该文主要是介绍采用 conditional GAN 进行图像转换(image to image translation), 可参考 Image-to-Image Translation with Conditional Adversarial Networks - 2016
基于该技术,可以实现黑白图像的彩色化, 将谷歌地图转换为谷歌地球,等等. 这里,以建筑立面(building facades) 转换为真实建筑图(real buildings).
采用的数据集为:CMP Facade Database 的 Image-to-Image Translation with Conditional Adversarial Networks - 2016 论文作者提供的一个预处理版本: https://people.eecs.berkeley.edu/~tinghuiz/projects/pix2pix/datasets/.
每个 epoch 在 V100 GPU 上大概耗时 15s.
如下图, 为训练 200 epochs 后模型生成的例图:


1. 配置
import os
import time
import matplotlib.pyplot as plt
import tensorflow as tf2. 加载数据集
2.1. 数据增强
对于训练数据集, 进行随机抖动(random jittering) 和镜像(mirroring)处理.
[1] - 随机抖动, 图像先缩放为286x286, 再随机裁剪 256x256.
[2] - 随机镜像, 图像随机水平翻转,如, 左到右.
_URL = 'https://people.eecs.berkeley.edu/~tinghuiz/projects/pix2pix/datasets/facades.tar.gz'
path_to_zip = tf.keras.utils.get_file('facades.tar.gz',
origin=_URL,
extract=True)
PATH = os.path.join(os.path.dirname(path_to_zip), 'facades/')
#
BUFFER_SIZE = 400
BATCH_SIZE = 1
IMG_WIDTH = 256
IMG_HEIGHT = 256
#
def load(image_file):
image = tf.io.read_file(image_file)
image = tf.image.decode_jpeg(image)
w = tf.shape(image)[1]
w = w // 2
real_image = image[:, :w, :]
input_image = image[:, w:, :]
input_image = tf.cast(input_image, tf.float32)
real_image = tf.cast(real_image, tf.float32)
return input_image, real_image
#
inp, re = load(PATH+'train/100.jpg')
# casting to int for matplotlib to show the image
plt.figure()
plt.imshow(inp/255.0)
plt.figure()
plt.imshow(re/255.0)

def resize(input_image, real_image, height, width):
input_image = tf.image.resize(input_image, [height, width],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
real_image = tf.image.resize(real_image, [height, width],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
return input_image, real_image
def random_crop(input_image, real_image):
stacked_image = tf.stack([input_image, real_image], axis=0)
cropped_image = tf.image.random_crop(
stacked_image, size=[2, IMG_HEIGHT, IMG_WIDTH, 3])
return cropped_image[0], cropped_image[1]
# normalizing the images to [-1, 1]
def normalize(input_image, real_image):
input_image = (input_image / 127.5) - 1
real_image = (real_image / 127.5) - 1
return input_image, real_image
@tf.function()
def random_jitter(input_image, real_image):
# resizing to 286 x 286 x 3
input_image, real_image = resize(input_image, real_image, 286, 286)
# randomly cropping to 256 x 256 x 3
input_image, real_image = random_crop(input_image, real_image)
if tf.random.uniform(()) > 0.5:
# random mirroring
input_image = tf.image.flip_left_right(input_image)
real_image = tf.image.flip_left_right(real_image)
return input_image, real_image如图, 图像的处理流程为:
[1] - 将图像尺寸调整到更大的 height 和 width;
[2] - 随机裁剪到目标尺寸;
[3] - 随机水平翻转图像.
plt.figure(figsize=(6, 6))
for i in range(4):
rj_inp, rj_re = random_jitter(inp, re)
plt.subplot(2, 2, i+1)
plt.imshow(rj_inp/255.0)
plt.axis('off')
plt.show()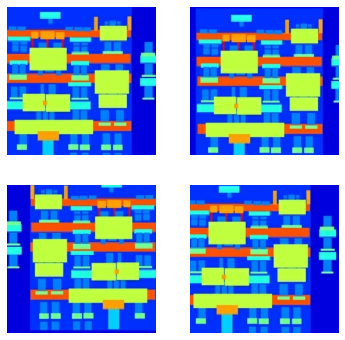
2.2. 数据集加载
def load_image_train(image_file):
input_image, real_image = load(image_file)
input_image, real_image = random_jitter(input_image, real_image)
input_image, real_image = normalize(input_image, real_image)
return input_image, real_image
def load_image_test(image_file):
input_image, real_image = load(image_file)
input_image, real_image = resize(input_image, real_image,
IMG_HEIGHT, IMG_WIDTH)
input_image, real_image = normalize(input_image, real_image)
return input_image, real_image3. 输入 Pipelines
# train dataset
train_dataset = tf.data.Dataset.list_files(PATH+'train/*.jpg')
train_dataset = train_dataset.map(
load_image_train,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
train_dataset = train_dataset.shuffle(BUFFER_SIZE)
train_dataset = train_dataset.batch(BATCH_SIZE)
# test dataset
test_dataset = tf.data.Dataset.list_files(PATH+'test/*.jpg')
test_dataset = test_dataset.map(load_image_test)
test_dataset = test_dataset.batch(BATCH_SIZE)4. 构建生成器
[1] - 网络结构是 U-Net 的改良.
