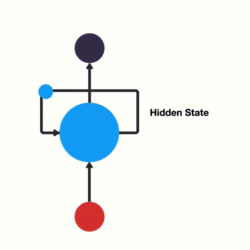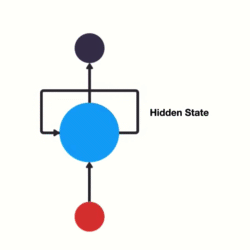
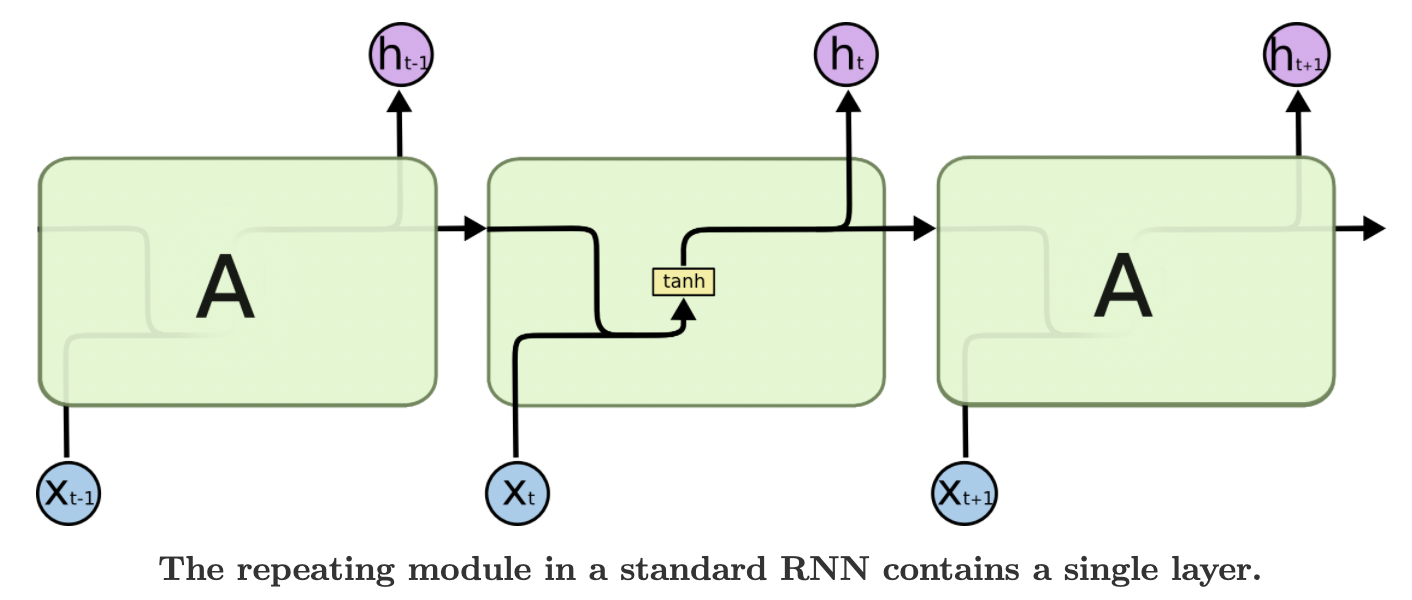
RNN,循环神经网络,其结构如:

图:RNN 包含循环结构
如图,神经网络 $A$,某个输入 $x_t$,对应输出值 $h_t$. RNN 可以是信息从当前状态传递到下一状态.
数据传递效果:
RNN 可以看作是同一神经网络的多次复制,每个神经网络模块将信息传递到下一个神经网络. RNN 的展开如图:
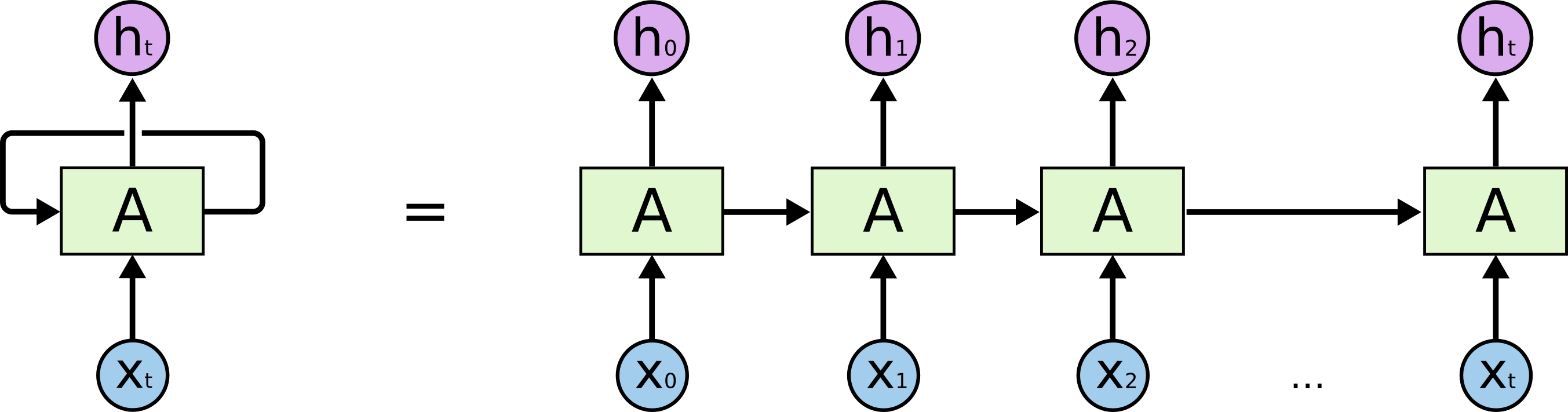
图:RNN 网络展开形式,链式结构
RNN 动图版:

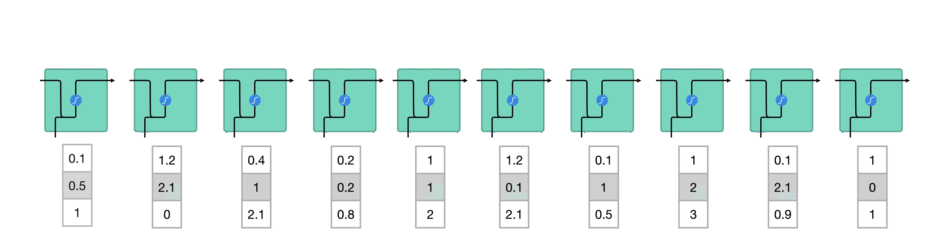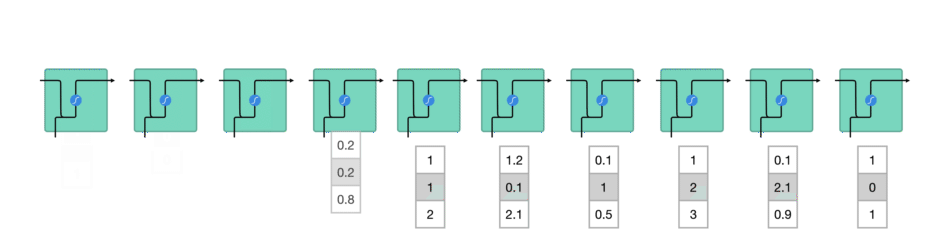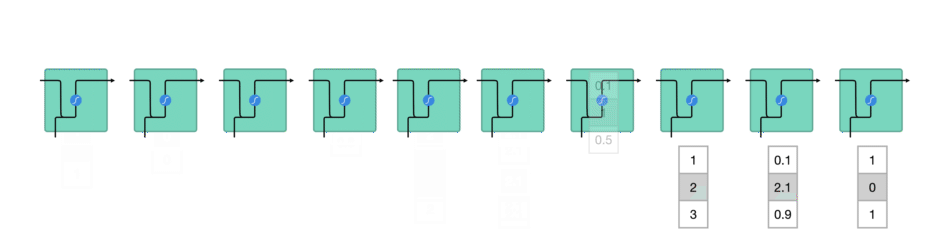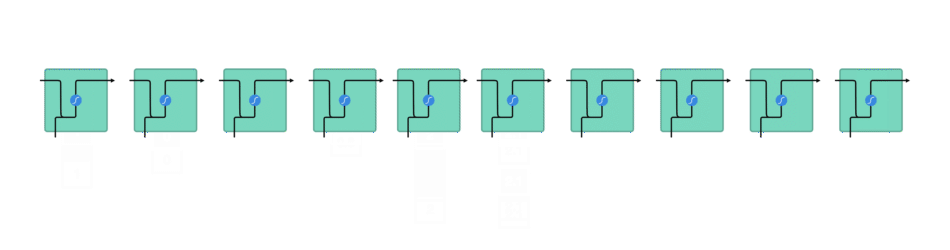
1.1. RNN 一般结构
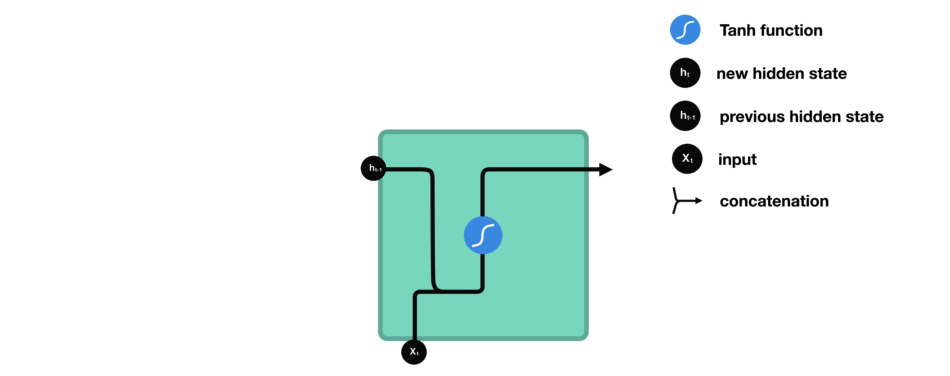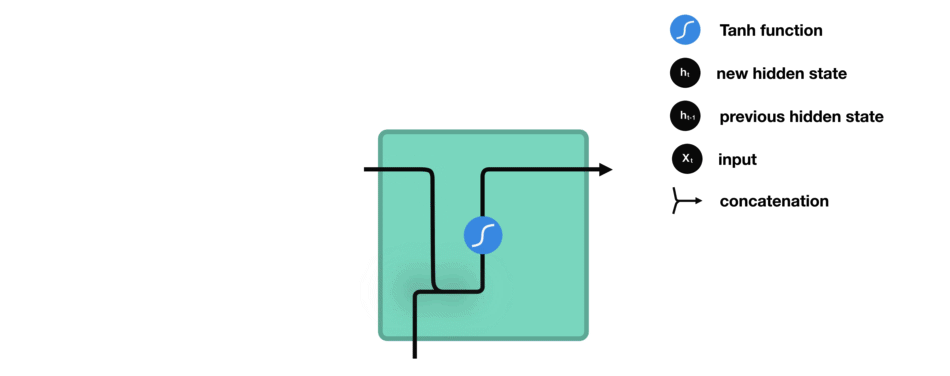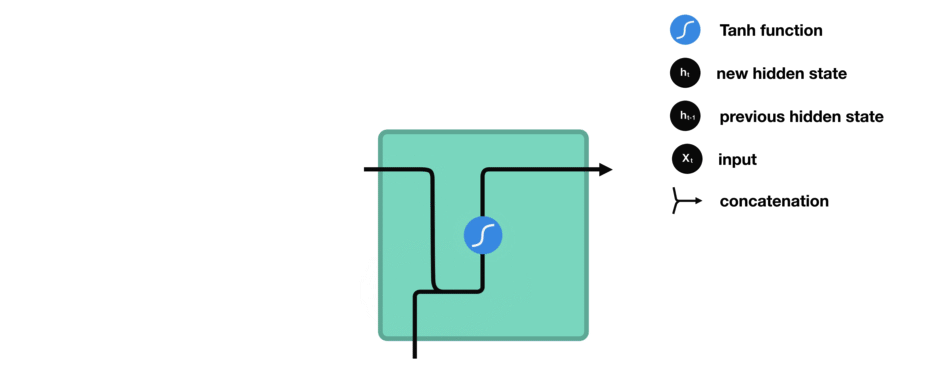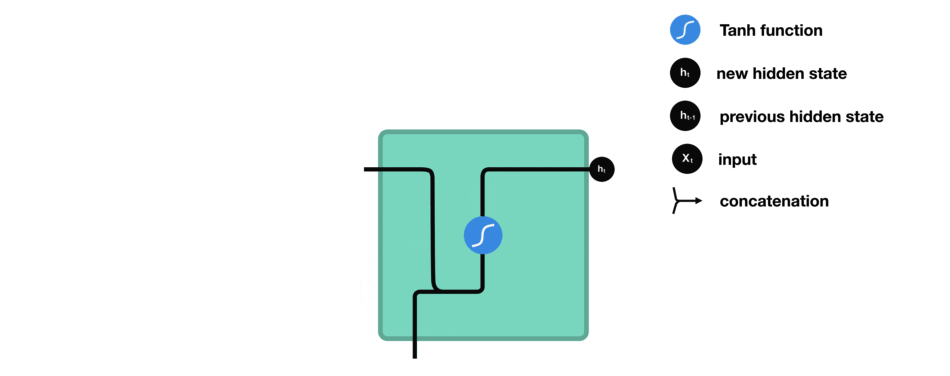
给定函数 $f:h',y=f(h,x)$,这里暂时忽略偏置bias,如图:

其中,
[1] - $x$ 为当前状态的输入
[2] - $h$ 表示接收到的上一个节点网络的输入
[3] - $y$ 为当前节点状态的输出
[4] - $h'$ 为传递到下一个节点网络的输出. $h$ 和 $h'$ 是具有相同维度的向量.
[5] - $\sigma$ 为激活函数,一般是 tanh 函数,以及会加一个偏置 $b$.
由图可知,输出 $h'$ 与 $x$ 和 $h$ 的值相关,而 $y$ 一般使用 $h'$ 送入到一个线性层(如,这里是维度映射),在使用 softmax 激活函数进行分类,得到输出值.
RNN 的标准结构如图:
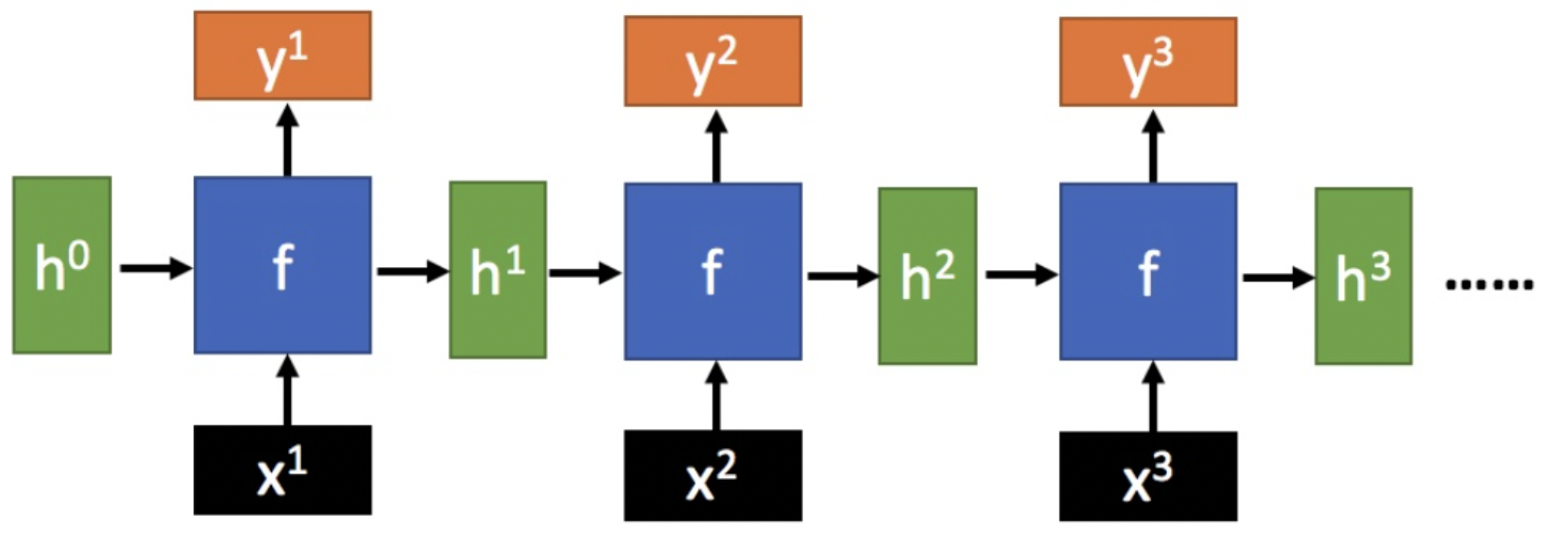
其中,函数 $f$ 是各个节点网络所共享的.
RNN中,将过去的输出和当前的输入链接到一起,通过tanh来控制两者的输出,它只考虑最近时刻的状态. 在RNN中有两个输入和一个输出.
单个RNN模块传递,动图:
RNN 还可细分为,单输入序列输出、序列输入单输出、序列输入序列输出(分等长和不等长)等一系列结构.
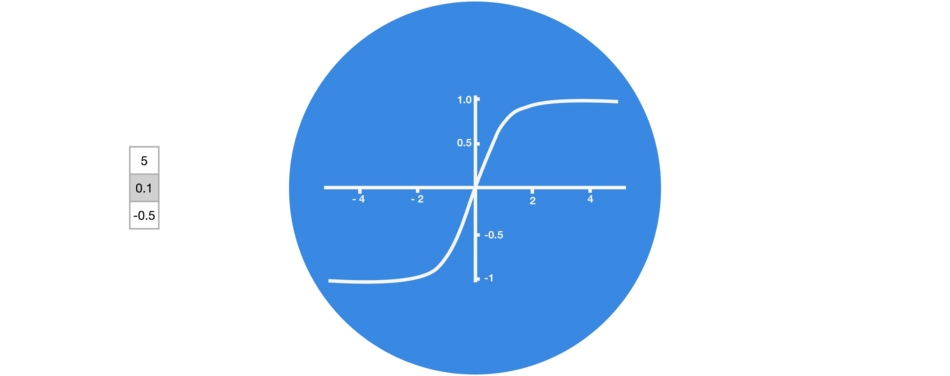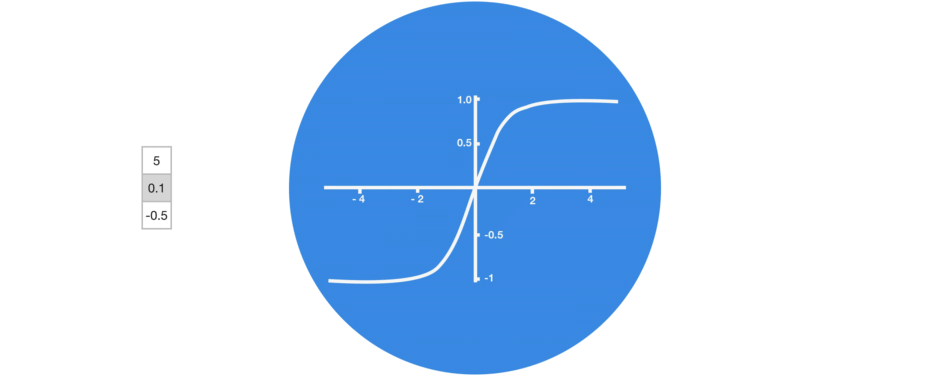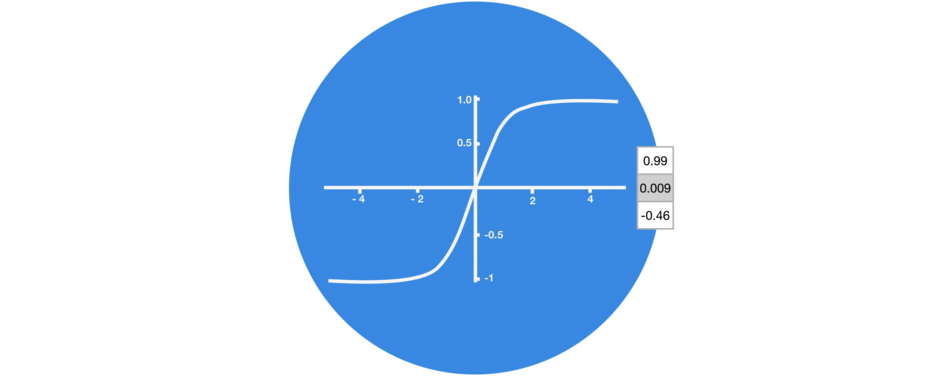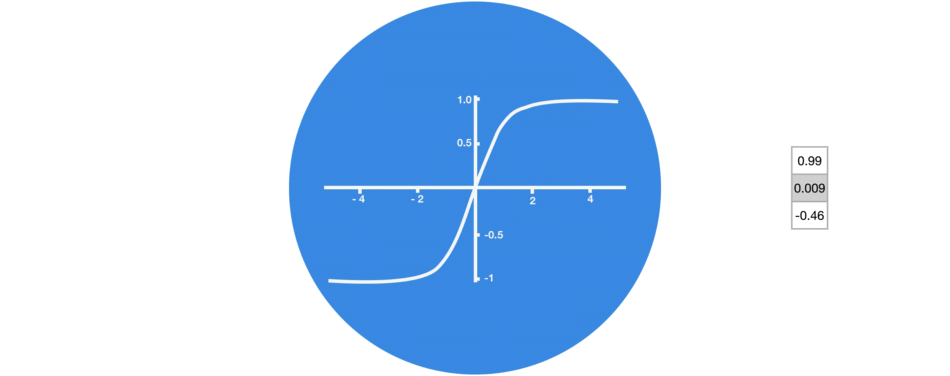
1.1.1. tanh 函数
tanh 激活函数用于调节在神经网络中传递的值,它会将输入值压缩到-1 到 1 之间.
