1. 循环神经网络 RNN
生活中,经常会遇到或者使用一些时序信号,比如自然语言语音,自然语言文本。以自然语言文本为例,完整的一句话中各个字符之间是有时序关系的,各个字符顺序的调换有可能变成语义完全不同的两句话,就像下面这个句子:
- 张三非常生气,冲动之下打了李四
- 李四非常生气,冲动之下打了张三
从以上这个例子可以看出,名字的调换造成了完全不同的后果,可见自然语言的时序性非常重要。那么如何对这种带有时序关系的数据进行建模呢?本节将来介绍一个非常经典的循环神经网络RNN.
1.1. 循环神经网络RNN是什么
循环神经网络(Recurrent Neural Network,RNN)是一个非常经典的面向序列的模型,可以对自然语言句子或是其他时序信号进行建模。进一步讲,它只有一个物理RNN单元,但是这个RNN单元可以按照时间步骤进行展开,在每个时间步骤接收当前时间步的输入和上一个时间步的输出,然后进行计算得出本时间步的输出。
下面举个例子来讨论一下,如图1所示,假设现在有这样一句话:"我爱人工智能",经过分词之后变成"我,爱,人工,智能"这4个单词,RNN会根据这4个单词的时序关系进行处理,在第1个时刻处理单词"我",第2个时刻处理单词"爱",依次类推。
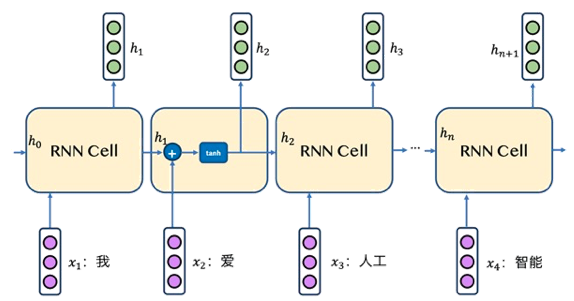
图1 RNN网络结构图
从图1上可以看出,RNN在每个时刻$t$均会接收两个输入,一个是当前时刻的单词$x_t$,一个是来自上一个时刻的输出$h_{t-1}$,经过计算后产生当前时刻的输出$h_t$。例如在第2个时刻,它的输入是"爱"和$h_1$,它的输出是$h_2$;在第3个时刻,它的输入是"人工"和$h_2$, 输出是$h_3$,依次类推,直到处理完最后一个单词。
总结一下,RNN会从左到右逐词阅读这个句子,并不断调用一个相同的RNN Cell来处理时序信息,每阅读一个单词,RNN首先将本时刻$t$的单词$x_t$和这个模型内部记忆的状态向量$h_{t-1}$融合起来,形成一个带有最新记忆的状态向量$h_t$。
Tip:当RNN读完最后一个单词后,那RNN就已经读完了整个句子,一般可认为最后一个单词输出的状态向量能够表示整个句子的语义信息,即它是整个句子的语义向量,这是一个常用的想法。
1.2. RNN的公式推导
上面从宏观上讨论了RNN的工作原理,那么RNN内部是怎么计算的呢,即在每个时刻如何根据输入计算得到输出的呢?