[2] - 编码器(encoder)的每个 block 结构为:Conv -> Batchnorm -> Leaky ReLU.
[3] - 解码器(decoder)的每个 block 结构为:Transposed Conv -> Batchnorm -> Dropout(applied to the first 3 blocks) -> ReLU.
[4] - 编码器和解码器之间采用跳跃连接(skip connection),类似于 U-Net.
OUTPUT_CHANNELS = 3
#编码器
def downsample(filters, size, apply_batchnorm=True):
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2D(filters, size, strides=2, padding='same',
kernel_initializer=initializer, use_bias=False))
if apply_batchnorm:
result.add(tf.keras.layers.BatchNormalization())
result.add(tf.keras.layers.LeakyReLU())
return result
#
down_model = downsample(3, 4)
down_result = down_model(tf.expand_dims(inp, 0))
print (down_result.shape)
# (1, 128, 128, 3)
#解码器
def upsample(filters, size, apply_dropout=False):
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2DTranspose(filters, size, strides=2,
padding='same',
kernel_initializer=initializer,
use_bias=False))
result.add(tf.keras.layers.BatchNormalization())
if apply_dropout:
result.add(tf.keras.layers.Dropout(0.5))
result.add(tf.keras.layers.ReLU())
return result
#
up_model = upsample(3, 4)
up_result = up_model(down_result)
print (up_result.shape)
# (1, 256, 256, 3)
#生成器
def Generator():
inputs = tf.keras.layers.Input(shape=[256,256,3])
down_stack = [
downsample(64, 4, apply_batchnorm=False), # (bs, 128, 128, 64)
downsample(128, 4), # (bs, 64, 64, 128)
downsample(256, 4), # (bs, 32, 32, 256)
downsample(512, 4), # (bs, 16, 16, 512)
