作者:George Seif
编译:ronghuaiyang - AI 公园
不是所有的数据都是完美的.
实际上,如果你拿到一个真实的完全均衡的数据集的话,那你真的是走了狗屎运了. 大部分的时候,你的数据都会有某种程度上的不均衡,也就是说你的数据集中每个类别的数量会不一样.
1. 为什么想要数据是均衡的?
在我们开始花时间做深度学习项目之前,非常重要的一点是需要理解为什么我们要做这个事情,确保我们的投入是值得的. 当我们真正关心的是少数的类别的时候,类别均衡技术就是真正的必须的了.
比如说,我们想预测基于当前的市场情况,房子的属性,自己的预算,是否应该买房子. 在这种情况下,如果我们买了,那么这是个正确的决定是非常重要的,因为这个是很大的一笔投资. 同时,如果你的模型说不要买,而事实上需要买的话,这也没什么大不了的. 你错过了这个,总是有其他的房子可以买的. 但是如果买错了的话,那就是个大事了.
在上面的情况中,我们当然需要我们的少数“买”的类别要特别的准确,而“不买”的类别则无关紧要. 但是在实际情况中,由于买的情况比不买的情况要少得多,我们的模型预测会偏向“不买”的类别,而“买”的类别的准确率则可能会很差. 这就需要数据均衡了,我们可以让“买”类别的权重变大,来让“买”类别的预测更加准确.
但是如果我们对少数类别不关心怎么办呢?例如,我要做一个图像的分类,而你的类别的分布看起来是这样的:
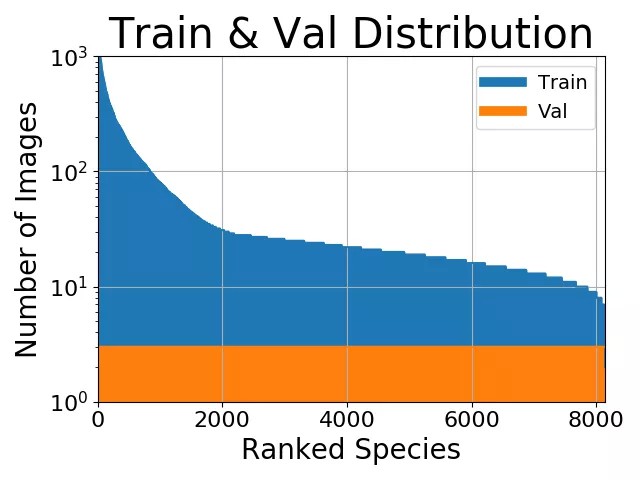
第一眼看上去似乎数据均衡是有好处的. 但是也许我们对那些少数的类别并不关心. 也许我们的目的就是得到最高的准确率.
在这种情况下,做数据均衡并没什么意义,因为大多数的准确率来自于包含了大量样本的类别中.
第二,交叉熵的损失即使是在不均衡的数据的时候,也是趋向于得到最高的准确率.
总的来说,我们的少数类别并没有对准确率有多少贡献,所以说,数据均衡并不需要.
综上所述,当我们遇到需要均衡数据的时候,有两个方法可以帮助我们办到:
1.1 权值均衡
权值均衡是在训练样本的时候,在计算loss的时候,通过权值来均衡数据的分布.
正常情况下,每个类别在损失函数中的权值是1.0. 但是有时候,当某些类别特别重要的时候,我们需要给该类别的训练样本更大权值.
参考我们的买房的例子,由于“买”的类别的准确率非常的重要,训练样本中的这个类别应该对损失函数有更大的影响.
可以直接给对应的类别的样本的loss乘上一个因子来设定权值.
在Keras中,我们可以这样:
import keras
class_weight = {"buy": 0.75, "don't buy": 0.25}
model.fit(X_train, Y_train, epochs=10, batch_size=32, class_weight=class_weight)我们创建了一个字典,其中,“买”类别为75%,表示了占据了75%的loss,因为比“不买”的类别更加的重要,“不买”的类别设置成了25%. 当然,这两个数字可以修改,直到找到最佳的设置为止. 我们可以使用这种方法来均衡不同的类别,当类别之间的样本数量差别很大的时候.
我们可以使用权值均衡的方式来使我们的所有的类别对loss的贡献是相同的,而不用取费力的收集少数类别的样本了.
