原图:Milvus 助力又拍图片管家亿级图像搜图系统 - 2020.06.12
原文:The Journey to Optimize Billion-Scale Image Search - 2020.08.13
又拍图片管家当前服务了千万级用户,管理了百亿级图片. 当用户的图库变得越来越庞大时,业务上急切的需要一种方案能够快速定位图像,即直接输入图像,然后根据输入的图像内容来找到图库中的原图及相似图,而以图搜图服务就是为了解决这个问题.
作者有幸独立负责并实施了整个以图搜图系统从技术调研、到设计验证、以及最后工程实现的全过程. 而整个以图搜图服务也是经历了两次的整体演进:从 2019 年初开始第一次技术调研,经历春节假期,2019 年 3、4 月份第一代系统整体上线;2020 年初着手升级方案调研,经历春节及疫情,2020 年 4 月份开始第二代系统的整体升级.
本文将会简述两代搜图系统背后的技术选型及基本原理.
1. 基础概要
1.1. 图像是什么
与图像打交道,必须要先知道:图像是什么?
答案:像素点的集合.
比如:

左图红色圈中的部分其实就是右图中一系列的像素点.
再举例:

假设上图红色圈的部分是一幅图像,其中每一个独立的小方格就是一个像素点(简称像素),像素是最基本的信息单元,而这幅图像的大小就是 11 x 11 px .
1.2. 图像的数学表示
每个图像都可以很自然的用矩阵来表示,每个像素点对应的就是矩阵中的一个元素.
1.3. 二值图像
二值图像的像素点只有黑白两种情况,因此每个像素点可以由 0 和 1 来表示.
比如一张 4 * 4 二值图像:
0 1 0 1
1 0 0 0
1 1 1 0
0 0 1 01.4. RGB 图像
红(Red)、绿(Green)、蓝(Blue)作为三原色可以调和成任意的颜色,对于 RGB 图像,每个像素点包含 RGB 共三个通道的基本信息,类似的,如果每个通道用 8 bit 表示即 256 级灰度,那么一个像素点可以表示为:
([0 .. 255], [0 .. 255], [0 .. 255])比如一张 4 * 4 RGB 图像:

图像处理的本质实际上就是对这些像素矩阵进行计算.
1.5. 搜图的技术问题
如果只是找原图,也就是像素点完全相同的图像,那么直接对比它们的 MD5 值即可. 然而,图像在网络的传输过程中,常常会遇到诸如压缩、水印等等情况,而 MD5 算法的特点是,即使是小部分内容变动,其最终的结果却是天差地别,换句话说只要图片有一个像素点不一致,最后都是无法对比的.
对于一个以图搜图系统而言,我们要搜的本质上其实是内容相似的图片,为此,需要解决两个基本的问题:
[1] - 把图像表示或抽象为一个计算机数据,这个数据必须是可以进行对比计算的
直接用专业点的话说就是:图像的特征提取
[2] - 特征计算(相似性计算)
2. 第一代搜图系统
2.1. 特性提取 - 图像抽象
第一代搜图系统在特征提取上使用的是 Perceptual hash 即 pHash 算法,这个算法的基本原理是什么?