downsample(512, 4), # (bs, 8, 8, 512)
downsample(512, 4), # (bs, 4, 4, 512)
downsample(512, 4), # (bs, 2, 2, 512)
downsample(512, 4), # (bs, 1, 1, 512)
]
up_stack = [
upsample(512, 4, apply_dropout=True), # (bs, 2, 2, 1024)
upsample(512, 4, apply_dropout=True), # (bs, 4, 4, 1024)
upsample(512, 4, apply_dropout=True), # (bs, 8, 8, 1024)
upsample(512, 4), # (bs, 16, 16, 1024)
upsample(256, 4), # (bs, 32, 32, 512)
upsample(128, 4), # (bs, 64, 64, 256)
upsample(64, 4), # (bs, 128, 128, 128)
]
initializer = tf.random_normal_initializer(0., 0.02)
last = tf.keras.layers.Conv2DTranspose(OUTPUT_CHANNELS, 4,
strides=2,
padding='same',
kernel_initializer=initializer,
activation='tanh') # (bs, 256, 256, 3)
x = inputs
# Downsampling through the model
skips = []
for down in down_stack:
x = down(x)
skips.append(x)
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
x = tf.keras.layers.Concatenate()([x, skip])
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
#
generator = Generator()
tf.keras.utils.plot_model(generator, show_shapes=True, dpi=64)
#
gen_output = generator(inp[tf.newaxis,...], training=False)
plt.imshow(gen_output[0,...])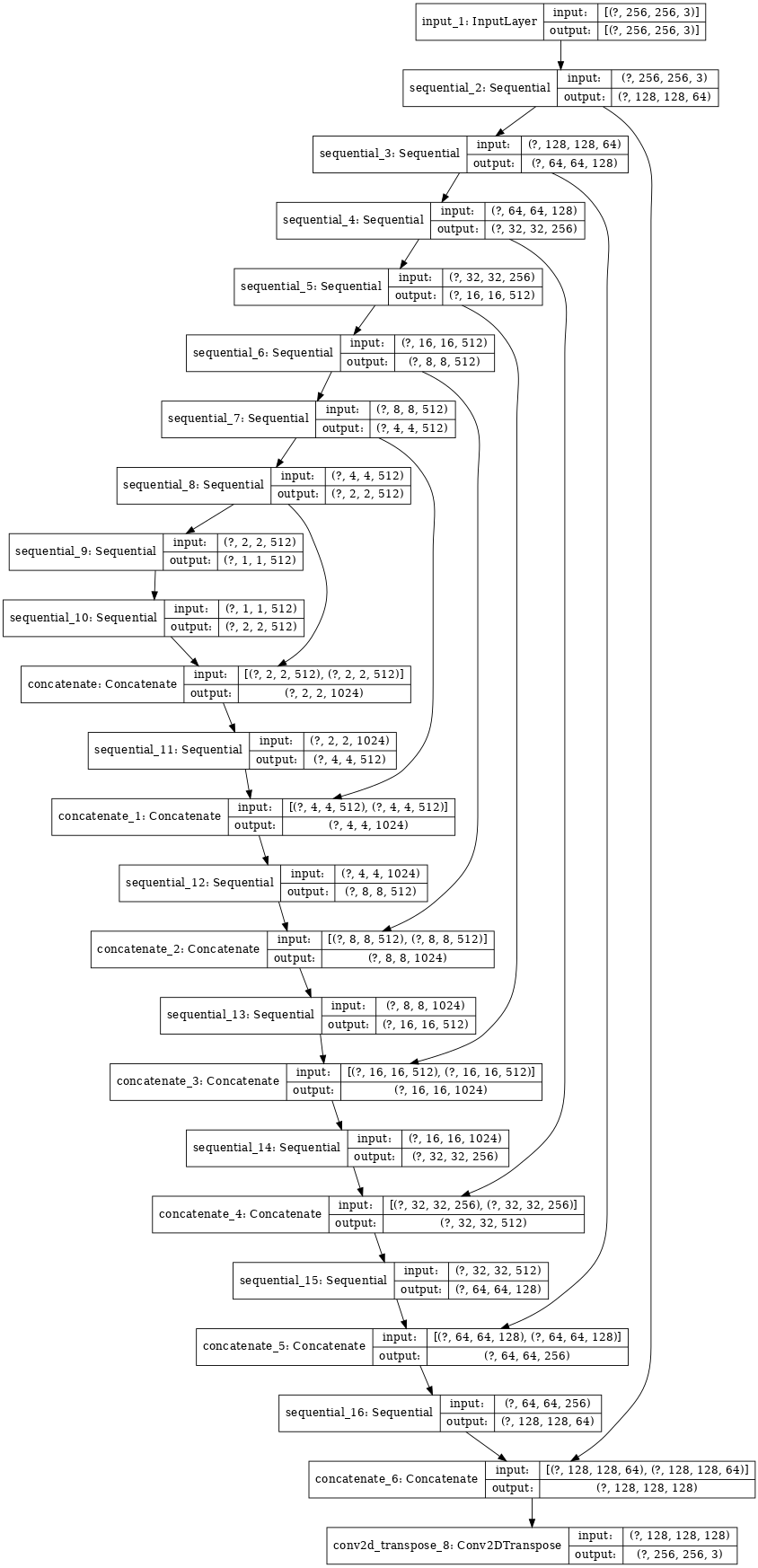

4.1. 生成器损失函数
[1] - 计算的是生成图像和全是1数组的 sigmoid 交叉熵损失函数.
[2] - Image-to-Image Translation with Conditional Adversarial Networks - 2016 还采用了 L1 损失函数,计算生成图像和目标图像间的 MAE(均方误差).
[3] - 生成器总损失函数的计算为:
$$ loss = gan\_loss + \lambda * l1\_loss $$
其中,$\lambda=100$.