1.2. RNN - PyTorch
Pytorch 模块 - torch.nn.RNNCell
一个 RNN Cell 模块可以表示为:
$$ h' = tanh(W_{ih}x + b_{ih} + W_{hh}h + b_{hh}) $$
其中,$h'$ 是输出的下一个隐状态.
函数定义为:
torch.nn.RNNCell(input_size, hidden_size, bias=True, nonlinearity='tanh')其中,
[1] - input_size - 输入 x 中的期望特征数
[2] - hidden_size - 隐状态 h 的特征数
[3] - bias - 若为 False,则不适用偏置权重 $b_{ih}$ 和 $b_{hh}$
[4] - nonlinearity - 采用的非线性函数,tanh 或 relu.
函数使用示例:
rnn = nn.RNNCell(10, 20)
input = torch.randn(6, 3, 10)
hx = torch.randn(3, 20)
output = []
for i in range(6):
hx = rnn(input[i], hx)
output.append(hx)1.3. Long-Term 依赖问题
RNN 的关键点之一,是可以用来连接先前的信息到当前的任务上,例如使用先前信息来推测对当前状态的理解.
两种场景:
[1] - 先前信息与预测信息之间的间隔非常小
此种场景,RNN 可以学会使用先前信息. 仅仅需要知道先前的信息来执行当前的任务.
例如,对于一个语言模型用来基于先前的词来预测下一个词,如果预测 "the clouds are in the sky" 最后的词,其并不需要任何其他的上下文. 因此下一个词很显然就应该是 sky.
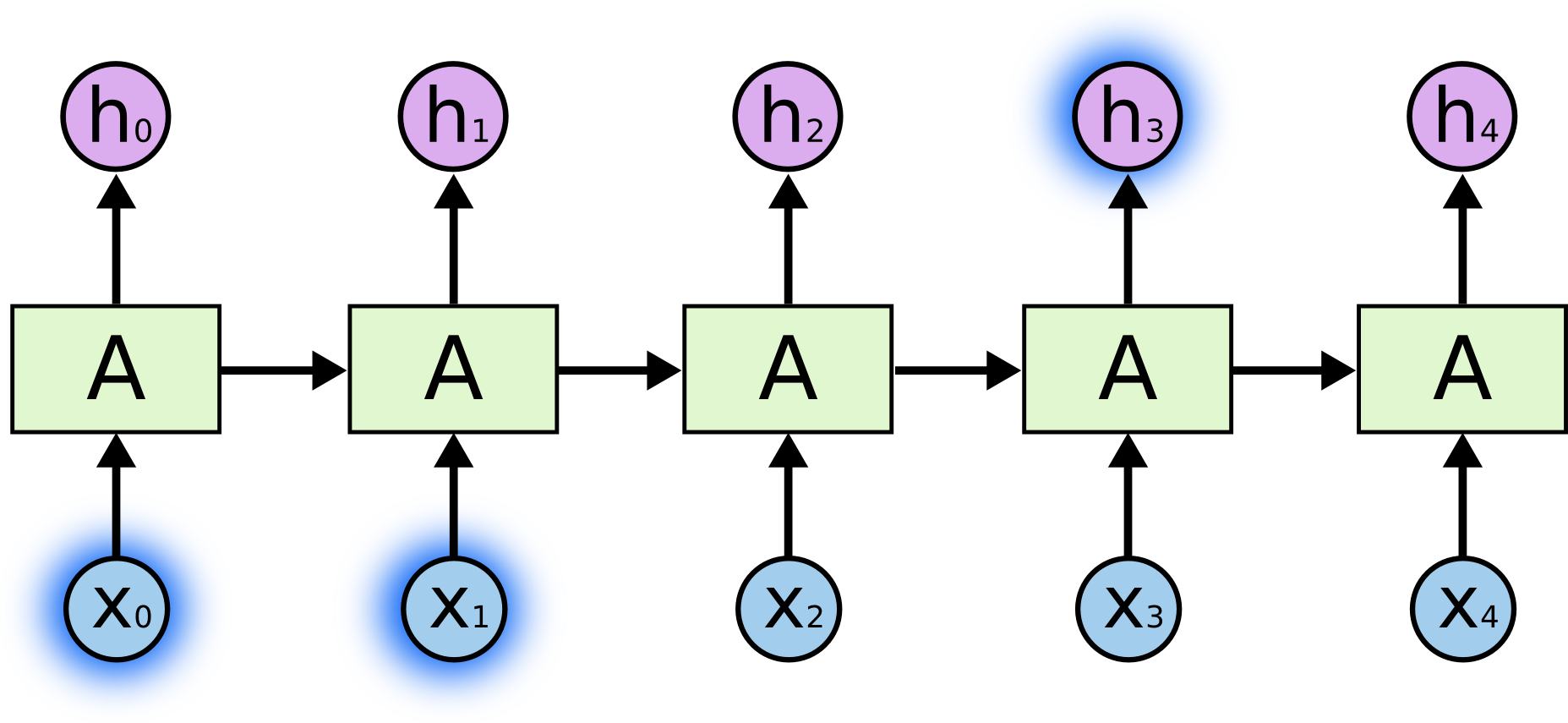
图:不太长的先前信息和位置间隔.
[2] - 更复杂的场景,先前信息和当前预测的位置间隔比较大
随着信息间隔不断增大时,RNN 会丧失学习到连接如此远的信息的能力.
例如,预测 "I grew up in France... I speak fluent French" 最后的词. 当前的信息建议下一个词可能是一种语言的名字,但是如果弄清楚是什么语言,需要先前提到的离当前位置很远的 France 的上下文信息.

图:较长的先前信息和位置间隔
RNN 存在梯度消失问题,通常可以采用两种解决办法:
[1] - 选取更好的激活函数,如ReLU函数.
[2] - 改变传播网络结构,如LSTM.
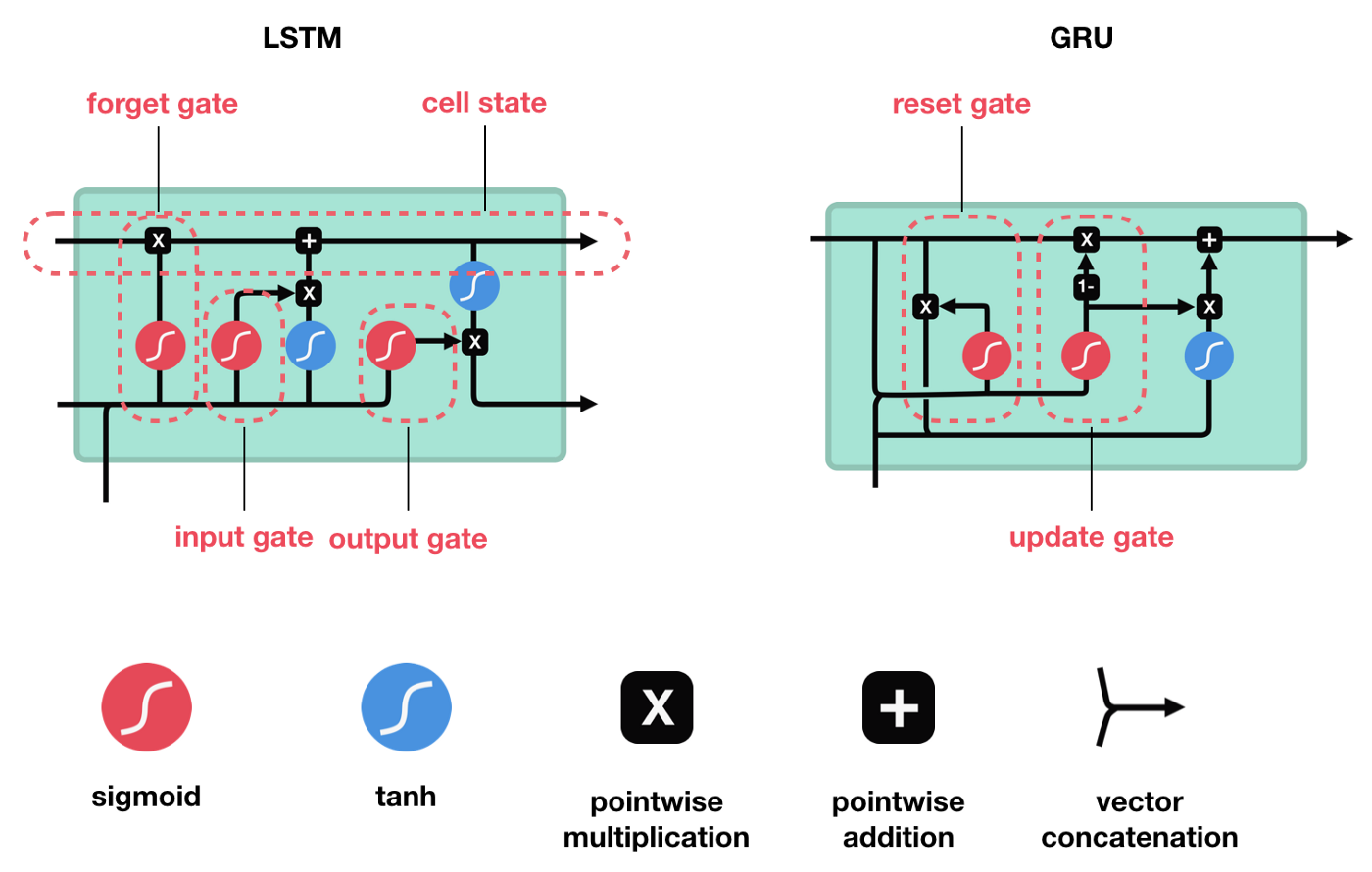
2. LSTM
LSTM,Long short-term memory,长短期记忆. 是 RNN 的一种改进,主要为了解决长序列训练过程中的梯度小时问题,使得 RNN 具有更好更强的记忆能力.