如上图所示,pHash 算法就是对图像整体进行一系列变换最后构造 hash 值,而变换的过程可以理解为对图像进行不断的抽象,此时如果对另外一张相似内容的图像进行同样的整体抽象,那么其结果一定是非常接近的.
2.2. 特性计算 - 相似性计算
对于两张图像的 pHash 值,具体如何计算其相似的程度?答案是 Hamming distance 汉明距离,汉明距离越小,图像内容越相似.
汉明距离又是什么?就是对应位置不同比特位的个数.
例如:
第一个值: 0 1 0 1 0
第二个值: 0 0 0 1 1以上两个值的对应位置上有 2 个比特位是不相同的,因此它们的汉明距离就是 2 .
OK ,相似性计算的原理我们知道了,那么下一个问题是:如何去计算亿级图片对应的亿级数据的汉明距离?简而言之,就是如何搜索?
在项目早期其实我并没有找到一个满意的能够快速计算汉明距离的工具(或者说是计算引擎),因此我的方案进行了一次变通.
变通的思想是:如果两个 pHash 值的汉明距离是接近的,那么将 pHash 值进行切割后,切割后的每一个小部分大概率相等.
例如:
第一个值: 8 a 0 3 0 3 f 6
第二个值: 8 a 0 3 0 3 d 8我们把上面这两个值分割成了 8 块,其中 6 块的值是完全相同的,因此可以推断它们的汉明距离接近,从而图像内容也相似.
经过变换之后,其实你可以发现,汉明距离的计算问题,变成了等值匹配的问题,我把每一个 pHash 值给分成了 8 段,只要里面有超过 5 段的值是完全相同的,那么我就认为他们相似.
等值匹配如何解决?这就很简单了,传统数据库的条件过滤不就可以用了嘛.
当然,我这里用的是 ElasticSearch( ES 的原理本文就不介绍了,读者可以另行了解),在 ES 里的具体操作就是多 term 匹配然后 minimum_should_match 指定匹配程度.
为什么搜索会选择 ElasticSearch ?第一点,它能实现上述的搜索功能;第二点,图片管家项目本身就正在用 ES 提供全文搜索的功能,使用现有资源,成本是非常低的.
2.3. 第一代系统总结
第一代搜图系统在技术上选择了 pHash + ElasticSearch 的方案,它拥有如下特点:
[1] - pHash 算法计算简单,可以对抗一定程度的压缩、水印、噪声等影响.
[2] - ElasticSearch 直接使用了项目现有资源,在搜索上没有增加额外的成本.
当然这套系统的局限性也很明显:由于 pHash 算法是对图像的整体进行抽象表示,一旦我们对整体性进行了破坏,比如在原图加一个黑边,就会几乎无法判断相似性.
为了突破这个局限性,底层技术截然不同的第二代搜图系统应运而生.
3. 第二代搜图系统
3.1. 特征提取
在计算机视觉领域,使用人工智能相关的技术基本上已经成了主流,同样,我们第二代搜图系统的特征提取在底层技术上使用的是 CNN 卷积神经网络.
CNN 卷积神经网络这个词让人比较难以理解,重点是回答两个问题:
[1] - CNN 能干什么?
[2] - 搜图为什么能用 CNN ?
AI 领域有很多赛事,图像分类是其中一项重要的比赛内容,而图像分类就是要去判断图片的内容到底是猫、是狗、是苹果、是梨子、还是其它对象类别.
CNN 能干什么?提取特征,进而识物,把这个过程简单的理解为,从多个不同的维度去提取特征,衡量一张图片的内容或者特征与猫的特征有多接近,与狗的特征有多接近,等等等等,选择最接近的就可以作为我们的识别结果,也就是判断这张图片的内容是猫,还是狗,还是其它.
CNN 识物又跟我们找相似的图像有什么关系?我们要的不是最终的识物结果,而是从多个维度提取出来的特征向量,两张内容相似的图像的特征向量一定是接近的.
具体使用哪种 CNN 模型?
我使用的是 VGG16 ,为什么选择它?首先,VGG16 拥有很好的泛化能力,也就是很通用;其次,VGG16 提取出来的特征向量是 512 维,维度适中,如果维度太少,精度可能会受影响,如果维度太多,存储和计算这些特征向量的成本会比较高.
3.1.1. 基于 Keras 实现
from keras.applications.vgg16 import VGG16
from keras.preprocessing import image
from keras.applications.vgg16 import preprocess_input
import numpy as np
#VGG16模型
model = VGG16(weights='imagenet', include_top=False)
#图片加载
img_path = 'elephant.jpg'
img = image.load_img(img_path, target_size=(224, 224))
#实际项目中,图片内容往往会先将图像转换为Bytes.
import io
from PIL import Image
# img_bytes: image content bytes
img = Image.open(io.BytesIO(img_bytes))
img = img.convert('RGB')
img = img.resize((224, 224), Image.NEAREST)
#图片预处理
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
#模型预测,特征提取
features = model.predict(x) #特征向量得到特征向量后,进行归一化:
from numpy import linalg as LA
#Normalization
norm_feat = feat[0]/LA.norm(feat[0])图像,如截图,往往会存在一定的黑边,黑边是没有实际意义的,且增加了计算量,因此通用做法是移除黑边的操作.
#!--*--coding: utf-8--*--
import numpy as np
from keras.preprocessing import image
def RemoveBlackEdge(img):
'''
Args:
img: PIL image instance
Returns:
PIL image instance
'''
width = img.width
img = image.img_to_array(img)
img_without_black = img[~np.all(img == np.zeros((1, width, 3), np.uint8), axis=(1, 2))]
img = image.array_to_img(img_without_black)
return img3.2. 向量搜索引擎
从图像提取特征向量的问题已经解决了,那么剩下的问题就是:
[1] - 特征向量如何存储?
[2] - 特征向量如何计算相似性,即如何搜索?
对于这两个问题,直接使用开源的向量搜索引擎 Milvus 就可以很好的解决,截至目前,Milvus 在我们的生产环境一直运行良好.
3.3. 项目实践及注意事项
3.3.1. CPU 环境要求
Milvus 的使用需要 CPU 支持 avx2 指令集. Linux 系统可以通过如下命令查看是否支持:
cat /proc/cpuinfo | grep flags
#或
cat /proc/cpuinfo | grep flags | grep avx2 3.3.2. 系统容量支撑计划(Capacity Planning)
在设计系统时,首先要考虑的就是系统的容量支撑能力. 如:
- 需要存储多少数据?
- 数据需要多少内存和磁盘空间?
假设向量的每一维是 float32 的,每个 float 占用 4 Bytes. 则 512 维的向量需要 2KB 存储. 类推:
- 一千条 512维向量需要 2MB 存储;
- 一百万条 512 维向量需要 2GB 存储;
- 一千万条 512 维向量需要 20GB 存储;
- 一亿条 512 维向量需要 200GB 存储;
- 十亿条 512 维向量需要 2TB 存储.
如果想要把所有数据存储到内存里,则系统至少需要对应的内存容量.
推荐采用 Milvus sizing tool.

