出处:阿里技术 - 微信公众号
阿里妹导读:作为一名工程师,每天与代码打交道,往往没有时间注意自己的打扮. 试想,如果身边出现一位有品味的搭配高手,为你量身打造形象,岂不美哉?
如今,阿里工程师们推出了一个滴搭平台,基于千万时尚达人的优质搭配,已经学习出了一套比较成熟的算法,帮你找到最合适的穿搭. 不信?下面一起来深入了解“滴搭”背后的算法.
前言
自从去年“鹿班”AI设计师完成了1秒8000张海报的壮举,团队的小伙伴们开始思考如何让海报变得更加美观丰富. 其中一部分同学尝试用AI产出更加丰富的图文内容,成为陈列师、内容运营的好帮手,这部分工作,取名“滴搭”.
滴搭,是图文算法平台化运维的一次大胆尝试和稳定落地. 它以深度学习网络为基础,以开放式的生产平台为载体,赋能运营、赋能达人,支撑以多商品搭配形式为主的图文内容生产. 从2017年2月开始,滴搭的算法技术陆续在淘宝、天猫的多个业务上落地,横跨多个行业,并在大促中承担使命;辅助数万名达人生产搭配几千万套,覆盖商品数百万,服务商家数十万.
滴搭在三个方面做出了贡献:
[1] - 内容化生产:
以深度学习网络为基础,广泛收集商品信息、用户信息、运营知识作为输入,协助内容生产,生成质量和达人相当. 图文算法应用到多个行业的多个业务中.
[2] - 平台赋能:
算法和工程结合,运营可在滴搭平台选品、生成搭配、个性化投放,一站式管理.
[3] - 效率提升:
全站达人日均生产几千套搭配,算法小时生产百万套搭配,生成效率数量级提升. 算法搭配扩充了投放总池子,使得个性化效果得到提升.
下面,我们来详细地介绍滴搭平台.
一. 滴搭平台简介
滴搭是运营前台、算法平台、合图平台、个性化投放等等多个平台和算法的统一称谓.
运营在前台做完选品,经过深度图像处理和搭配算法,学习出可搭配商品的特征表示. 当一件或多件商品作为触发请求搭配时,可以从百万级的商品库中找出与之可搭配的、符合一定运营规则的其它商品,并根据触发商品和产出商品的信息,生成描述性标题. 最后经过智能排版技术,合成符合视觉审美的展现形式. 生成好的搭配经过推荐算法,个性化地投放给用户.
以下为滴搭后台的部分效果展示:

滴搭平台经历了几次较大的算法改版,现在基于淘内的优质搭配已经学习出了一套比较成熟的算法. 除了保证一套搭配中的个体风格、颜色、配饰等等做到贴合,滴搭还吸取了运营、达人的经验,严格按照成套规则进行产出,例如在服饰领域,上衣+下衣是合理的,但是下衣+裙装是不合理的;在登山场景,帐篷+手电筒+登山服是一个合理的组合,而烧烤架不是必须.
接下来,我们将重点介绍滴搭的算法. 由于我们涉及的行业很广,图文算法的应用业务非常多,为了更好地聚焦于算法本身,以下介绍若无特别说明,将以服饰行业的搭配业务为例.
二. 滴搭算法
滴搭需要完成搭配图片生成、搭配描述生成两部分工作,因此我们分别在图、文上设计算法框架. 底层的数据是公用的,包括商品图片、商品标题、运营输入以及其他side information. 在这个数据之上,我们先完成搭配图片的生成,再对该搭配进行文本描述.
在图搭配的算法中,我们用CNN(Convolutional Neural Networks)进行图片预处理,以 DSSM(Deep Semantic Similarity Model)作为基本框架,在此基础上尝试了两种搭配逻辑算法:第一种是 基于LSTM(Long Short Term Memory)的序列化搭配生产,第二种是基于DAN(Deep Aggregated Network)的无序列化搭配生产. 在产出图搭配后,我们将产出结果结合文案输入语料,输入文案描述模型 CPGN(Context aware Pointer-Generator Networks),产出文本描述. 最终的结果里包含图文内容,是搭配的整体化描述.