前边谈到,在每个时刻$t$,RNN会接收当前时刻的输入单词$x_t$和上一个时刻的输出状态$h_{t-1}$,然后计算得到当前时刻的输出$h_t$,在RNN中这个实现机制比较简单:
$$h_t = tanh(Wx_t + Vh_{t-1}+b)$$
即在时刻$t$,RNN单元会对两个输入$x_t$和$h_{t-1}$进行线性变换,然后将结果使用$tanh$激活函数进行处理,得到当前时刻$t$的输出$h_t$。
这里需要注意一下,tanh函数是一个值域(-1,1)的函数,如图2所示,可以长期维持内部记忆在一个固定的数值范围内,防止因多次迭代更新导致的数值爆炸,同时,tanh的导数是一个平滑的函数,让神经网络的训练变得更加简单。
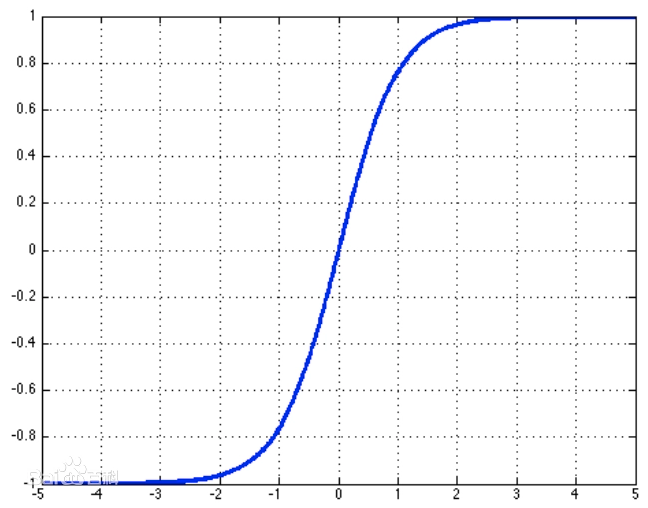
图2 tanh函数图像
1.3. RNN的缺陷
上边貌似提出了一个非常优秀的RNN模型建模时序数据,但在真实的任务训练过程中,存在一个明显的缺陷,那就是当阅读很长的序列时,网络内部的信息会逐渐变得越来越复杂,以至于超过网络的记忆能力,使得最终的输出信息变得混乱无用。例如下面这句话:
我觉得这家餐馆的菜品很不错,烤鸭非常正宗,包子也不错,酱牛肉很有嚼劲,但是服务员态度太恶劣了,我们在门口等了50分钟都没有能成功进去,好不容易进去了,桌子也半天没人打扫,整个环境非常吵闹,我的孩子都被吓哭了,我下次不会带朋友来。
显然这是个比较长的文本序列,当RNN读到这句话时,有可能前半句还能准确地表达这句话的语义,但是读到后半句可能就完全混乱了,不能准确地表达这句话的语义信息,即不能保持长期的信息之间的依赖。
因此,针对这个问题,后续出现了很多基于RNN的改进模型,比如LSTM,GRU等等。
1.4. RNN的几种常见模式
循环神经网络可以应用到很多不同类型的任务中,根据这些任务的的特点可以分为以下几种模式:
- 序列到类别模式
- 同步的序列到序列模式
- 异步的序列到序列模式
下面进一步聊聊这几种模式,以便说明RNN适合应用在什么样的任务上。
1.4.1. 序列到类别模式
1.1. 中讲到,在RNN读完一个句子的最后一个单词后,该单词对应的输出便可以看做能够代表整个句子的语义向量,根据这个语义向量可以进一步计算一些任务,比如文本分类,假设通过这个语义向量能够将"我爱人工智能"这句话划分为"科技"类别,那这就是一个完整的序列到类别模式的应用。
序列到类别模式是将一串输入映射为一个向量,如图3所示。在这种模式下,模型的输入是一个序列$=[x_1,x_2,x_3,..,x_n]$,最终使用的模型输出是一个向量$h_n$(图3中输出的绿色向量),可以根据这个输出向量$h_n$进一步做一些任务。