生成器损失函数实现如:
LAMBDA = 100
def generator_loss(disc_generated_output, gen_output, target):
gan_loss = loss_object(tf.ones_like(disc_generated_output), disc_generated_output)
# mean absolute error
l1_loss = tf.reduce_mean(tf.abs(target - gen_output))
total_gen_loss = gan_loss + (LAMBDA * l1_loss)
return total_gen_loss, gan_loss, l1_loss流程如下:
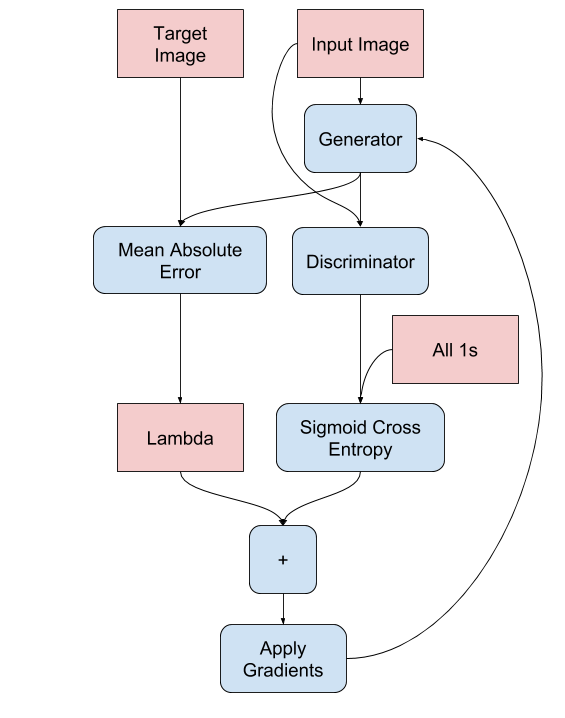
5. 构建判别器
[1] - 判别器是 PatchGAN;
[2] - 判别器每个 block 结构为:Conv -> BatchNorm -> Leaky ReLU
[3] - 判别器最后一层的输出 shape 为:(batch_size, 30, 30, 1)
[4] - 输出的每个 30x30 patch 分别对输入图像的 70x70 部分进行分类(这种结构被称为 PatchGAN)
[5] - 判别器包含两个输入:
- 输入图像和目标图像,其应该被分类为 real.
- 输入图像和生成图像,其应该被分类为 fake.
- 采用
tf.concat([inp, tar], axis=-1)将两个输入连接.
def Discriminator():
initializer = tf.random_normal_initializer(0., 0.02)
inp = tf.keras.layers.Input(shape=[256, 256, 3], name='input_image')
tar = tf.keras.layers.Input(shape=[256, 256, 3], name='target_image')
x = tf.keras.layers.concatenate([inp, tar]) # (bs, 256, 256, channels*2)
down1 = downsample(64, 4, False)(x) # (bs, 128, 128, 64)
down2 = downsample(128, 4)(down1) # (bs, 64, 64, 128)
down3 = downsample(256, 4)(down2) # (bs, 32, 32, 256)
zero_pad1 = tf.keras.layers.ZeroPadding2D()(down3) # (bs, 34, 34, 256)
conv = tf.keras.layers.Conv2D(512, 4, strides=1,
kernel_initializer=initializer,
use_bias=False)(zero_pad1) # (bs, 31, 31, 512)
batchnorm1 = tf.keras.layers.BatchNormalization()(conv)
leaky_relu = tf.keras.layers.LeakyReLU()(batchnorm1)
zero_pad2 = tf.keras.layers.ZeroPadding2D()(leaky_relu) # (bs, 33, 33, 512)
last = tf.keras.layers.Conv2D(1, 4, strides=1,
kernel_initializer=initializer)(zero_pad2) # (bs, 30, 30, 1)
return tf.keras.Model(inputs=[inp, tar], outputs=last)
#
discriminator = Discriminator()
tf.keras.utils.plot_model(discriminator, show_shapes=True, dpi=64)