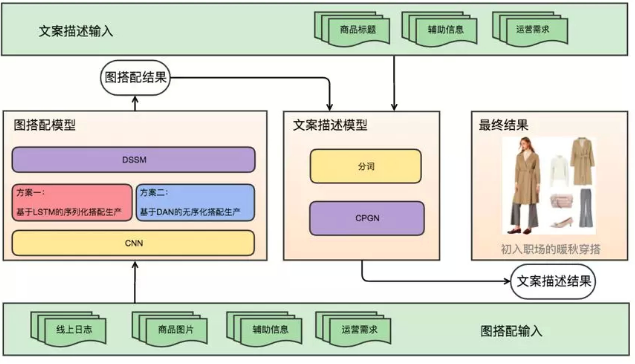
以下我们将分别介绍图文算法.
2.1. 图搭配算法
2.1.1. 相关工作
服饰类搭配在近些年的学术圈有了比较快速的发展. 生成一套搭配,总体上有两种思路:
[1] - 利用传统图像处理方法,将图像底层切割,利用专家知识构成细粒度的、可解释的搭配关系;
[2] - 基于深度学习方法,利用图像和文本技术做深层抽取和表示,用深层网络去隐式地学习搭配关系.
在这些工作中,文献[1] 试图给一套搭配打分,使用基于深度学习的多模态、多实例作为特征,质量分作为标签. 文献[2] 用双向LSTM网络模拟搭配的序列化过程,可以生产搭配、或者给一套搭配打分. 文献[3]虽然不是服务于搭配业务,但它将图像和文本结合起来,利用搭配里商品风格相近的原则,学习出商品的风格表示. 文献 [4] 用到了蒸馏网络的方法,将Teacher-Student网络巧妙地嫁接在特征表示后,使得搭配能够遵循知识图谱规约.
这些文章在学术上都给予我们很多启发,但是目前,据我们所知,在电商平台还没有一个完全智能化的搭配平台,可以在线实时地产出内容并进行投放. 线上生产的难点,一是数据量非常庞大,二是对于可投放的质量要求极高. 滴搭吸取了前人工作的优点,并在网络核心(DAN) 和向量对齐(DSSM)两方面做出了独创性的工作. 这两个网络在拿到更好效果的同时,也解决了数据庞大和线上效果保证两大难题.
滴搭的整体框架是第二种方法. 我们选择深度学习方法作为模型基础的原因是,深度学习的发展使得网络的高层特征已经能够比较详尽地涵盖图片的多种信息. 比如我们对白底图的 CNN 高维向量进行K-means聚类,会发现相同形状和风格的图片聚在一起. 这使得我们有信心可以利用深度学习网络的高层特征直接进行计算. 另一方面,滴搭不是专门为某一行业定制的平台,专家知识无法跨行业通用,且目前除了几个大行业之外,很多行业并没有开源出足够丰富的知识图谱. 为了满足线上业务要求,滴搭又融合了专家知识作为约束条件,因此对于结果具有部分解释性.
2.1.2. 准备工作
数据: 我们最开始的训练数据来源于 Polyvore 网站,该网站下有大量用户提交的搭配样例,并且提供其他用户点赞和评论. 在迁入淘内业务后,我们收集了淘内达人产出的几十万套优质搭配,对训练数据进行了重新整理.
特征表示:首先,我们需要对商品进行表示化. 最直接能展现一个商品信息的来源是其图片,我们依靠鹿班千万级的白底图库,对进入商品池的商品抽取特征. 这里我们用的是CNN技术,具体模型为 inception v3. 具体做法如下:
- 以类目作为label,对pre-trained模型进行fine-tune,抽取倒数第二层的向量表达作为该商品的图片表征.
- 将第一步的所有图片的向量表示进行带类目约束的K-means聚类. 考虑到搭配中的类目关系以及不同类目下商品数量分布的不同,我们针对性地对K-means做了优化,使得聚类结果更加集中且分布平衡. 一个类目下会有多个聚类结果,聚类结果用cluster表示. 该步骤后,每个商品都被聚类到其中一个cluster下.
- 将第二步得到的cluster作为label,重新用inception v3进行fine-tune,抽取高维向量表达作为最终的图片特征.