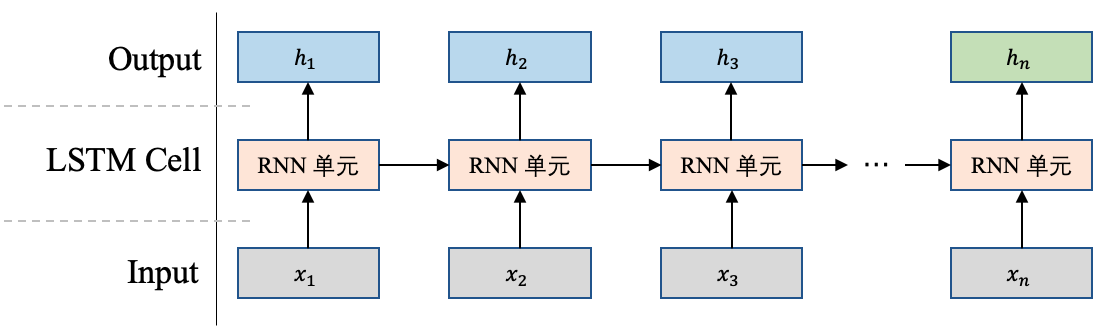
图3 序列到类别模式图
除了将最后时刻的状态作为整个序列的语义向量之外,还可以对整个序列的所有状态进行平均,并用这个平均状态作为整个序列的语义向量,如图4所示。
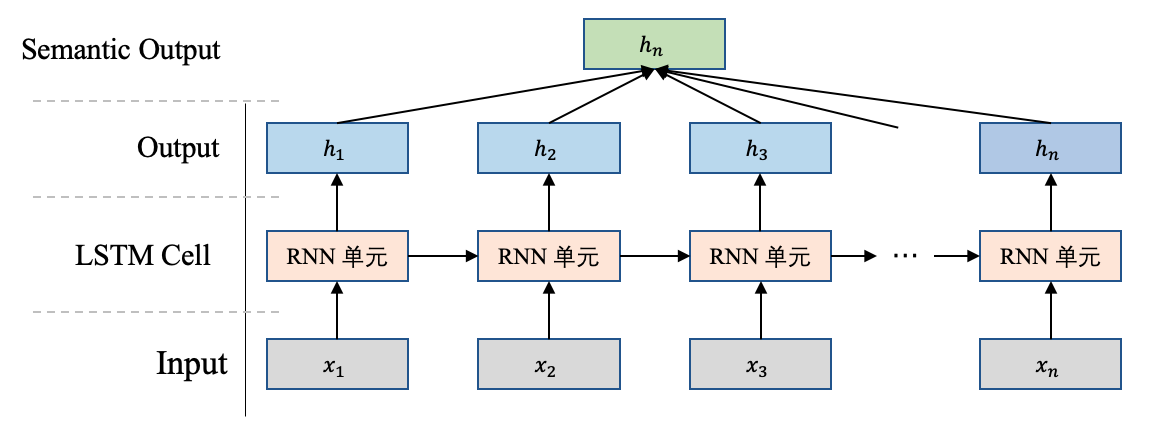
图4 序列到类别模式图
1.4.2. 同步的序列到序列模式
同步的序列到序列模式是将一串输入$x=[x_1,x_2,..,x_n]$映射为一串输出向量$h=[h_1,h_2,...,h_n]$,并且每个输入和输出是一一对应的,如图5所示。同步的序列到序列模式主要用于 序列标注(Sequence Labeling) 任务上。
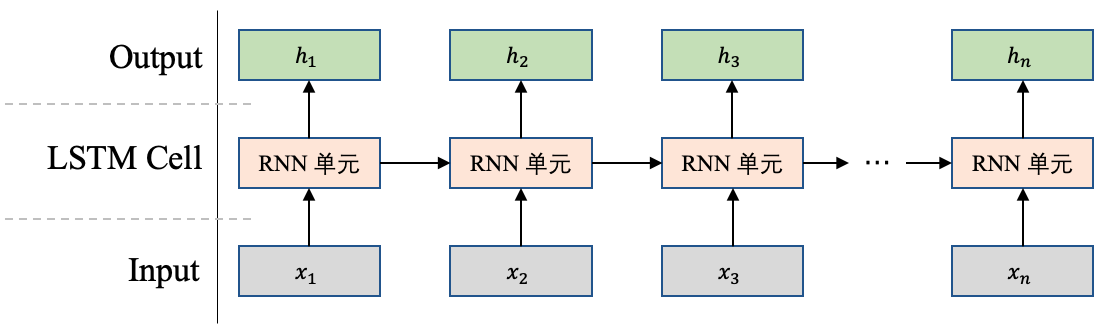
图5 同步的序列到序列模式
以 词性标注(Part-of-Speech Tagging) 为例,该任务期望得到一个句子中每个单词的词性,因此它的输入就是一个句子中的单词,它的输出就是每个单词对应的词性。
1.4.3. 异步的序列到序列模式
异步的序列到序列模式也成为编码器-解码器模型(encoder-decoder),它同样是将一串输入映射$x=[x_1,x_2,..,x_n]$为一串输出向量$h=[h_1,h_2,...,h_m]$,但是输入序列和输出序列不要求有严格的一一对应关系,也不需要保持相同的长度,如图6所示。例如在机器翻译-英译汉任务中,输入为中文的单词序列,输出为英文的单词序列。
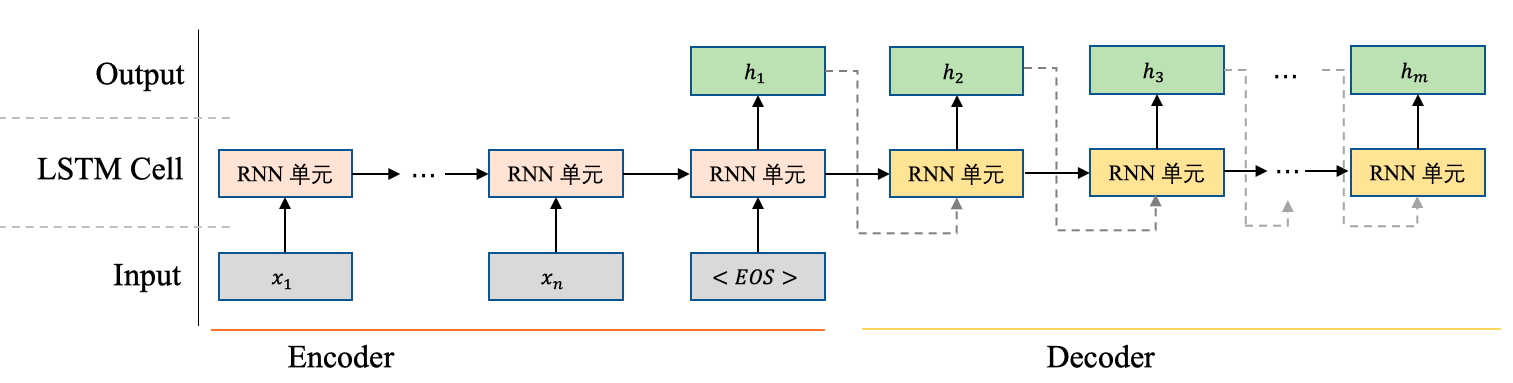
图6 异步的序列到序列模式
在这个模式下,一般先将输入序列传到一个RNN(encoder,图6橙色单元)中,然后再将encoder的输出向量作为另一个RNN(解码器,图6黄色单元)的输入,由解码器进行序列解码。在解码器的解码过程中,往往会将前一个时刻输出的单词作为当前时刻输入的单词,采用这种自回归的方式进行解码。
2. 长短时记忆网络 LSTM
长短时记忆网络(Long Short Term Memory,简称LSTM)是循环神经网络的一种,它为了解决RNN自身的缺陷,向RNN单元中引入了门机制进行改善。
2.1. LSTM的设计思路
在循环神经网络RNN中谈到,RNN不太能够保持长期的依赖,过长的信息容易导致RNN单元内部状态的混乱,导致无法准确的表达一句话的语义。
我觉得这家餐馆的菜品很不错,烤鸭非常正宗,包子也不错,酱牛肉很有嚼劲,但是服务员态度太恶劣了,我们在门口等了50分钟都没有能成功进去,好不容易进去了,桌子也半天没人打扫,整个环境非常吵闹,我的孩子都被吓哭了,我下次不会带朋友来。