如图:
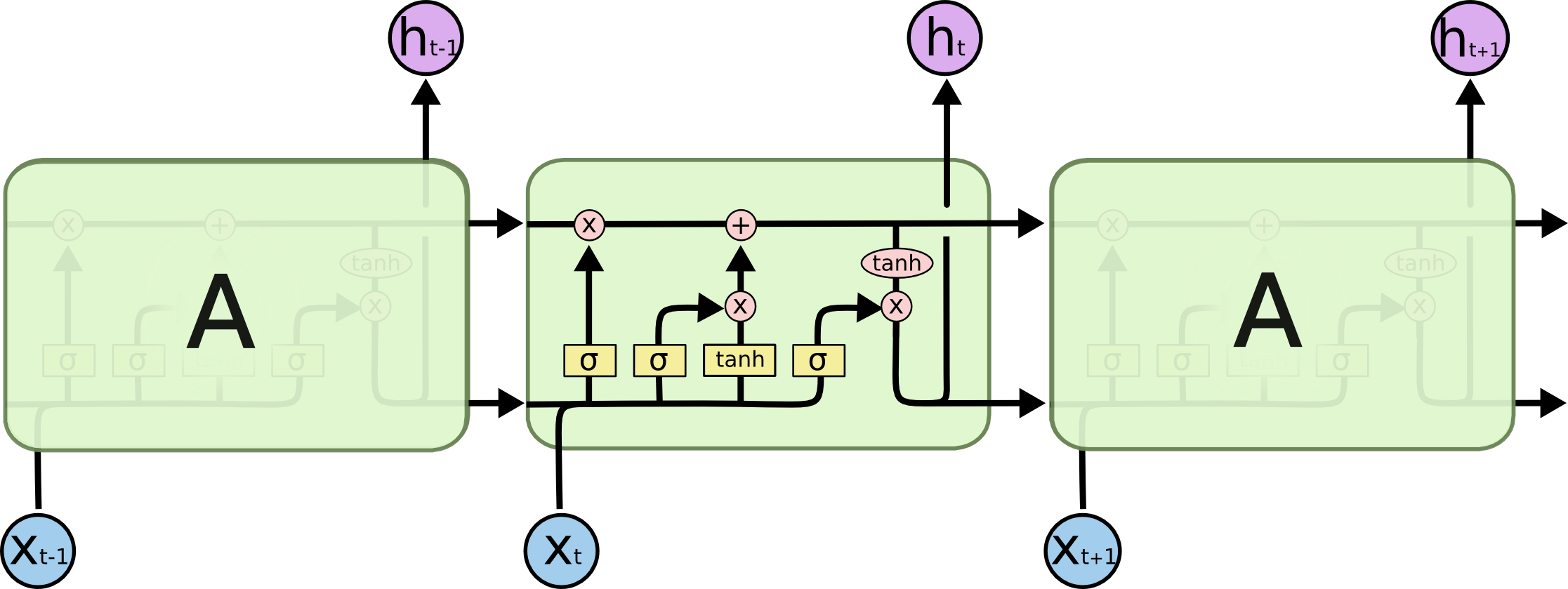
图:LSTM 结构,类似于 RNN,各重复模块包含四种交互.
LSTM 为了能记住长期的状态,在RNN的基础上增加了一路输入和一路输出,增加的这一路就是细胞状态,也就是图中最上面的一条通路.
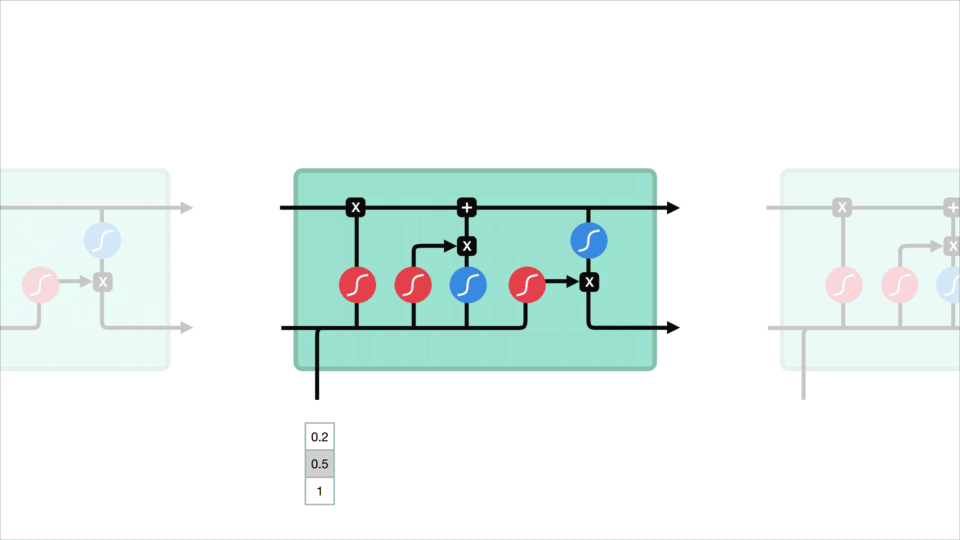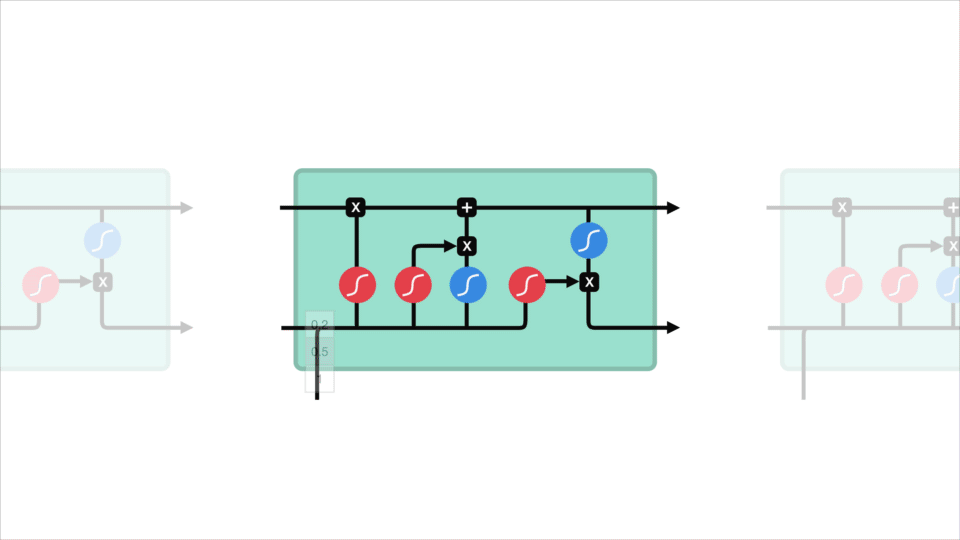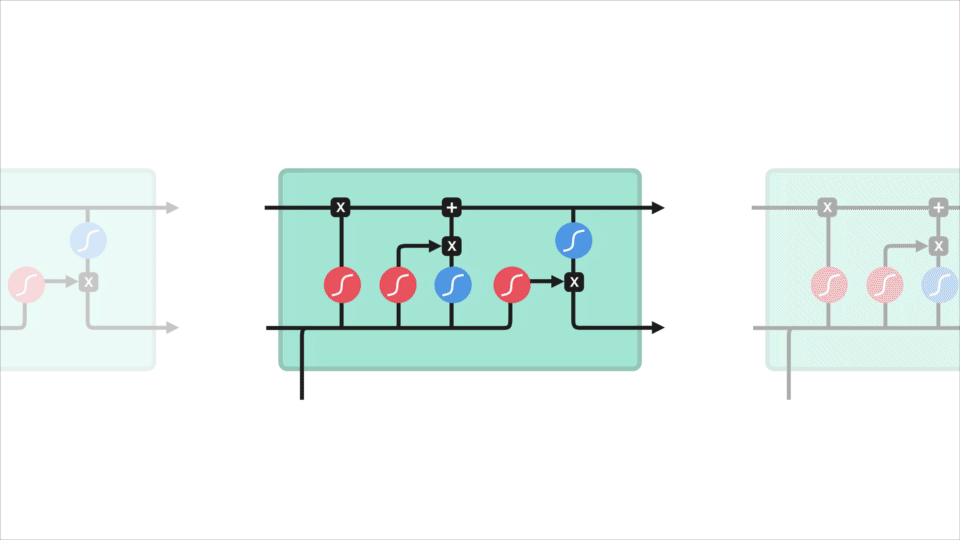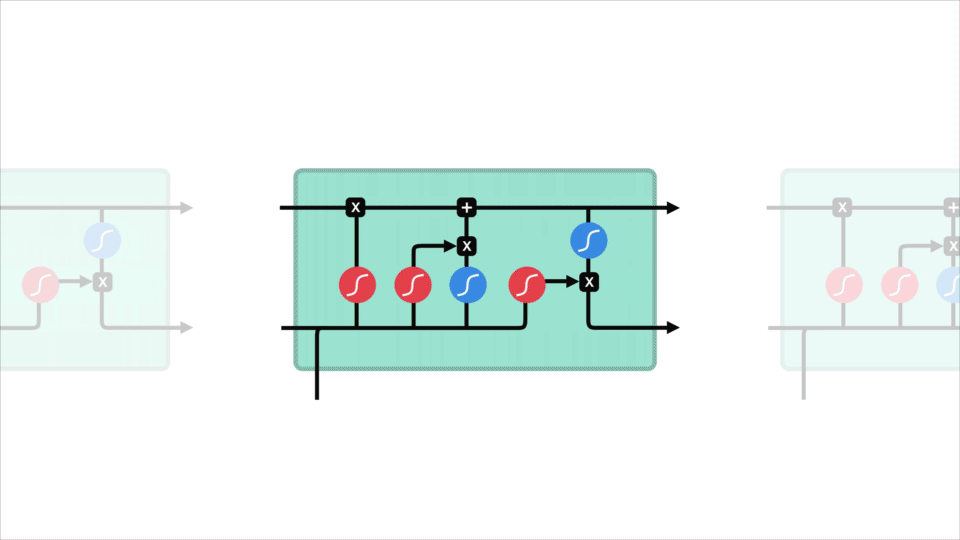
2.1. LSTM 图例
上图中,包含的图标例示有:

其中,
[1] - 黄色矩形框是学习到的神经网络层
[2] - 粉色圈代表按位 pointwise 操作,如向量和等
[3] - 每一条黑线传输着整个向量,从一个节点的输出到其他节点的输入
[4] - 合在一起的黑色线表示向量的连接
[5] - 分开的黑色线表示内容被复制,然后分发到不同的位置
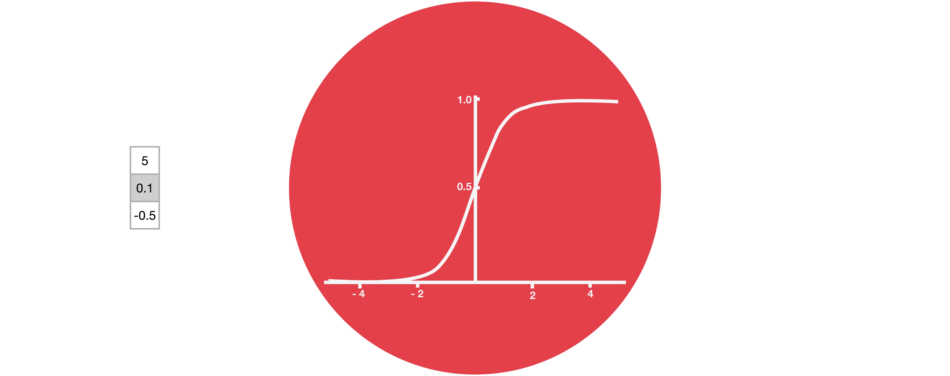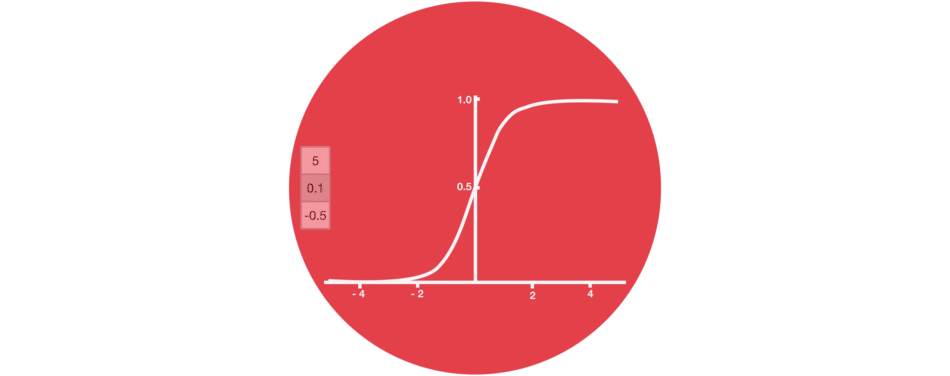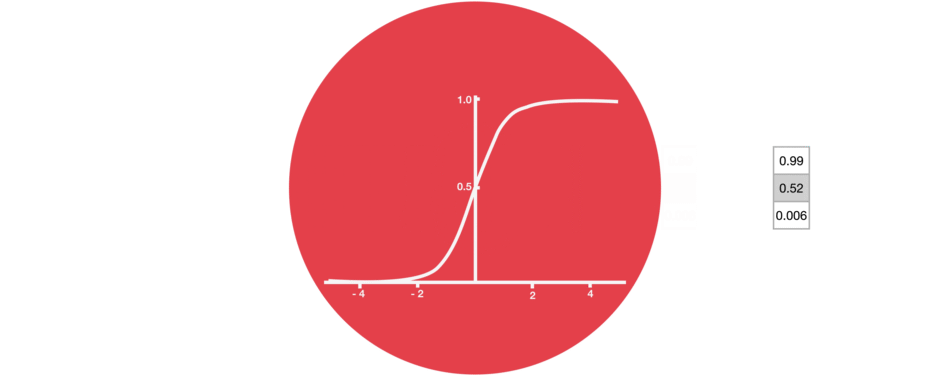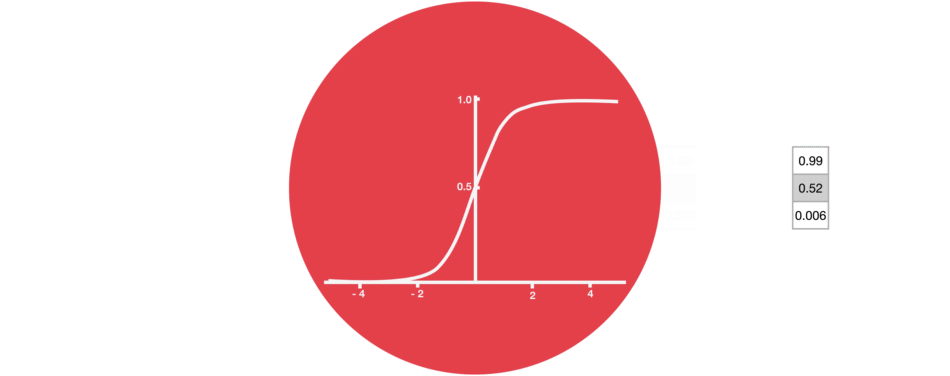