在CNN的基础上增加K-means的原因在于,我们希望图像上相似的图片能在向量表示上有更加接近的距离. 而CNN在K-means之后的分类结果也的确比最开始得到了提升,视觉上更加相似.
聚类后结果部分展示如下:

此外,由于图片有时候并不能涵盖所有信息,我们加入了side information作为信息补充. 目前加入的side information包括商品的类目和风格.
2.1.3. 模型一:基于LSTM的序列化搭配生产

首先,我们将准备工作中通过CNN得到的高维向量,和side information的向量,经过embedding和stacking的变换,作为模型的输入层.
其次,输入向量经过一层MLP,分成两路:一路进入LSTM网络进行序列化学习,一路进入进入DSSM网络进行向量对齐.
LSTM网络:我们将搭配的构成看成一个时序过程,每件搭配物品的产生为一个时序步骤. 从第一件商品开始,每一件新产生的商品需要和之前的所有商品有相关性. LSTM网络天然的时序关系使之成为可能. LSTM是RNN. (Recurrent Neural Network. )的一种衍生,它增加了功能门,能更好地捕捉长期依赖. 令 S 表示一套搭配,$x_t$ 是第 t 个商品的CNN特征表示,则 $S = x_1, x_2, ..., x_N$表示一个搭配序列. 根据最大似然估计原理,我们期望最大化:
$$ E(S) = \frac{1}{N} \sum_{t=1}^N logP(x_{t+1} | x_1, x_2, ..., x_t) $$
DSSM网络:我们希望可搭配的商品在向量空间上具有更接近的距离,于是参考了 DSSM 网络的方法. 我们从线上日志和优质搭配两方面获取正向样本,即收集日志里点击率高的搭配和达人高质量的搭配样例,拆成 pair 对,作为 DSSM 网络的正向样本;同时将线上点击率低的搭配作为负向样本.
从图中看出,当一个(或多个 )商品组合经过MLP之后,我们先拿到所有商品在进入LSTM之前的向量表示. 当LSTM每一步产出商品X时,我们将 X 也经过一个MLP变换,和每个进入 LSTM 之前的其他商品进行距离计算,其他商品的正样本样例表示为 $Y^+$,负样本样例表示为 $Y^-$. 我们希望正向样本之间的距离小,负向样本之间的距离大,因此loss表示为:
$$ \Delta = sim_{\theta}(X, Y^+) - sim_{\theta}(X, Y^-) $$
$$ Loss(\Delta; \theta) = log(1 + exp(- \gamma \Delta)) $$
其中,sim函数采用的是 cosine相似度,θ表示参数,目标是最大化Δ. 在GPU上,我们用mini-batch SGD来优化θ.
2.1.4. 模型二:基于DAN的无序化搭配生产
我们在LSTM模型一的基础上完成了第一版的投放,效果还是不错的. 在后续的研究中,我们发现了一个更好的模块:DAN,在以上的框架图中,它仅仅将LSTM模块做了替换,其他部分保持不变. 我们看到了更低的 loss 和更好的输出结果.
DAN的核心在于,它将搭配看成一个组合模式,而不是序列模式. 在日常生活中,我们会给上衣搭配裤子,也会给裤子搭配上衣,因此在训练 LSTM 网络的时候,我们其实需要构造两条不同顺序的训练数据:上衣+裤子,裤子+上衣. 而在DAN网络中,上衣和裤子是无序列差别的输入,它们以组合的形态输入网络中.
如下图所示,同一套搭配的训练数据在经过 CNN 和 side-information embedding 之后,输入到 DAN 网络. 首先经过非线性变化,变化后的向量进入池化层. 我们尝试了sum-pooling和max-pooling,发现sum-pooling有更好的结果.