#
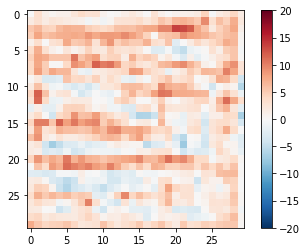
disc_out = discriminator([inp[tf.newaxis,...], gen_output], training=False)
plt.imshow(disc_out[0,...,-1], vmin=-20, vmax=20, cmap='RdBu_r')
plt.colorbar()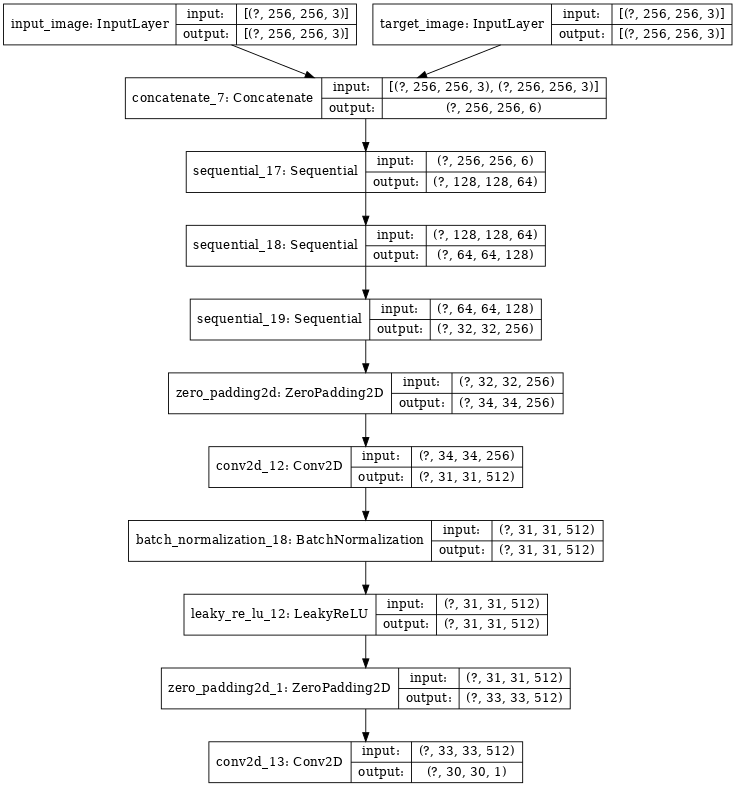
5.1. 判别器损失函数
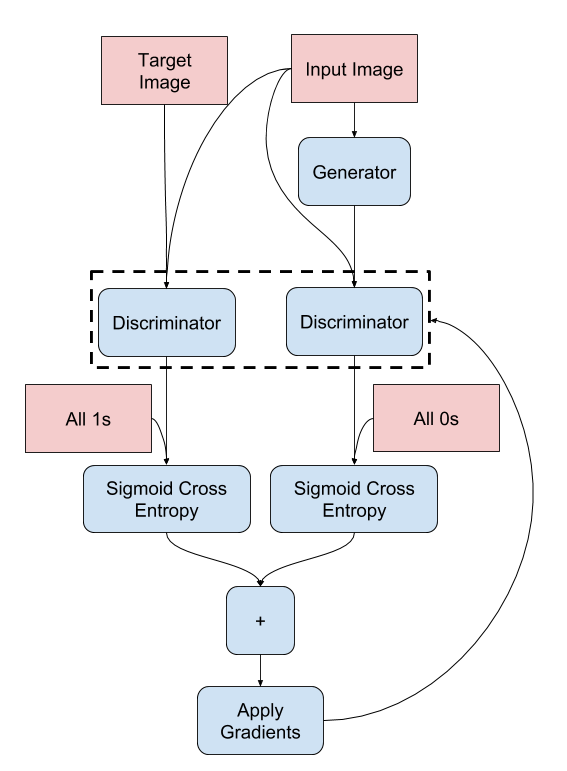
[1] - 判别器损失函数两个输入: real 图像和生成图像.
[2] - real_loss 为 real 图像与全1数组之间的 sigmoid 交叉熵损失函数.
[3] - generated_loss 为生成图像与全0数组之间的 sigmoid 交叉熵损失函数.
[4] - total_loss 为 real_loss 和 generated_loss 的之和.
loss_object = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def discriminator_loss(disc_real_output, disc_generated_output):
real_loss = loss_object(tf.ones_like(disc_real_output), disc_real_output)
generated_loss = loss_object(tf.zeros_like(disc_generated_output), disc_generated_output)
total_disc_loss = real_loss + generated_loss
return total_disc_loss流程如下:
6. 定义 Optimizers 和 Checkpoint-saver
generator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)7. 生成图像
创建一个训练过程中图像可视化的函数:
[1] - 将测试数据集图像送到生成器;
[2] - 生成器将其输入图像转化为输出;
[3] - 最后可视化预测图像.
def generate_images(model, test_input, tar):
prediction = model(test_input, training=True)
plt.figure(figsize=(15,15))
display_list = [test_input[0], tar[0], prediction[0]]
title = ['Input Image', 'Ground Truth', 'Predicted Image']
for i in range(3):
plt.subplot(1, 3, i+1)
plt.title(title[i])
# getting the pixel values between [0, 1] to plot it.
plt.imshow(display_list[i] * 0.5 + 0.5)
plt.axis('off')
plt.show()
#
for example_input, example_target in test_dataset.take(1):
generate_images(generator, example_input, example_target)
8. 训练
[1] - 每个输入样本生成一个输出;
[2] - 输入图像和生成的图像作为判别器的第一个输入;输入图像和目标图像作为判别器的第二个输入;
[3] - 然后,计算生成器损失函数和判别器损失函数;
[4] - 接着,计算关于生成器和判别器变量的梯度,并应用于优化器(optimizer);
[5] - TensorBoard 记录损失函数日志.