2.1.1. sigmoid 激活函数
sigmoid 激活函数类似于 tanh 激活函数,它会将数值控制在 0 到 1 之间,而不是-1 到 1. 其有助于更新或丢弃数据,因为任何数乘以 0 都是 0,这将导致数值消失或被遗忘;任何数字乘以 1 都是其本身,因此这个值不变或者保存. 网络可以知道哪些数据不重要,可以被遗忘,或者哪些数据需要保存.
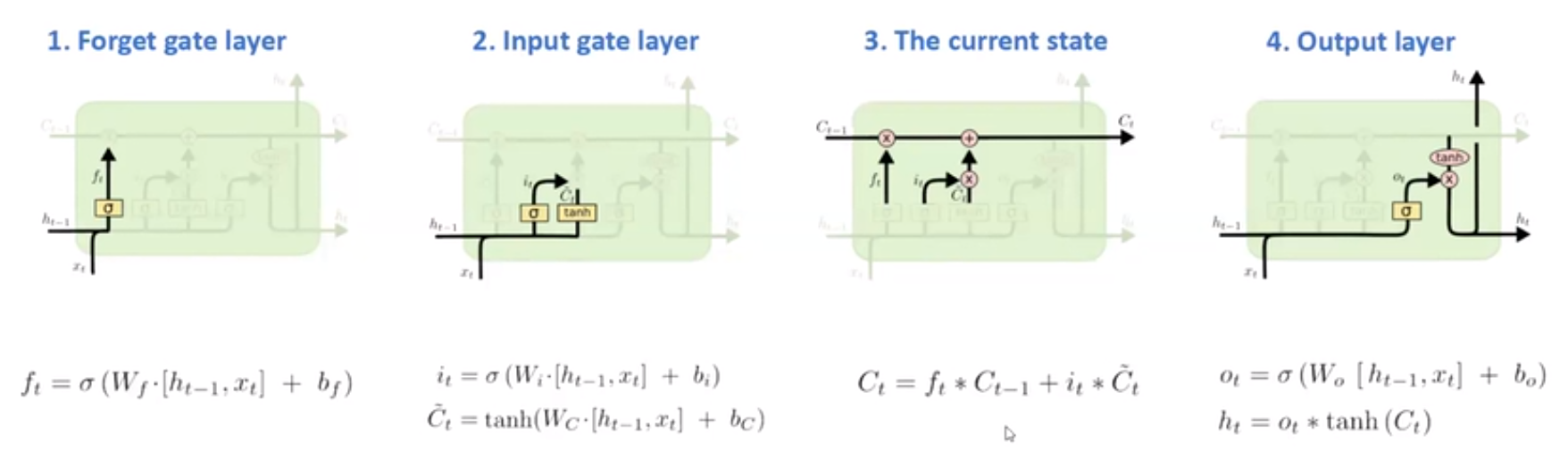
2.2. LSTM 核心思想
LSTM 每个神经网络模块处理流程如:
另一种图示:
LSTM 的核心是细胞状态(cell state),即下图中在图上方运行的黑色水平线.
细胞状态类似于传送带,直接在整个链上运行,只有一些少量的线性操作,信息在上面流传保持不变会很容易.

事实上整个LSTM分成了三个部分:
[1] - 哪些细胞状态应该被遗忘 - 遗忘门
[2] - 哪些新的状态应该被加入 - 输入门
[3] - 根据当前的状态和现在的输入,输出应该是什么 - 输出门
2.2.1. 遗忘门
遗忘门主要是对上一个阶段传来的输入,决定从细胞状态中丢弃(或遗忘)哪些信息. 遗忘门的位置和结构公式如图.