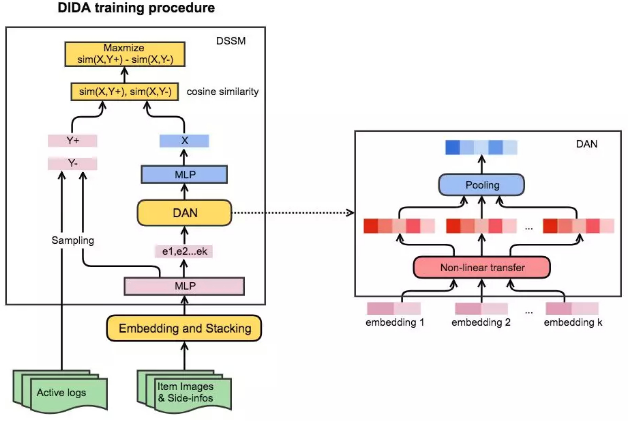
DAN网络在训练的过程中,获得了比LSTM更低的loss. 且在训练数据构造中,不再需要考虑全排列,而只需要组合数据就够了. 训练数据的减少大大缩减了训练时间,使得周期性迭代模型成为可能.
2.1.5. 基于context graph的预测过程
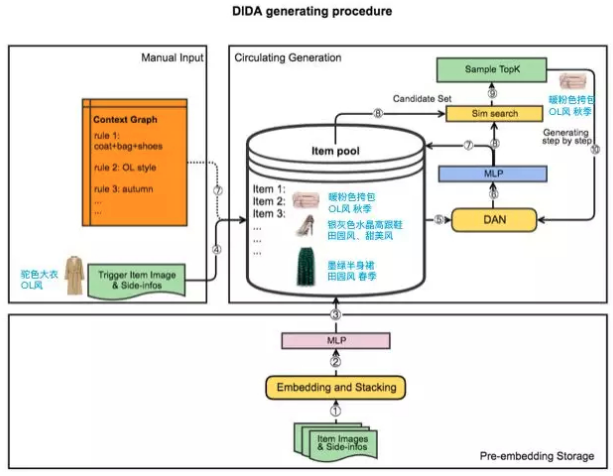
怎样称为一套搭配? 运营往往有不同的定义. 女装的运营可能认为,上衣+下衣+鞋是一套完整搭配,裙装+配饰+包是一套完整搭配,而连衣裙和牛仔裤是一定不能同时出现的. 又或者,家居的运营希望,一个卧室的场景里需要有床、床头柜、灯具、壁画,缺了其中一个都不是一个合格的卧室搭配. 实际上线过程中,运营往往还有场景氛围的需求,对于风格、季节等等有额外的限制. 如何将运营的诉求传递给搭配算法,我们设计了context graph来解决这个问题.
context graph是结构化的运营规约,包括类目搭配的约束、风格的约束、季节的约束,等等. 在搭配预测阶段,所有商品池的商品和它们的side-information经过Embedding、Stacking和全连接之后,存入商品池(item pool). 以DAN网络为例,当一个活动发起请求时,作为触发的商品经过DAN网络,如果不考虑约束,则我们会将MLP的输出结果到商品池中去做向量检索 (sim search),获取下一个商品. 如果考虑约束,则根据context graph的规约,先在向量检索的基础上做一层过滤,仅让满足运营规约的商品作为预测结果的候选集,再在候选集里挑出TopK. 在每产出一个搭配商品之后,算法重新计算当前满足的搭配约束情况,推动下一个商品的产生及圈定新的候选集.
我们将context graph打包到模型里,因此搭配的预测过程是完全实时的. context graph 保证了成品率,即每一套产出的搭配都符合运营的输入条件,降低了人工筛选的成本.
2.2. 文本算法
2.2.1. 相关工作
随着深度网络的发展,文本应用在近两年有着非常迅速的落地. 在机器翻译、阅读理解、摘要生成等文本工作中,sequence-to-sequence的框架被广泛应用,为不同应用目的而设计的attention网络也蓬勃发展.
我们将文案生成看成一个摘要生成问题,原始输入语料可以是商品原始标题、商品其他信息等等,而文案需要在原始语料中抽取出关键信息,进行总结甚至拓展描述. Pointer-Generator网络(PGN)[6]做到了这一点. 它本质上是一个encoder-decoder加attention的混合模型,但通过一个平衡参数,使得模型既可以从原始语料中抽取文字(pointing),也可以生成原始语料中没有的新词(generator). [7]同样采用了encoder-decode加attention的基本框架,但是通过蒙特卡洛采样缩小了目标词库,提升效果的同时也加快了预测速度.