我们来看上面这句话,这句话很长,但是人读这句话的时候会记住几个关键的信息,比如烤鸭正宗,牛肉有嚼劲,服务员态度恶劣,环境吵闹等信息;但同时也会忽略掉一些内容,比如"我觉得","好不容易"等不重要的内容。这说明有选择的记忆比记忆整句话更加容易,LSTM正是受这一点的启发而设计的。
它通过引入门机制来控制LSTM单元需要记忆哪些信息,遗忘哪些信息,从而保持更长的信息依赖,更加轻松地表达整个句子语义。
2.2. LSTM是怎样工作的
同RNN一样,LSTM也是一种循环神经网络,他也是只有一个物理LSTM单元,按照时间步骤展开处理时序数据,如图1所示。
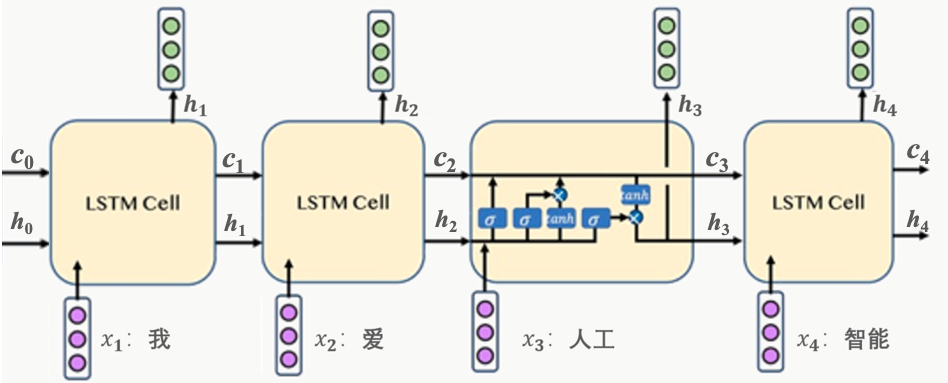
图1 LSTM展开图
假设现在有这样一句话:我爱人工智能,分词之后是:[我,爱,人工,智能]。LSTM单元在第1个时刻会处理"我"这个单词,在第2个时刻会处理"爱"这个单词,依次类推。
再来看下每个时刻LSTM单元的输入和输出,显然在每个时刻LSTM会接收3种数据,同时输出2种数据。在时刻$t$LSTM单元的输入是:单词$x_t$ (词向量),上一个时刻的状态向量$c_{t-1}$ (上边的横线) 和 上一个时刻的隐状态向量$h_{t-1}$ (下边的横线);LSTM单元的输出是: 当前时刻的状态向量$c_{t}$和 当前时刻的隐状态向量$h_{t}$ 。
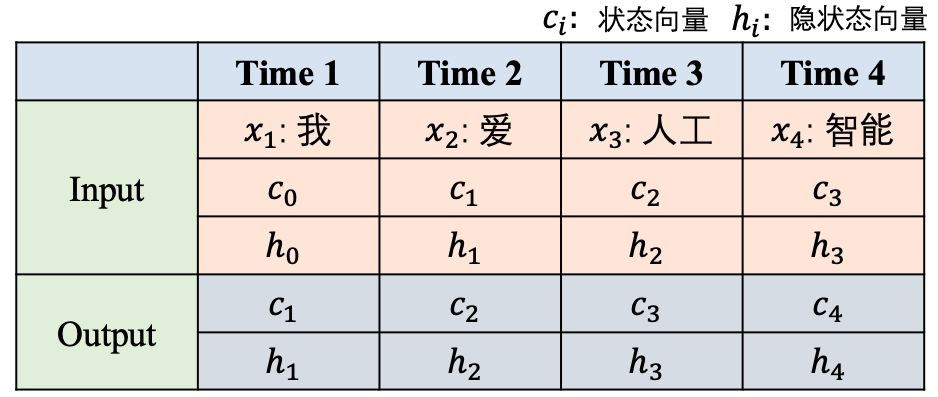
图2 LSTM数据处理样例
图2展示了LSTM处理"我爱人工智能"这句话的过程,可以看到在第1个时刻,模型输入了单词"我", 初始的状态向量$c_0$和初始的隐状态向量$h_0$,模型输出的是状态向量$c_1$和隐状态向量$h_1$;在第2个时刻,模型输入了单词"爱",第1个时刻的状态向量 $c_1$和$h_1$,模型的输出是状态向量$c_2$和隐状态向量$h_2$,其他的时刻依次类推。这就是LSTM处理时序信息的整体过程。
这里需要注意的是,在LSTM中虽然有两个状态向量$c_{t}$和$ h_{t}$,但一般来讲,会将$c_{t}$视为能够代表阅读到当前LSTM单元信息的状态(或者说是记忆), 而$ h_{t}$是当前LSTM单元对外的输出状态,它是实际的工作状态向量,即一般会利用$ h_{t}$来做一些具体的任务。
2.3. 从公式层面理解LSTM
前边我们从宏观上解释了LSTM是如何工作的,接下来我深入到LSTM单元内部进行介绍,看看它是如何保持数据的长期依赖的。我们先来看下LSTM单元内部是什么样的。