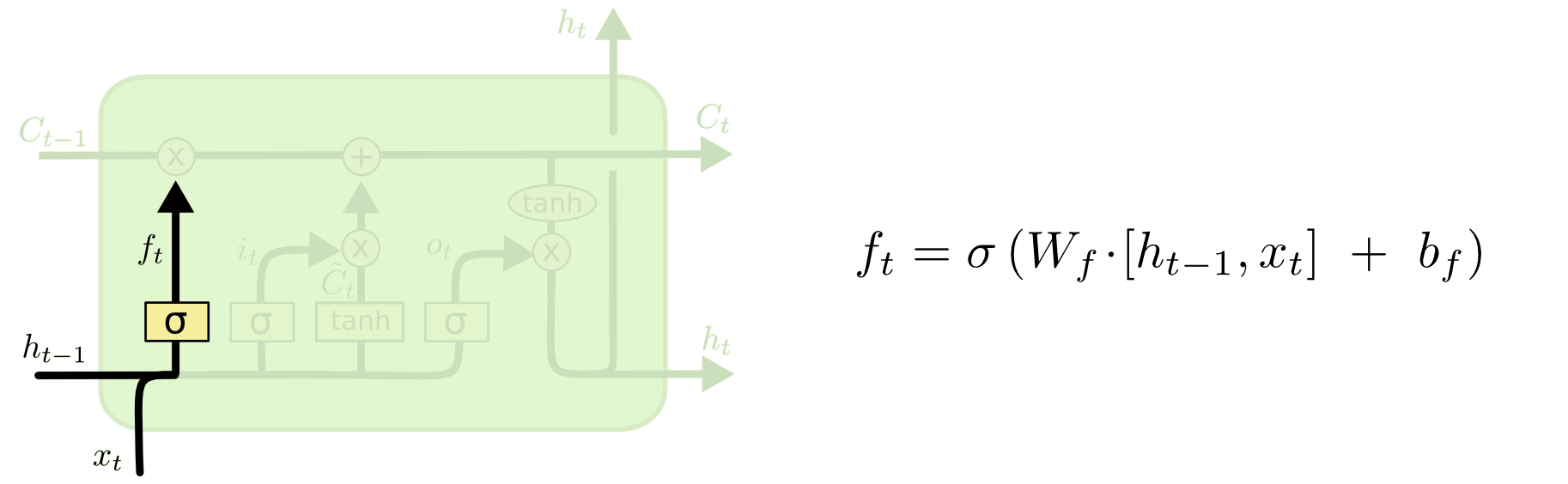
右边公式中,$f_t$ 是由 $h_{t-1}$ 和 $x_t$ 拼接向量乘以权重矩阵$W_f$ 后,再通过一个 sigmoid 激活函数,将值转换为 0 和 1 之间的数值.
动图版:

2.2.2. 输入门
输入门主要是将输入有选择性地进行记忆,确定什么样的新信息被存放在细胞状态中,输入门的位置和结构公式如图.
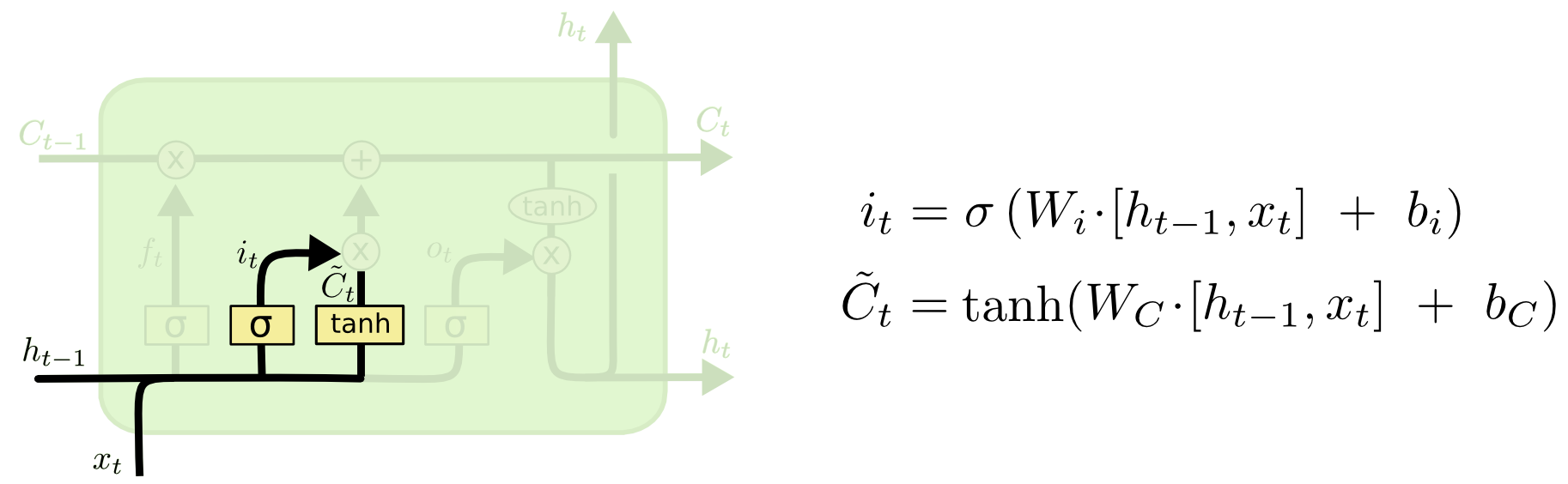
动图版:
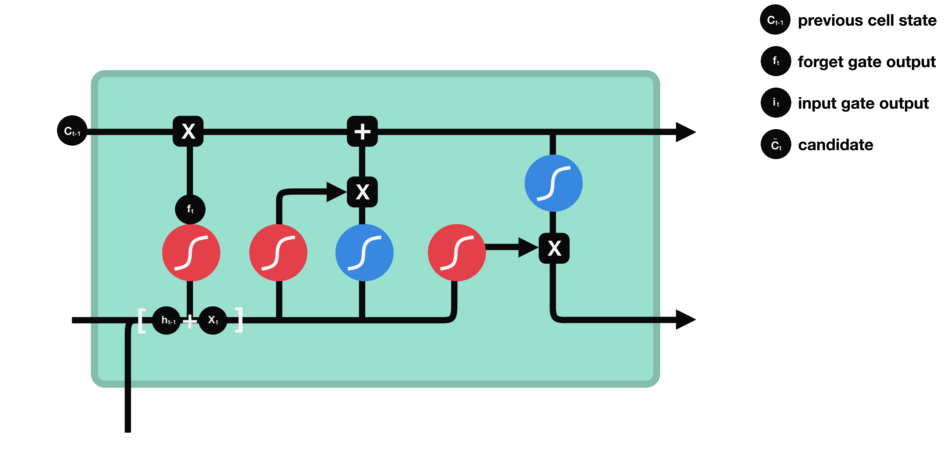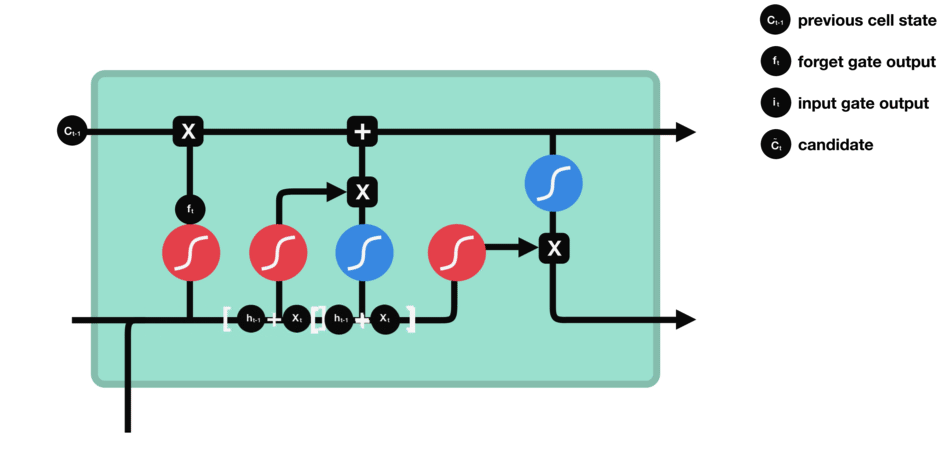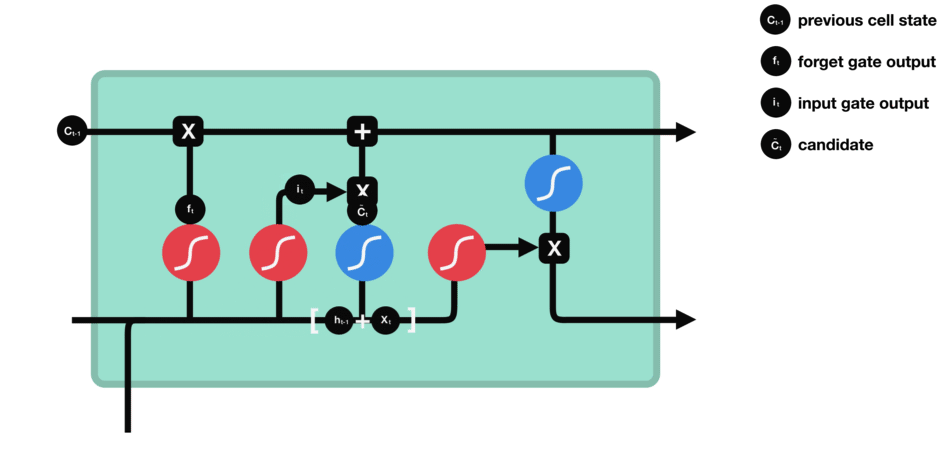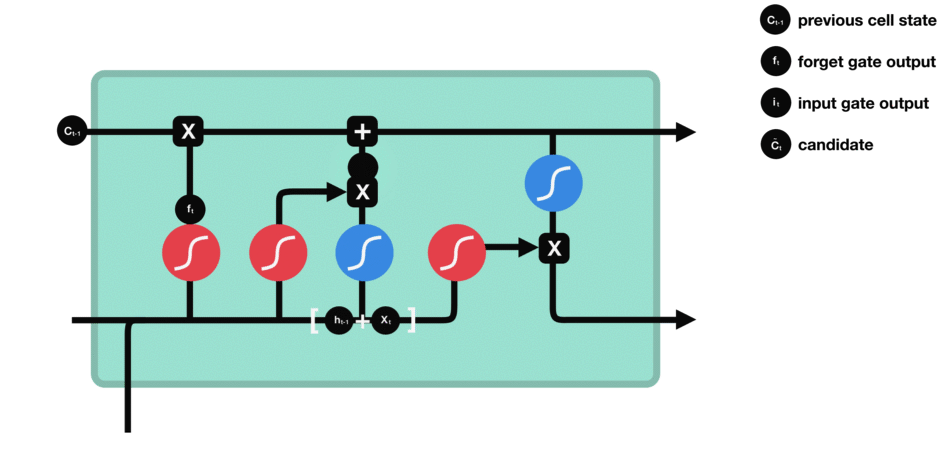