实际上,在内存不足时,Milvus 会自动在磁盘刷新数据.
此外,除了考虑原始向量数据的存储,还需要考虑其他数据的存储,如日志数据等.
3.3.3. 系统配置
参考 Milvus 文档.
成功启动 Milvus 服务后,可以在 home/$USER/milvus 的路径下看到 Milvus 的文件夹. 其中包含以下文件:
- milvus/db(数据库存储)
- milvus/logs(日志存储)
milvus/conf(设置文件)
- server_config.yaml(服务设置)
具体可见:https://milvus.io/cn/docs/v0.10.6/milvus_config.md.
3.3.4. 数据库设计(Database Design)
Collection 和 Partition:
- Collection,即表. 包含一组 entity,可以等价于关系型数据库系统(RDBMS)中的表
- Partition,分区. Collection 中的分片.
集合、分区以及数据段的关系如下所示:
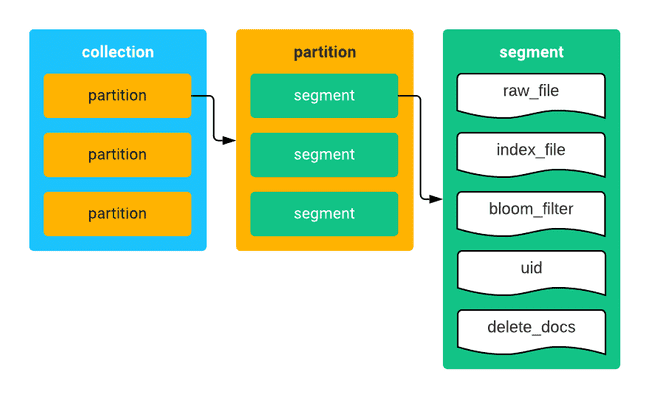
Milvus 的 Collection 和 Partiation 的数据结构比较简单,即,ID+vector. 换句话说,表里只有两列数据, ID 和向量数据.
注:
- ID 需要是整数.
- 需要确保 collection 内 ID 的唯一性,而不是 partition 内.
[1] - 条件过滤
在使用传统数据库时,可以指定特定字段作为过滤条件. 而 Milvus 不支持的. 但可以通过使用 collections 和 partitions 进行简单的条件过滤.
例如,对于大规模的图像数据,且属于不同的用户,那么可以将数据根据用户进行分区. 则可以将用户作为过滤条件,其实际上是指定了数据分区.
[2] - 结构化数据和向量映射
Milvus 仅支持 ID + vector 的数据结构. 但在商业场景中,往往需要处理的具有商业意义的结构化数据. 换句话说,需要通过向量查询得到结构化化数据. 那么,就需要维护结构化数据与向量之间的 ID 映射关系.
structured data ID <--> mapping table <--> Milvus ID
[3] - 索引选择
参考:
[1] - 索引类型 https://milvus.io/cn/docs/v0.10.6/index.md
[2] - 如何选择索引 https://medium.com/@milvusio/how-to-choose-an-index-in-milvus-4f3d15259212
[3] - Milvus 最佳实践之如何选择索引类型 https://blog.csdn.net/weixin_44839084/article/details/103471083
3.3.5. 搜索结果处理
Milvus 的搜索结果是 ID + distance 的 collection.
- ID - collection 中的 ID.
- Distance - [0,1]区间的距离向量,表示相似度,值约小,两个向量约相似.
[1] - 过滤 ID 是 -1 的数据
当 collections 数量过小时,搜索结果中可能会包含很多 ID 是 -1 的数据. 需要手工过滤.
[2] - 分页(Pagination)
搜索向量是很不同的. 查询结果会根据相似性降序排列,选择最相似的 topK 的结果.
Milvus 不支持分页. 需要根据商业场景实现分页函数. 例如,如果每页有 10 个搜索结果,且仅想显示到第三页,则需要指定 topK=30 且仅返回最后 10 个结果.
[3] - 相似度阈值
两张图像的特征向量间的距离是在 [0, 1] 区间的值. 如果在商业场景中,想要判断两张图像是否相似,需要指定相似度阈值. 如果距离小于阈值,则认为两张图像相似;如果距离大于阈值则认为不同. 需要结合商业场景调整阈值.
3.3. 第二代系统总结
第二代搜图系统在技术上选择了 CNN + Milvus 的方案,而这种基于特征向量的搜索在业务上也提供了更好的支持.