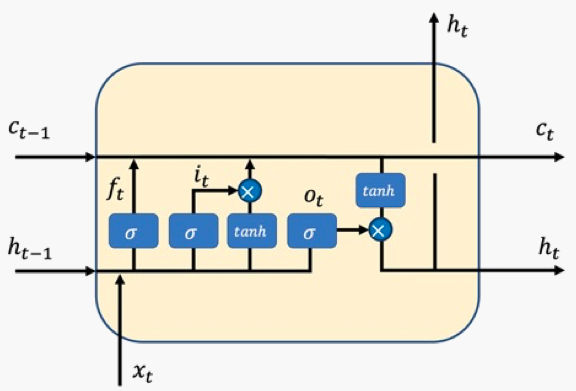
图3 LSTM单元内部结构
图3展示了LSTM单元内部的结构,里面包含了这样截个重要的组件:
- 状态向量$c_t$:它控制着整个LSTM单元的状态或者记忆,它会根据每个时刻的输入进行更新,从而实时保持LSTM单元的记忆。
- 隐状态向量$h_t$:它是当前LSTM单元对外的输出状态,它是实际的工作状态向量,即一般会利用$ h_{t}$来做一些具体的任务。
- 输入门$i_t$:控制当前时刻的输入信息需要向状态向量$c_t$中注入哪些信息。举个例子,当输入信息是一些没有实际意义的词,比如"的",可能模型不会让这些信息流入到状态向量中,从而保持模型的语义表达。
- 遗忘门$f_t$:控制前一时刻的状态向量$c_{t-1}$需要被屏蔽/遗忘哪些信息。举个例子,昨天我去爬了长城,哦不对是前天, 当模型看到"不对,是前天"的时候,可能就会忘记前边的"昨天"。
- 输出门$o_t$:控制当前时刻的状态向量$c_t$需要对外输出哪些信息,最终输出的信息即为$h_t$。
在了解了这些基本概念后,来看下这些组件的具体生成过程,首先来看下这三个门的生成过程,以时刻$t$为例:
$$\begin{align} i_t &= sigmoid(W_ix_t+U_ih_{t-1}+b_i) \\ f_t &= sigmoid(W_fx_t+U_fh_{t-1}+b_f) \\ o_t &= sigmoid(W_ox_t+U_oh_{t-1}+b_o) \end{align}$$
可以看到,这三个门的计算是使用输入数据$x_t$和$h_{t-1}$进行线性变换后,将结果传递给$sigmoid$函数,因为$sigmoid$函数是值域(0,1)的函数,即它能够将数据映射到这个固定区间,从而控制信息的流动。
接下来,计算下当前LSTM单元的待输入信息:
$$a_t = tanh(W_ax_t+U_ah_{t-1}+b_a)$$
同样是对输入数据$x_t$和$h_{t-1}$进行线性变换,然后将结果传递给$tanh$函数,最终的结果即为待向当前LSTM单元的状态向量$c_t$中注入的信息。有了以上这些组件,接下来就可以更新当前LSTM单元的状态向量$c_t$了。
$$c_t = f_t \cdot c_{t-1} + i_t \cdot a_t$$
显然,LSTM单元状态$c_t$的更新是对上一个时刻的状态$c_{t-1}$进行有选择的遗忘,对当前时刻的待输入信息$a_t$将有选择的输入,最后将两者的结果进行相加,表示向当前LSTM单元即融入了以前的状态信息$c_{t-1}$,同时又注入了当前最新的信息$a_t$。在计算出当前时刻的状态向量$c_t$后,就可以根据该状态向量对外进行输出了。