2.2.3. 当前状态
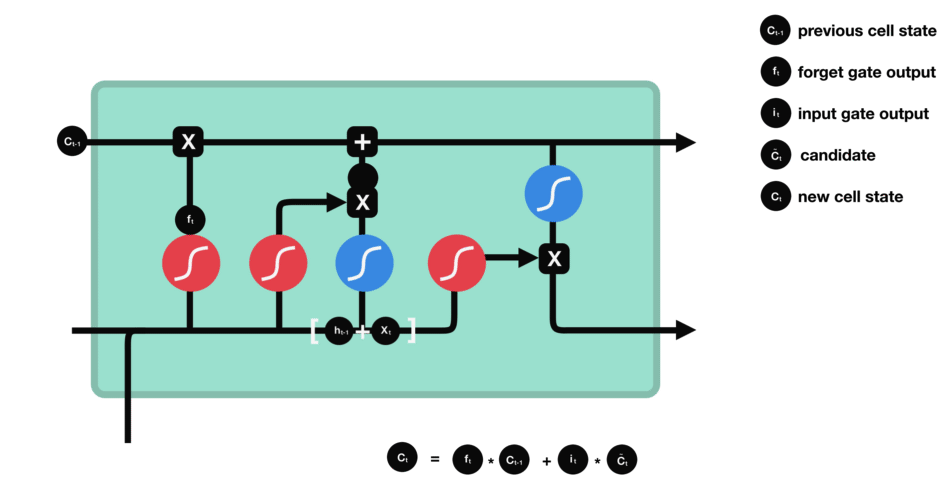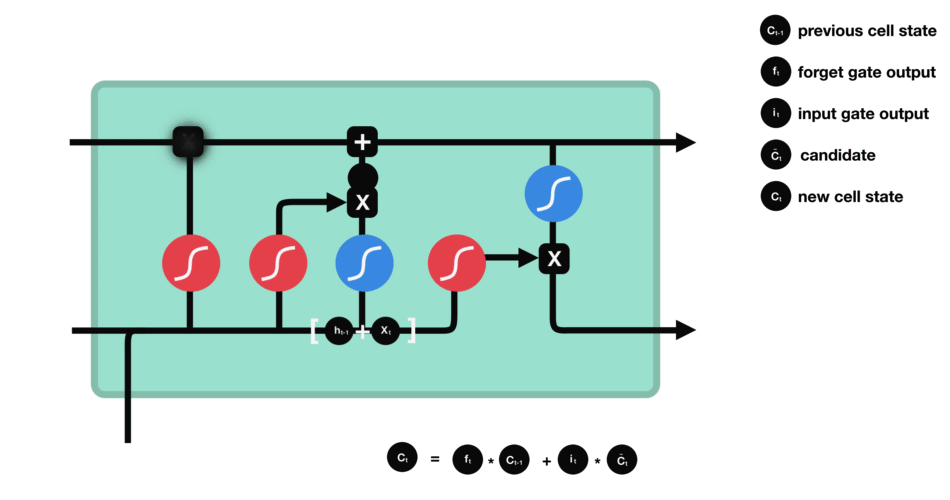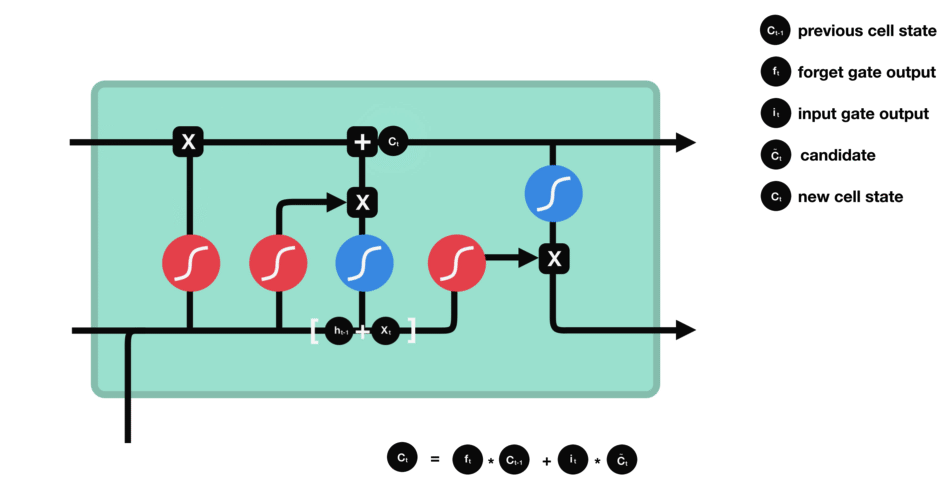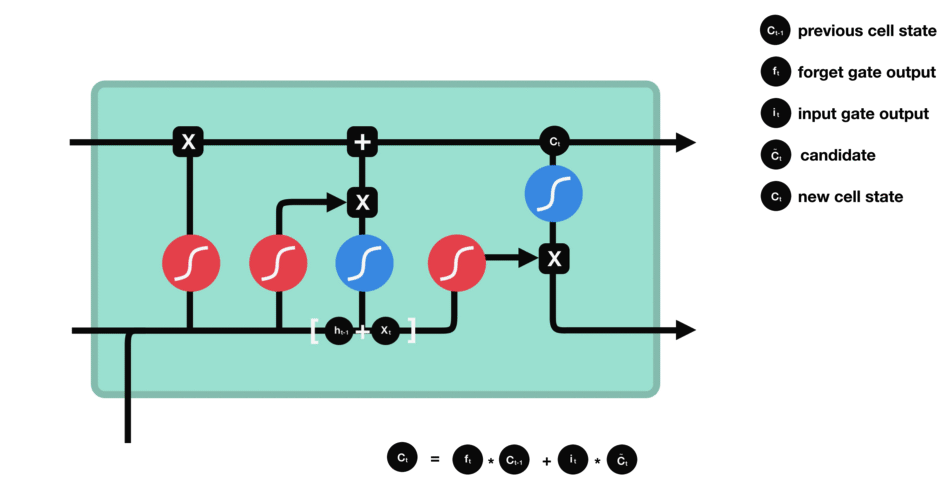
根据遗忘门的输出 $f_t$、上一层记忆细胞状态值 $C_{t-1}$、输入门的输出 $i_t$ 和 $\tilde{C}_{t}$,共同决定当前细胞状态,如图:
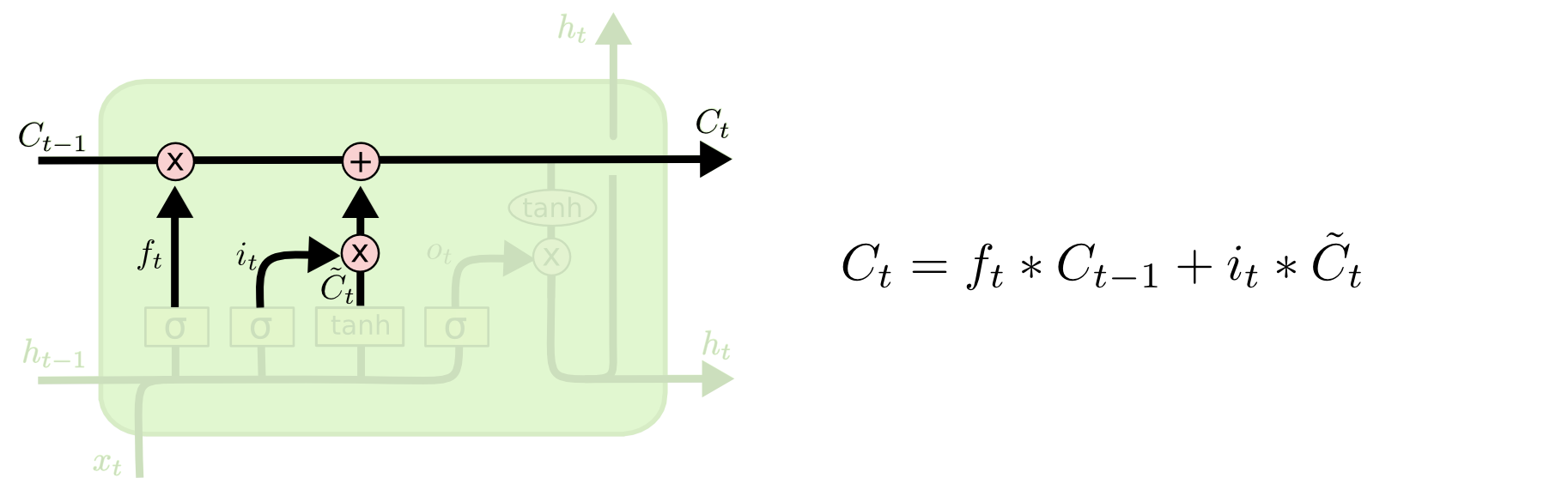
当前状态 $C_t$ 的更新,是将旧状态$C_{t-1}$ 与 $f_t$ 相乘,以丢弃需要被丢弃的信息;并加上 $i_t * \tilde{C}_{t}$.
动图版:
2.2.4. 输出门
输出门决定了当前状态的哪些信息会被输出.