在我们的场景下,除了从原始语料中生成,运营往往还会增加一些额外需求. 比如运营希望文案的描述中有偏向性,突出风格,突出颜色,或者突出利益点,我们称为搭配tag. 因此这部分我们也作为输入,加入到attention网络中.
2.2.2. 准备工作
数据:我们用达人搭配的几十万搭配描述作为训练数据. 训练数据的输入为商品的标题、搭配tag,训练数据的输出为达人撰写的标题. 我们将词作为基本单位.
2.2.3. CPGN模型
在PGN的基础上,我们加入了运营输入信息,使得文案、商品、运营要求三者之间建立强关联,因此新方法命名为CPGN,其算法框架如下:
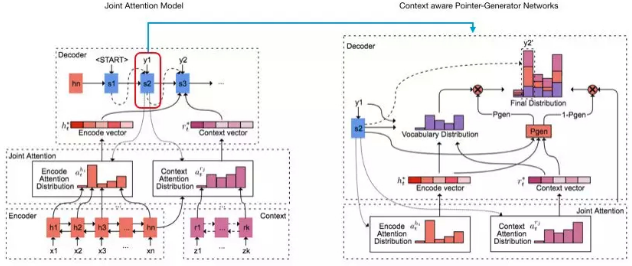
整个框架由encoder-decoder构成. 自底向上看,首先,我们对原始语料 $x_1, x_w, ..., x_n$ 和运营输入$z_1, z_2,...,z_n$ 分别做encode,其中原始语料逐词进入单层、双向LSTM网络,隐层向量表示为 $h_i$;运营输入可以是连续的一句话,也可以是关键词,若为前者,则仍然用LSTM处理,若为后者,则直接对关键词做embedding,用 $r_i$ 表示. 以i表示第i个输入,以t表示decode的步数,则attention的分布 $a_t$ 和context向量 $h_t^*, r_t^*$表示如下:
$$ e_t^{h_i} = \eta (s_t, h_i) $$
$$ e_t^{r_i} = \eta (s_t, r_i, h_n) $$
$$ a_t^{h_i} = softmax(e_t^{h_i}) $$
$$ a_t^{r_i} = softmax(e_t^{r_i}) $$
$$ h_t^* = \sum_{i=1}^n a_t^{h_i} h_i $$
$$ r_t^* = \sum_{i=1}^m a_t^{r_i}r_i $$
其中,η是一个以tanh为激活函数的多层MLP,表示第t步decoder的状态. attention分布可以看作是decode产生过程中,对encode每个源词的重视概率. $h_t^*$和 $r_t^*$ 是对attention分布的带权求和,是当前步下从源语句获得的信息的表达. 在此基础上,我们得到下一个词在整个词典上的概率分布:
$$ P_{vocab} = softmax(g([h_t^*, r_t^*, s_t], y_{t-1})) $$
其中,g为两层全连接. 这样我们就得到了generate部分的概率. 如何平衡pointing和generator呢?我们设计一个参数$p_{gen} \in [0, 1]$,它是一个概率软开关,和当前decoder的状态 $s_t$、context向量$h_t^*, r_t^*$、以及decoder输入$y_{t-1}$相关. 我们既可以在词典中generate下一个词,也可以利用attention的权重在输入中copy下一个词. 假设从 $P_{vocab}$ 中得到词典中每个词的预测概率为 $P_{vocab}(w)$,则:
$$ p_{gen} = \sigma(h_t^*, r_t^*, s_t, y_{t-1}) $$
$$ P(w) = p_{gen}P_{vocab}(w) + (1-p_{gen})(\sum_{i:w_i=w}a_t^{h_i} + \sum_{j:w_j=w}a_t^{r_j}) $$
其中σ是sigmoid函数. 现在的P(w)不但包括整个词典,还包括某些在输入中出现、但不在词典中的词,因此缓解了OOV的问题. 在训练阶段,假设第t个目标词为$w_t^*$,则loss表示为:
$$ loss_t = -log P(w_t^*) $$
$$ loss = \frac{1}{M} \sum_{t=0}^M loss_t $$
最后,我们加入了coverage算法解决重复词问题. 在每一步decode中,我们对之前步的所有attention分布求和,记为 $c_t$. $c_t$ 表现了当前为止,原输入中的词被attention体现出来的覆盖程度,它被带入到 $c_i$ 中进行计算,因此当前步的decoder将被通知并避免重复之前出现过的词. 此外,loss的计算中也引入covloss,它是 $a_i$ 和 $c_i$ 的最小值之和. coverage算法不仅作用在原始语料 $h_i$ 上,也作用于运营输入 $r_i$ 上. 由于我们的算法直接投放到线上,在做过算法的去重之后,我们在工程上最后还加了一层正则匹配,确保万无一失.