$$h_t=o_t \cdot tanh(c_t)$$
即通过输出门对当前的状态信息$c_t$进行有选择的输出。
2.4. 使用LSTM设计情感分析任务
前边讲完了LSTM的原理,包括宏观工作流程和微观公式理论,下面使用LSTM去简单生成一个情感分析的案例,期望能够给读者带来一些使用经验。
2.4.1. 情感分析是什么
情感分析(sentiment classification)意在提炼出一句话中的感情色彩,比如高兴,普通,惊讶,伤心,愤怒等。但一般为了简化问题,会将这些感情划分为3类:积极、中立和消极情感,如图4所示。 因此可以将情感分析任务建模成一个文本三分类问题。

图4 情感三分类
来看下边的例子,第1句话显然是对手机的赞美,因此它的情感类别为积极;第2个句话是说热水器有问题,因此它的情感类别为消极;第3句话不带有任何感情色彩,因此它的情感类别是中立。
我很喜欢这款手机,它的拍照功能很强大。
这个热水器太费电了,千万不能买。
今天我看了一本书,这本书的名字是人间失格。
2.4.2. 使用LSTM进行文本分类建模
在循环神经网络RNN章节中,谈到当RNN读完最后一个单词的时候,其实已经读完了整个句子,那么最后这个单词输出的向量可以被视为整个句子的语义向量。LSTM同样适用这个做法,只是这里一般将前边讲到的隐状态向量作为整个句子的语义向量。
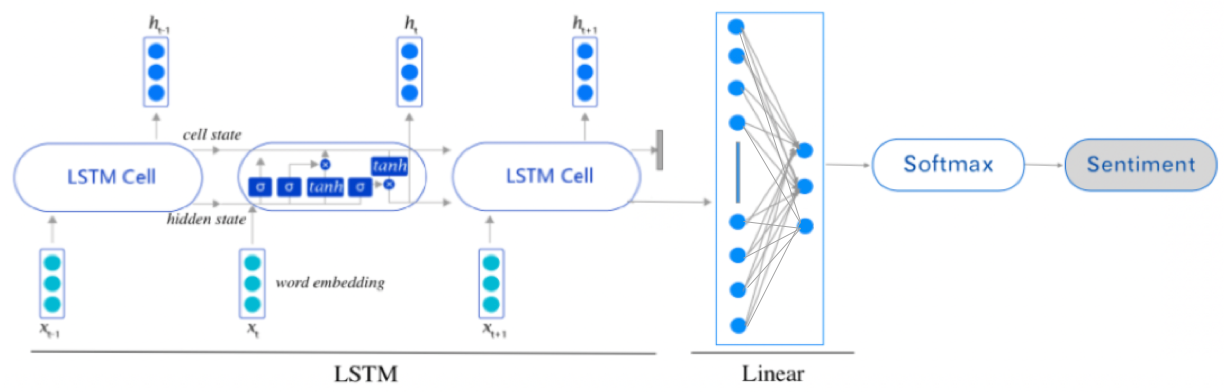
图5 一种使用LSTM建模文本分类的结构图
图5展示了一种使用LSTM建模文本分类的结构图,当给定一个文本序列的时候,首先对文本序列进行分词,然后将每个单词的词向量传递LSTM,LSTM后会生成该句子的语义向量;然后将该语义向量传递给一个线性层,从而将这个语义向量映射为一个长度为3个情感向量,其中每一维代表一个情感类别。但是这个这个情感向量数值未归一化,因此还需要使用$softmax$进行归一化,使其变成一个数值在[0,1]之间,相加和为1的数值。最后这个情感向量分数最大的那一维对应的情感类别就是整个句子的情感类别。
3. 门控循环单元 GRU
在神经网络发展的过程中,几乎所有关于LSTM的文章中对于LSTM的结构都会做出一些变动,也称为LSTM的变体。其中变动较大的是门控循环单元(Gated Recurrent Units),也就是较为流行的GRU。GRU是2014年由Cho, et al在文章《Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation》中提出的,某种程度上GRU也是对于LSTM结构复杂性的优化。LSTM能够解决循环神经网络因长期依赖带来的梯度消失和梯度爆炸问题,但是LSTM有三个不同的门,参数较多,训练起来比较困难。GRU只含有两个门控结构,且在超参数全部调优的情况下,二者性能相当,但是GRU结构更为简单,训练样本较少,易实现。