实现如下:
EPOCHS = 150
import datetime
log_dir="logs/"
summary_writer = tf.summary.create_file_writer(
log_dir + "fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
#
@tf.function
def train_step(input_image, target, epoch):
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
gen_output = generator(input_image, training=True)
disc_real_output = discriminator([input_image, target], training=True)
disc_generated_output = discriminator([input_image, gen_output], training=True)
gen_total_loss, gen_gan_loss, gen_l1_loss = generator_loss(disc_generated_output, gen_output, target)
disc_loss = discriminator_loss(disc_real_output, disc_generated_output)
generator_gradients = gen_tape.gradient(gen_total_loss,
generator.trainable_variables)
discriminator_gradients = disc_tape.gradient(disc_loss,
discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(generator_gradients,
generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(discriminator_gradients,
discriminator.trainable_variables))
with summary_writer.as_default():
tf.summary.scalar('gen_total_loss', gen_total_loss, step=epoch)
tf.summary.scalar('gen_gan_loss', gen_gan_loss, step=epoch)
tf.summary.scalar('gen_l1_loss', gen_l1_loss, step=epoch)
tf.summary.scalar('disc_loss', disc_loss, step=epoch)8.1. 训练主循环
[1] - epochs 迭代
[2] - 每个 epoch,清除显示的图片,并运行generate_images 以显示训练进度;
[3] - 每个 epoch,迭代处理训练数据集,并打印..
[4] - 每 20 epochs 保存一次 checkpoint.
def fit(train_ds, epochs, test_ds):
for epoch in range(epochs):
start = time.time()
display.clear_output(wait=True)
for example_input, example_target in test_ds.take(1):
generate_images(generator, example_input, example_target)
print("Epoch: ", epoch)
# Train
for n, (input_image, target) in train_ds.enumerate():
print('.', end='')
if (n+1) % 100 == 0:
print()
train_step(input_image, target, epoch)
print()
# saving (checkpoint) the model every 20 epochs
if (epoch + 1) % 20 == 0:
checkpoint.save(file_prefix = checkpoint_prefix)
print ('Time taken for epoch {} is {} sec\n'.format(epoch + 1,
time.time()-start))
checkpoint.save(file_prefix = checkpoint_prefix)
#
fit(train_dataset, EPOCHS, test_dataset)
#
# restoring the latest checkpoint in checkpoint_dir
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))训练循环会保存日志信息,可以在 TensorBoard 监视训练过程.

9. 测试数据集生成图像
# Run the trained model on a few examples from the test dataset
for inp, tar in test_dataset.take(5):
generate_images(generator, inp, tar)


10. 完整实现
#!/usr/bin/python3
#!--*-- coding: utf-8 --*--
import os
import time
import matplotlib.pyplot as plt
import datetime
import tensorflow as tf
print(tf.__version__)
#2.3.0
#
def load(image_file):
image = tf.io.read_file(image_file)
image = tf.image.decode_jpeg(image)
w = tf.shape(image)[1]
w = w // 2
real_image = image[:, :w, :]
input_image = image[:, w:, :]
input_image = tf.cast(input_image, tf.float32)
real_image = tf.cast(real_image, tf.float32)
return input_image, real_image
def resize(input_image, real_image, height, width):
input_image = tf.image.resize(input_image, [height, width], method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
real_image = tf.image.resize(real_image, [height, width], method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
return input_image, real_image
def random_crop(input_image, real_image, IMG_HEIGHT = 256, IMG_WIDTH = 256):
stacked_image = tf.stack([input_image, real_image], axis=0)
cropped_image = tf.image.random_crop(stacked_image, size=[2, IMG_HEIGHT, IMG_WIDTH, 3])
return cropped_image[0], cropped_image[1]
# normalizing the images to [-1, 1]
def normalize(input_image, real_image):
input_image = (input_image / 127.5) - 1
real_image = (real_image / 127.5) - 1
return input_image, real_image
@tf.function()
def random_jitter(input_image, real_image):
# resizing to 286 x 286 x 3
input_image, real_image = resize(input_image, real_image, 286, 286)
# randomly cropping to 256 x 256 x 3
input_image, real_image = random_crop(input_image, real_image)
if tf.random.uniform(()) > 0.5:
# random mirroring
input_image = tf.image.flip_left_right(input_image)
real_image = tf.image.flip_left_right(real_image)
return input_image, real_image
#
def load_image_train(image_file):
input_image, real_image = load(image_file)
input_image, real_image = random_jitter(input_image, real_image)
input_image, real_image = normalize(input_image, real_image)