另一个可以用来做训练样本的权值均衡的是Focal loss. 如下所示,主要思想是这样:
在数据集中,很自然的有些样本是很容易分类的,而有些是比较难分类的. 在训练过程中,这些容易分类的样本的准确率可以达到99%,而那些难分类的样本的准确率则很差. 问题就在于,那些容易分类的样本仍然在贡献着 loss,那我们为什么要给所有的样本同样的权值?
这正是Focal loss要解决的问题. focal loss 减小了正确分类的样本的权值,而不是给所有的样本同样的权值. 这和给与训练样本更多的难分类样本时一样的效果. 在实际中,当我们有数据不均衡的情况时,我们的多数的类别很快的会训练的很好,分类准确率很高,因为我们有更多的数据. 但是,为了确保我们在少数类别上也能有很好的准确率,我们使用focal loss,给与少数类别的样本更高的权值.
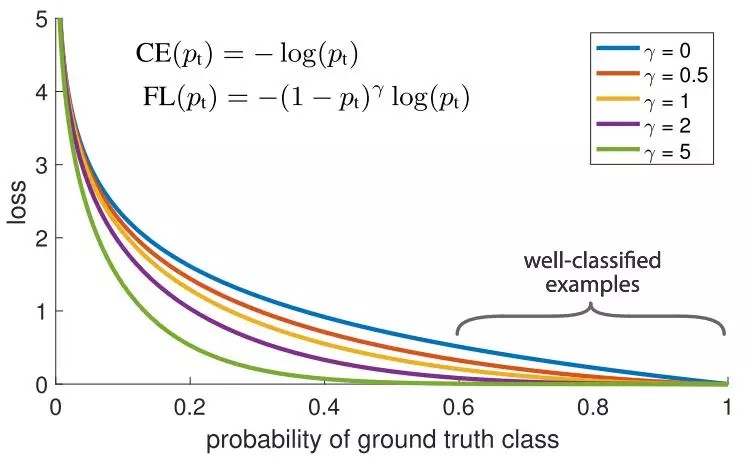
focal loss使用Keras是很容易实现的:
import keras
from keras import backend as K
import tensorflow as tf
# Define our custom loss function
def focal_loss(y_true, y_pred):
gamma = 2.0, alpha = 0.25
pt_1 = tf.where(tf.equal(y_true, 1), y_pred, tf.ones_like(y_pred))
pt_0 = tf.where(tf.equal(y_true, 0), y_pred, tf.zeros_like(y_pred))
return -K.sum(alpha * K.pow(1. - pt_1, gamma) * K.log(pt_1))-K.sum((1-alpha) * K.pow( pt_0, gamma) * K.log(1. - pt_0))
# Compile our model
adam = Adam(lr=0.0001)
model.compile(loss=[focal_loss], metrics=["accuracy"], optimizer=adam)Focal Loss 论文理解及公式推导
1.2 过采样和欠采样
选择合适的类别的权重有时候比较复杂.
做一个简单的频率倒数可能有时候效果也不好.
Focal loss有点用,但是仍然会对所有的正确分类的样本都做权值的下降.
另外一个数据均衡的方法就是直接的采样. 下面的图给出了一个大概的说明.
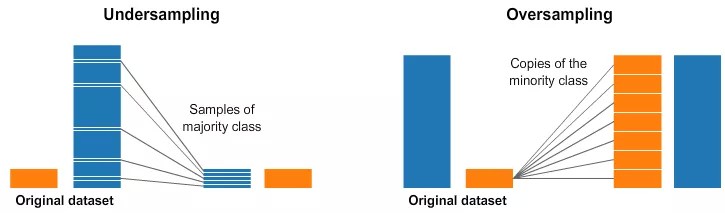
在图像的两边,蓝色的类别比橘黄色的类别的样本多得多. 这种情况下,我们在预处理时,有两种选择:
[1] - 欠采样意思是从多数的类别中只采样其中的一部分的样本,选择和少数类别同样多的样本. 这种采样保持了该类别原来的数据分布. 这很容易,我们只需要少用点样本就可以让数据变得均衡.
[2] - 过采样的意思是我们复制少数类别中的样本,使得数量和多数样本一样多. 复制操作需要保持少数样本的原有的数据分布. 我们不需要获取更多的数据就可以让数据集变得均衡.
采样的方法是一个很好的类别均衡的方法,如果你发现类别权值很难做而且效果不好的时候,可以试试!
本文可以任意转载,转载时请注明原文作者及原文地址.
1 条评论
非常好的文章,受教了,谢谢