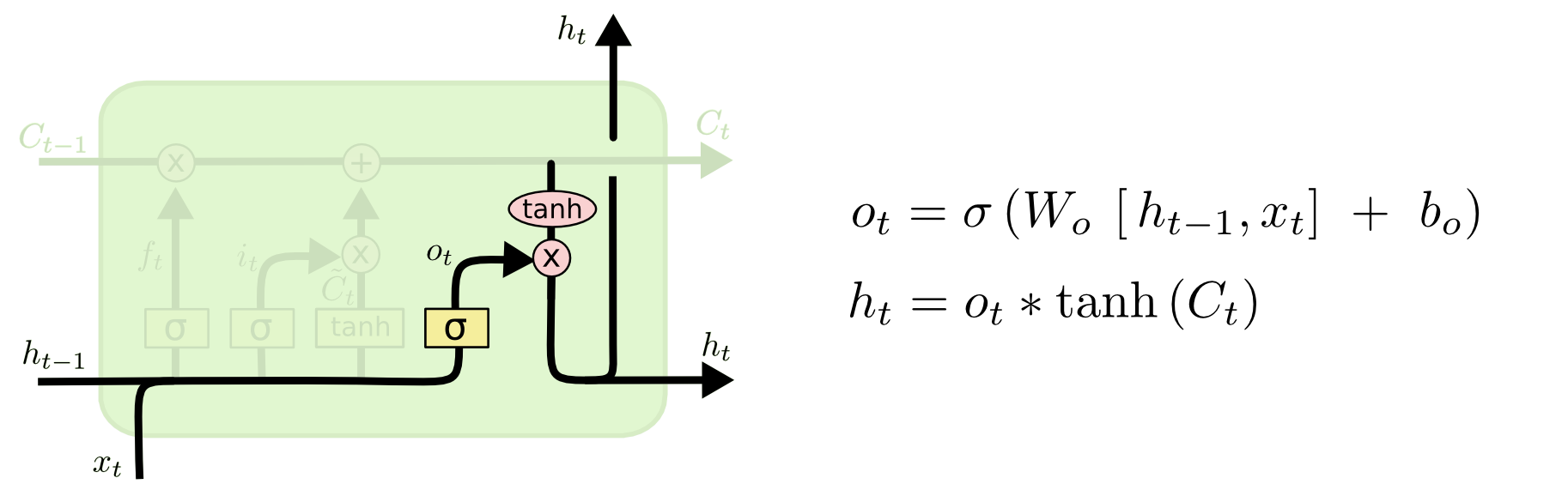
首先通过一个 sigmoid 激活函数做门控制,以确定当前细胞状态的哪些信息要被输出;
然后,通过 tanh 函数处理(其输出值在 -1 到 1 之间),再与 sigmoid 函数的输出相乘,最终实现仅输出确定要输出的信息.
动图版:
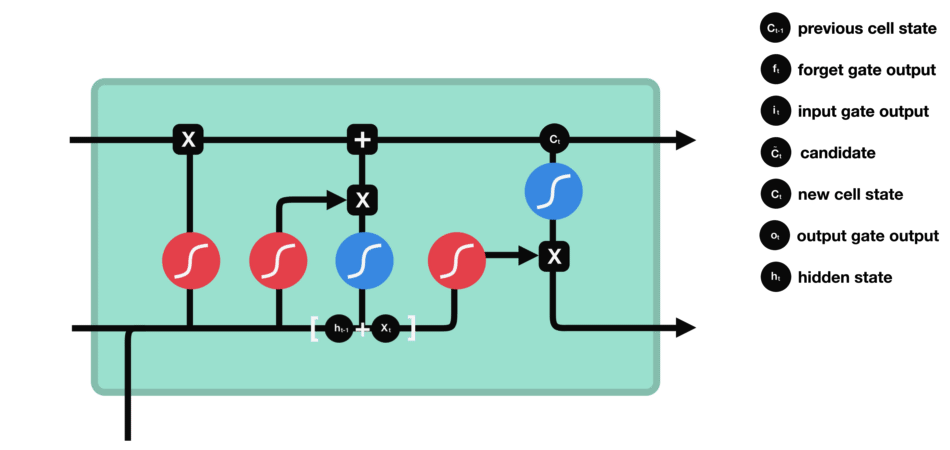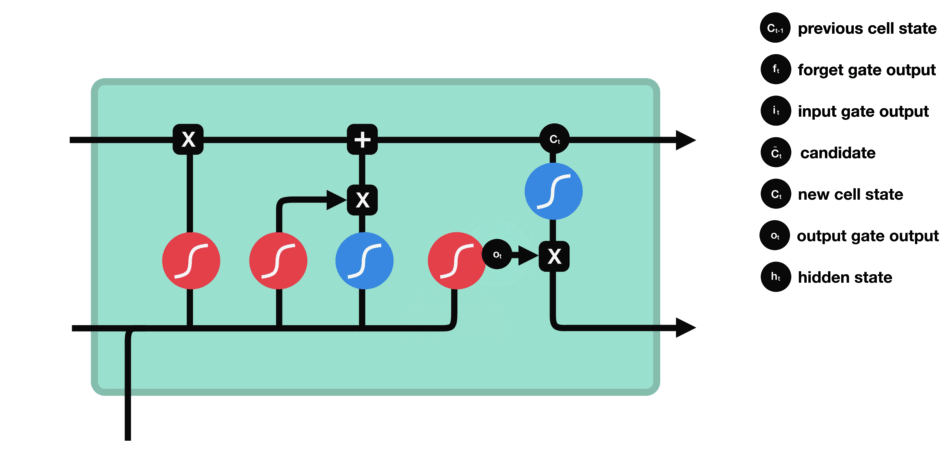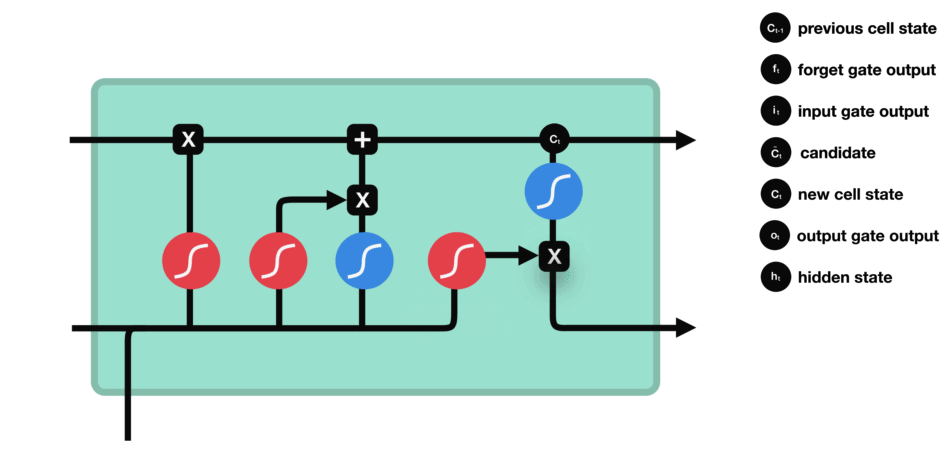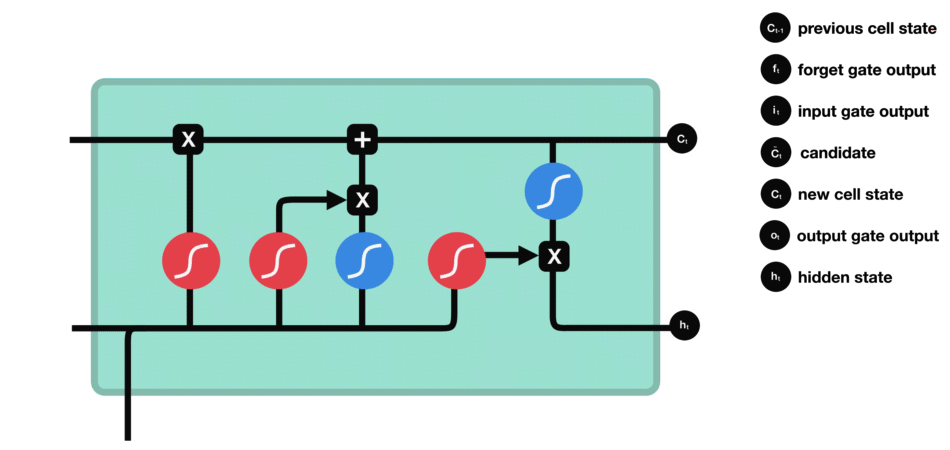
2.3. LSTM - PyTorch
Pytorch 模块 - torch.nn.LSTMCell
一个 LSTM 细胞模块的数学表达式如:
$$ i = \sigma (W_{ii} x + b_{ii} + W_{hi}h + b_{hi}) $$
$$ f = \sigma (W_{if} x + b_{if} + W_{hf} h + b_{hf}) $$
$$ g = tanh(W_{io} x + b_{io} + W_{ho} h + b_{ho}) $$
$$ c' = f * c + i*g $$
$$ h' = o * tanh(c') $$
其中,$\sigma$ 是 sigmoid 激活函数,$*$ 是 Hadamard 乘积.
函数定义如:
torch.nn.LSTMCell(input_size, hidden_size, bias=True)函数使用示例如:
rnn = nn.LSTMCell(10, 20) # (input_size, hidden_size)
#
input = torch.randn(2, 3, 10) # (time_steps, batch, input_size)
hx = torch.randn(3, 20) # (batch, hidden_size)
cx = torch.randn(3, 20)
#
output = []
for i in range(input.size()[0]):
hx, cx = rnn(input[i], (hx, cx))
output.append(hx)
output = torch.stack(output, dim=0)2.4. LSTM 伪代码
如:
def LSTMCELL(prev_ct,prev_ht,input):
#1.连接上一个细胞状态和当前的输入
combine = prev_ht + input
#2.遗忘门处理,删除不相关数据
ft = forget_layer(combine)
#3.创建候选层,候选项保存要添加到细胞状态的可能值
candidate = candidate_layer(combine)
#4.输入层处理,决定应该添加到新的细胞状态的候选数据
it = input_layer(combine)
#5.计算新的细胞状态
ct = prev_ct * ft + candidate * it
#6.计算输出
ot = output_layer(combine)
#7.计算新的隐藏状态,将输出和新的细胞状态的对应元素乘积
ht = ot * tanh(ct)
return ht,ct
ct = [0,0,0]
ht = [0,0,0]
for input in inputs:
ct,ht = LSTMCELL(ct,ht,input)3. 材料
[1] - Illustrated Guide to Recurrent Neural Networks - 2018.09.20 强烈推荐
[2] - Understanding LSTM Networks - 2015.08.27 强烈推荐
[3] - Illustrated Guide to LSTM’s and GRU’s: A step by step explanation - 2018.09.25 强烈推荐
[4] - 一步一步,看图理解长短期记忆网络与门控循环网络 - 2018.10.13 - 对应中文翻译版
[5] - RNN梯度消失和爆炸的原因 - 2017.08.24
[6] - LSTM如何解决梯度消失问题 - 2017.08.24
[7] - Why LSTMs Stop Your Gradients From Vanishing: A View from the Backwards Pass - 2017.11.15