return input_image, real_image
def load_image_test(image_file, IMG_HEIGHT = 256, IMG_WIDTH = 256):
input_image, real_image = load(image_file)
input_image, real_image = resize(input_image, real_image, IMG_HEIGHT, IMG_WIDTH)
input_image, real_image = normalize(input_image, real_image)
return input_image, real_image
#编码器
def downsample(filters, size, apply_batchnorm=True):
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(tf.keras.layers.Conv2D(filters, size, strides=2, padding='same',
kernel_initializer=initializer, use_bias=False))
if apply_batchnorm:
result.add(tf.keras.layers.BatchNormalization())
result.add(tf.keras.layers.LeakyReLU())
return result
#解码器
def upsample(filters, size, apply_dropout=False):
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(tf.keras.layers.Conv2DTranspose(filters, size, strides=2, padding='same',
kernel_initializer=initializer, use_bias=False))
result.add(tf.keras.layers.BatchNormalization())
if apply_dropout:
result.add(tf.keras.layers.Dropout(0.5))
result.add(tf.keras.layers.ReLU())
return result
#生成器
def Generator(OUTPUT_CHANNELS = 3):
inputs = tf.keras.layers.Input(shape=[256, 256, 3])
down_stack = [
downsample(64, 4, apply_batchnorm=False), # (bs, 128, 128, 64)
downsample(128, 4), # (bs, 64, 64, 128)
downsample(256, 4), # (bs, 32, 32, 256)
downsample(512, 4), # (bs, 16, 16, 512)
downsample(512, 4), # (bs, 8, 8, 512)
downsample(512, 4), # (bs, 4, 4, 512)
downsample(512, 4), # (bs, 2, 2, 512)
downsample(512, 4), # (bs, 1, 1, 512)
]
up_stack = [
upsample(512, 4, apply_dropout=True), # (bs, 2, 2, 1024)
upsample(512, 4, apply_dropout=True), # (bs, 4, 4, 1024)
upsample(512, 4, apply_dropout=True), # (bs, 8, 8, 1024)
upsample(512, 4), # (bs, 16, 16, 1024)
upsample(256, 4), # (bs, 32, 32, 512)
upsample(128, 4), # (bs, 64, 64, 256)
upsample(64, 4), # (bs, 128, 128, 128)
]
initializer = tf.random_normal_initializer(0., 0.02)
last = tf.keras.layers.Conv2DTranspose(OUTPUT_CHANNELS, 4,
strides=2,
padding='same',
kernel_initializer=initializer,
activation='tanh') # (bs, 256, 256, 3)
x = inputs
# Downsampling through the model
skips = []
for down in down_stack:
x = down(x)
skips.append(x)
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
x = tf.keras.layers.Concatenate()([x, skip])
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
#
def Discriminator():
initializer = tf.random_normal_initializer(0., 0.02)
inp = tf.keras.layers.Input(shape=[256, 256, 3], name='input_image')
tar = tf.keras.layers.Input(shape=[256, 256, 3], name='target_image')
x = tf.keras.layers.concatenate([inp, tar]) # (bs, 256, 256, channels*2)
down1 = downsample(64, 4, False)(x) # (bs, 128, 128, 64)
down2 = downsample(128, 4)(down1) # (bs, 64, 64, 128)
down3 = downsample(256, 4)(down2) # (bs, 32, 32, 256)
zero_pad1 = tf.keras.layers.ZeroPadding2D()(down3) # (bs, 34, 34, 256)
conv = tf.keras.layers.Conv2D(512, 4, strides=1,
kernel_initializer=initializer,
use_bias=False)(zero_pad1) # (bs, 31, 31, 512)
batchnorm1 = tf.keras.layers.BatchNormalization()(conv)
leaky_relu = tf.keras.layers.LeakyReLU()(batchnorm1)
zero_pad2 = tf.keras.layers.ZeroPadding2D()(leaky_relu) # (bs, 33, 33, 512)
last = tf.keras.layers.Conv2D(1, 4, strides=1, kernel_initializer=initializer)(zero_pad2) # (bs, 30, 30, 1)
return tf.keras.Model(inputs=[inp, tar], outputs=last)
#
loss_object = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def generator_loss(disc_generated_output, gen_output, target, LAMBDA = 100):
gan_loss = loss_object(tf.ones_like(disc_generated_output), disc_generated_output)
# mean absolute error
l1_loss = tf.reduce_mean(tf.abs(target - gen_output))
total_gen_loss = gan_loss + (LAMBDA * l1_loss)
return total_gen_loss, gan_loss, l1_loss
def discriminator_loss(disc_real_output, disc_generated_output):
real_loss = loss_object(tf.ones_like(disc_real_output), disc_real_output)
generated_loss = loss_object(tf.zeros_like(disc_generated_output), disc_generated_output)
total_disc_loss = real_loss + generated_loss
return total_disc_loss
#
def generate_images(model, test_input, tar):
prediction = model(test_input, training=True)
plt.figure(figsize=(15, 15))
display_list = [test_input[0], tar[0], prediction[0]]
title = ['Input Image', 'Ground Truth', 'Predicted Image']
for i in range(3):
plt.subplot(1, 3, i + 1)
plt.title(title[i])