GRU在LSTM的基础上主要做出了两点改变 :
[1] - GRU只有两个门。GRU将LSTM中的输入门和遗忘门合二为一,称为更新门(update gate),上图中的$z_{t}$,控制前边记忆信息能够继续保留到当前时刻的数据量,或者说决定有多少前一时间步的信息和当前时间步的信息要被继续传递到未来;GRU的另一个门称为重置门(reset gate),上图中的$r_{t}$ ,控制要遗忘多少过去的信息。
[2] - 取消进行线性自更新的记忆单元(memory cell),而是直接在隐藏单元中利用门控直接进行线性自更新。GRU的逻辑图如上图所示。
GRU的公式化表达如下:
$$z_{t}=\sigma(W_{z} \cdot [h_{t-1},x_{t}])$$
$$r_{t}=\sigma(W_{r} \cdot [h_{t-1},x_{t}])$$
$$\tilde h=tanh(W \cdot [r_{t} \odot h_{t-1},x_{t}])$$
$$h_{t}=(1-z_{t})\odot h_{t-1}+z_{t} \odot \tilde h_{t-1}$$
下面分步介绍GRU的单元传递过程,公式也会在接下来的章节进行详细的介绍:

上图是带有门控循环单元的循环神经网络。
3.1. 更新门
在时间步 t,首先需要使用以下公式计算更新门
$$z_{t}=\sigma(W_{z} \cdot [h_{t-1},x_{t}])$$
其中 $x_{t}$ 为第 t 个时间步的输入向量,即输入序列 X 的第 t 个分量,它会经过一个线性变换(与权重矩阵$W_{z}$ 相乘)。$h_{t-1}$保存的是前一个时间步 t-1 的信息,它同样也会经过一个线性变换。更新门将这两部分信息相加并投入到 Sigmoid 激活函数中,因此将激活结果压缩到 0 到 1 之间。以下是更新门在整个单元的位置与表示方法。

更新门帮助模型决定到底要将多少过去的信息传递到未来,或到底前一时间步和当前时间步的信息有多少是需要继续传递的。这一点非常强大,因为模型能决定从过去复制所有的信息以减少梯度消失的风险。
3.2. 重置门
本质上来说,重置门主要决定了到底有多少过去的信息需要遗忘,可以使用以下表达式计算:
$$r_{t}=\sigma(W_{r} \cdot [h_{t-1},x_{t}])$$
该表达式与更新门的表达式是一样的,只不过线性变换的参数和用处不一样而已。下图展示了该运算过程的表示方法。

如前面更新门所述,$h_{t-1}$和 $x_{t}$先经过一个线性变换,再相加投入 Sigmoid 激活函数以输出激活值。
3.3. 当前记忆内容
现在具体讨论一下这些门控到底如何影响最终的输出。在重置门的使用中,新的记忆内容将使用重置门储存过去相关的信息,它的计算表达式为:
$$\tilde h=tanh(W \cdot [r_{t} \odot h_{t-1},x_{t}])$$
输入$x_{t}$与上一时间步信息 $h_{t-1}$先经过一个线性变换,即分别右乘矩阵 W。
计算重置门 $r_{t}$与$h_{t-1}$ 的 Hadamard 乘积,即 $r_{t}$ 与$h_{t-1}$的对应元素乘积。因为前面计算的重置门是一个由 0 到 1 组成的向量,它会衡量门控开启的大小。例如某个元素对应的门控值为 0,那么它就代表这个元素的信息完全被遗忘掉。该 Hadamard 乘积将确定所要保留与遗忘的以前信息。
将这两部分的计算结果相加再投入双曲正切激活函数中。该计算过程可表示为:

3.4. 当前时间步的最终记忆
在最后一步,网络需要计算 $h_t$,该向量将保留当前单元的信息并传递到下一个单元中。在这个过程中,需要使用更新门,它决定了当前记忆内容 $\tilde h$和前一时间步 $h_{t-1}$中需要收集的信息是什么。这一过程可以表示为:
$$h_{t}=(1-z_{t})\odot h_{t-1}+z_{t} \odot \tilde h_{t-1}$$
$z_t$ 为更新门的激活结果,它同样以门控的形式控制了信息的流入。$1-z_t$ 与$ h_{t-1}$的 Hadamard 乘积表示前一时间步保留到最终记忆的信息,该信息加上当前记忆保留至最终记忆的信息($z_t$ 与$ \tilde h_{t-1}$的 Hadamard 乘积)就等于最终门控循环单元输出的内容。
以上表达式可以展示为:

门控循环单元不会随时间而清除以前的信息,它会保留相关的信息并传递到下一个单元,因此它利用全部信息而避免了梯度消失问题。
参考文献
[1] - Chung, J., Gulcehre, C., Cho, K., & Bengio, Y. (2014). Empirical evaluation of gated recurrent neural networks on sequence modeling
[2] - 经典必读:门控循环单元(GRU)的基本概念与原理