三. 滴搭工程平台
3.1. 算法平台XTF
为了能让整个滴搭平台真正面向运营,我们需要一个稳定、能支持快速迭代和实时计算的机器学习平台来支撑我们训练模型以及在线输出.
为此,我们参与了工程团队的共建工作——基于Porsche blink的分布式Tensorflow训练及在线打分平台,我们称该平台为 XTensorflow,简称XTF. 在这个平台上,滴搭涉及到的LSTM模型、CNN模型、CPGN模型、DAN模型天级别地训练与更新,快速响应训练数据的变化;在线预测过程中,共建了CNN的实时打分、context graph的实时查询、DSSM的实时检索,使得业务的实时响应成为可能.

3.2. 智能排版平台
算法生成的搭配最终投放给用户,图片的美观非常重要. 这里面急需解决多商品的排版问题,包括大小比例、顺序、页面留白等等. 鹿班团队在合图工程上有着多年的经验,我们共建了搭配商品的排版工作,完成了成图的最后一步.
滴搭布局算法支持设计师上传模板,也可以根据积累的模板进行合图匹配.
四. 滴搭业务实例
滴搭的图文算法本身是很底层且通用的,它可以应用于所有拥有多商品逻辑关系的行业,可以投放于所有有场景定义的业务中. 我们在日常业务和大促业务中都有过很多次的合作与尝试,接下来将重点介绍几个.
4.1. iFashion搭配
iFashion是一个以搭配为主要心智的场景. 无论是在内容质量本身,还是视觉呈现,iFashion都很好地承接了图文算法的产出. 我们周期性地为iFashion的选品产出图搭配和文字描述,极大地补充了原仅有达人搭配的池子. 算法搭配和达人搭配在瀑布流中混排,个性化地推荐给用户. 算法搭配参与生产的优势包括成本低、成品效果好、转化数据高等等.
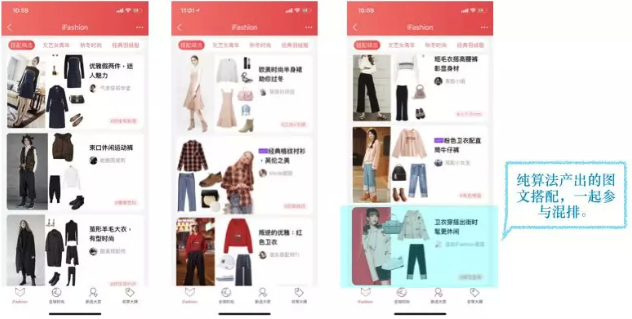
4.2. 手淘首焦
手淘首焦是一个强运营需求区块,一张焦点图背后是一个活动页,展现内容包括该活动下的商品图片以及文案. 我们的推荐算法会给用户千人千面的展现,即在个性化投放中,我们会给每个用户投放他感兴趣活动下的感兴趣内容. 在图文算法产生之前,我们仅仅对活动下的单个商品做了个性化,而且文案还是固定不变的.
我们尝试了服饰行业的多商品搭配,搭配的组合态使得首焦的图片展示更加丰富,不再拘泥于单商品的模式.