# getting the pixel values between [0, 1] to plot it.
plt.imshow(display_list[i] * 0.5 + 0.5)
plt.axis('off')
# plt.show()
#
@tf.function
def train_step(input_image, target, epoch):
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
gen_output = generator(input_image, training=True)
disc_real_output = discriminator([input_image, target], training=True)
disc_generated_output = discriminator([input_image, gen_output], training=True)
gen_total_loss, gen_gan_loss, gen_l1_loss = generator_loss(disc_generated_output, gen_output, target)
disc_loss = discriminator_loss(disc_real_output, disc_generated_output)
generator_gradients = gen_tape.gradient(gen_total_loss, generator.trainable_variables)
discriminator_gradients = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(generator_gradients, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(discriminator_gradients, discriminator.trainable_variables))
with summary_writer.as_default():
tf.summary.scalar('gen_total_loss', gen_total_loss, step=epoch)
tf.summary.scalar('gen_gan_loss', gen_gan_loss, step=epoch)
tf.summary.scalar('gen_l1_loss', gen_l1_loss, step=epoch)
tf.summary.scalar('disc_loss', disc_loss, step=epoch)
#
def fit(train_ds, epochs, test_ds):
for epoch in range(epochs):
start = time.time()
for example_input, example_target in test_ds.take(1):
generate_images(generator, example_input, example_target)
plt.savefig('epoch_{}.png'.format(epoch), format='png',)
print("Epoch: ", epoch)
# Train
for n, (input_image, target) in train_ds.enumerate():
print('.', end='')
if (n + 1) % 100 == 0:
print()
train_step(input_image, target, epoch)
print()
# saving (checkpoint) the model every 20 epochs
if (epoch + 1) % 20 == 0:
checkpoint.save(file_prefix=checkpoint_prefix)
print('Time taken for epoch {} is {} sec\n'.format(epoch + 1, time.time() - start))
checkpoint.save(file_prefix=checkpoint_prefix)
#
_URL = 'https://people.eecs.berkeley.edu/~tinghuiz/projects/pix2pix/datasets/facades.tar.gz'
path_to_zip = tf.keras.utils.get_file('facades.tar.gz', origin=_URL, extract=True)
PATH = os.path.join(os.path.dirname(path_to_zip), 'facades/')
#
inp, re = load(PATH+'train/100.jpg')
# # casting to int for matplotlib to show the image
# plt.figure()
# plt.imshow(inp/255.0)
# plt.figure()
# plt.imshow(re/255.0)
#
# #
# plt.figure(figsize=(6, 6))
# for i in range(4):
# rj_inp, rj_re = random_jitter(inp, re)
# plt.subplot(2, 2, i+1)
# plt.imshow(rj_inp/255.0)
# plt.axis('off')
# plt.show()
#
BATCH_SIZE = 1
# train dataset
train_dataset = tf.data.Dataset.list_files(PATH+'train/*.jpg')
train_dataset = train_dataset.map(load_image_train, num_parallel_calls=tf.data.experimental.AUTOTUNE)
train_dataset = train_dataset.shuffle(400) #BUFFER_SIZE = 400
train_dataset = train_dataset.batch(BATCH_SIZE)
# test dataset
test_dataset = tf.data.Dataset.list_files(PATH+'test/*.jpg')
test_dataset = test_dataset.map(load_image_test)
test_dataset = test_dataset.batch(BATCH_SIZE)
# #
# down_model = downsample(3, 4)
# down_result = down_model(tf.expand_dims(inp, 0))
# print (down_result.shape)
# # (1, 128, 128, 3)
# #
# up_model = upsample(3, 4)
# up_result = up_model(down_result)
# print (up_result.shape)
# # (1, 256, 256, 3)
#
generator = Generator()
# tf.keras.utils.plot_model(generator, show_shapes=True, dpi=64)
#
discriminator = Discriminator()
# tf.keras.utils.plot_model(discriminator, show_shapes=True, dpi=64)
# #
# gen_output = generator(inp[tf.newaxis,...], training=False)
# plt.imshow(gen_output[0,...])
#
# #
# disc_out = discriminator([inp[tf.newaxis,...], gen_output], training=False)
# plt.imshow(disc_out[0,...,-1], vmin=-20, vmax=20, cmap='RdBu_r')
# plt.colorbar()
#
generator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
# #
# for example_input, example_target in test_dataset.take(1):
# generate_images(generator, example_input, example_target)
#
log_dir="logs/"
summary_writer = tf.summary.create_file_writer(
log_dir + "fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
#
EPOCHS = 150
fit(train_dataset, EPOCHS, test_dataset)
#
# restoring the latest checkpoint in checkpoint_dir
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
# Run the trained model on a few examples from the test dataset
for inp, tar in test_dataset.take(5):
generate_images(generator, inp, tar)