我们也尝试了多行业的文案生产. 以下图为例,传统的做法,运营输入固定文案,包括主文案:运动健身狂欢购,副文案:大牌精选好货钜惠,以及利益点:抢大额券. 固定文案千篇一律,很容易被忽视. 在我们的模型中,原始语料是商品标题、描述、属性等等. (该例中,是瑜伽砖头的相关信息. ),运营输入的是文案词和利益点. (该例中,运营输入了精选好货、大牌、狂欢购等等关键词. ). 最后产出的智能文案,主文案:瑜伽砖头精选好货. (分别从商品标题和运营输入中抽词. ),副文案:大牌钜惠满就减. (从运营输入中抽词,并衍生出了“满就减”. ). 由于我们产出的文案能够和商品、活动一一对应,因此文案上也是千人千面的,不但描述了用户感兴趣的这个商品,还突出了活动的特点,使得个性化的效率得到了提升.
在首焦的图文生产上,我们在CTR和UCTR上都拿到了超过两位数的提升.

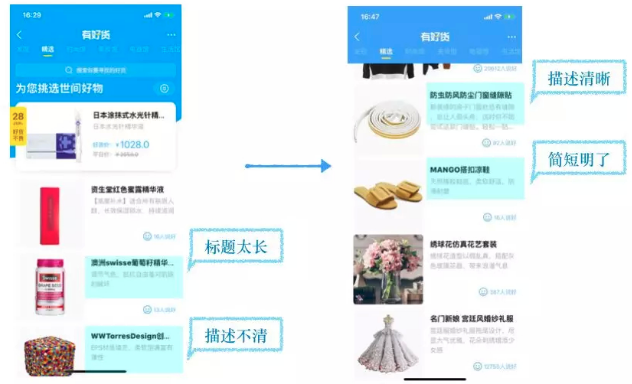
4.3. 有好货
有好货是首页流量主力频道,其主打的“好货”心智深入人心. 目前的版本中,由于排版的限制,达人生产的标题有的太长,显示不全,有的由于截断,表述不清,非常影响用户对商品的信息读取. 我们和有好货合作,利用文案算法,对标题进行重新抽取,在限制长度的情况下提取重点信息,帮助用户更好地决策.
五. 未来工作
我们的算法工作、工程工作是紧跟着业务发展的,所以很多的想法也是深入了解业务之后思考建设起来的. 接下来也有一些想要尝试的方向:
首先,我们希望建设一个端到端的算法模型. 现在由于图像网络比较重,模型中还是用CNN进行预处理,再到 LSTM或者DAN网络中产出的. 我们希望以后图像的处理网络能够融入到整体框架中.
其次,我们希望能够在个性化上做更多的努力,配合产出更多的UGC内容玩法.
欢迎与我们交流
阿里巴巴推荐算法团队目前主要负责阿里电商平台(包括淘宝、天猫、海外版淘宝、Lazada等)的商品及feeds流推荐,其中手机淘宝首图个性化、猜你喜欢、购买链路等场景每天服务数亿用户,涉及流量效率提升、用户体验、提高商家及达人参与淘宝的积极性,优化商业生态运行机制.
参考文献
[1] - Li Y, Cao L, Zhu J, et al. Mining fashion outfit composition using an end-to-end deep learning approach on set data[J]. IEEE Transactions on Multimedia, 2017, 19(8): 1946-1955.
[2] - Han X, Wu Z, Jiang Y G, et al. Learning fashion compatibility with bidirectional lstms[C]//Proceedings of the 2017 ACM on Multimedia Conference. ACM, 2017: 1078-1086.
[3] - Tautkute I, Trzcinski T, Skorupa A, et al. DeepStyle: Multimodal Search Engine for Fashion and Interior Design[J]. arXiv preprint arXiv:1801.03002, 2018.
[4] - Song X, Feng F, Han X, et al. Neural Compatibility Modeling with Attentive Knowledge Distillation[J]. arXiv preprint arXiv:1805.00313, 2018.
[5] - Gardner A, Kanno J, Duncan C A, et al. Classifying Unordered Feature Sets with Convolutional Deep Averaging Networks[J]. arXiv preprint arXiv:1709.03019, 2017.
[6] - See A, Liu P J, Manning C D. Get to the point: Summarization with pointer-generator networks[J]. arXiv preprint arXiv:1704.04368, 2017.
[7] - Wu Y, Wu W, Yang D, et al. Neural Response Generation with Dynamic Vocabularies[J]. arXiv preprint arXiv:1711.11191, 2017.