题目:Semantic Human Matting - ACMMM2018
作者:Quan Chen, Tiezheng Ge, Yanyu Xu, Zhiqiang Zhang, Xinxin Yang, Kun Gai
团队:Alibaba, ShanghaiTech University
论文主要针对的是人体抠图问题,创建数据集和提出 Semantic Human Matting(SHM) 方法.
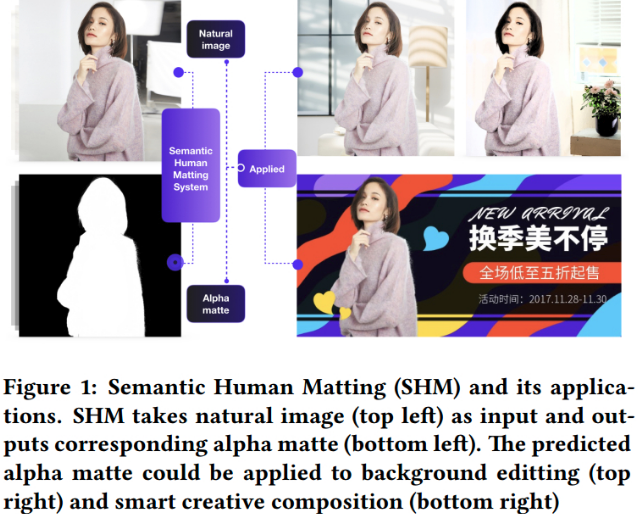
1. 人体抠图数据集
抠图数据集的创建主要采用了两种方式:
[1] - 服装模型(Fashion Model)数据集
主要是从电商网站收集了超过 188k 张服装图片,并由店铺卖家根据商业需要的质量来标注图片的透明图(alpha mattes).移除带瑕疵的图片,耗时 1200 小时,最终得到 35311 张标注的图片.
[2] - Deep Image Matting(DIM) 数据集
从 DIM 中只选取包含人体的图片,得到 202 张前景.
论文阅读 - Deep Image Matting
每个前景目标由 N 个背景来构建扩充的抠图数据集.
对于 Fashion Model 数据集,N=1,即每张前景图片组合一个背景图片;
对于 DIM 数据集,N=100,即每张前景图片随机放置于 100 张背景图片,以构建 100 张图片数据.
最终,得到 52511(35311 + 202 * 100) 张训练图片,1400 张测试图片.

现有抠图数据集对比:

2. SHM 语义人体抠图方法
SHM 抠图的目标是,自动生成人体目标的 alpha matte.
如图:
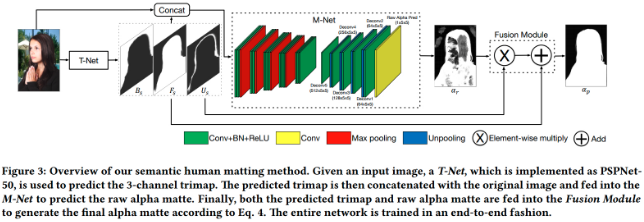
SHM 采用 RGB 3通道图片作为输入,直接输出尺寸一致的 1 通道 alpha matte 图片. 其中,不需要附加信息,如 trimap 和 scribbles.
SHM 旨在同时学习粗糙的语义类别信息和精细的 matting 细节信息. 其中,
[1] - T-Net:像素级的分类问题,每个像素属于前景(foreground),背景(background) 和未知区域(unknown regions) 三类之一.
主要用于语义分割,以提取前景区域.
T-Net 的输出是 3-channel 的特征图,分别表示了每个像素属于 3 个类别的概率.T-Net 采用的是语义分割中的方法,这里采用的是 PSPNet-50.
[2] - M-Net:采用 T-Net 的输出作为语义输入,并通过生成粗糙的 alpha matte 图片来描述人体目标细节信息.
M-Net 采用原始的 3-channel RGB 图片和 T-Net 输出的 3-channel 分割结果,组合为 6-channel 的输入.
(实际上 M-Net 的 6-channel 输入与 DIM 的 4-channel 输入,得到的网络结果基本上一样.)
M-Net 是编码-解码(encoder-decoder) 网络. encoder 网络有 13 个卷积层和 4 个 max-pooling 层;decoder 网络有 6 个卷积层和 4 个 unpooling 层.
M-Net 的 encoder 网络的参数量与 VGG16 分类网络的卷积层参数量相同,除了 VGG16 网络的输入是 3-channel,而 M-Net 的输入是 6-channel.
M-Net 与 DIM 网络的不同之处在于:M-Net 网络的输入是 6-channel,而 DIM 网络的输入是 4-channel;M-Net 在每个卷积层后加入 Batch Normalization 层,以加速收敛;DIM 的 conv6 和 deconv6 网络层因为有大量的参数,容易过拟合,因此进行了移除.
[3] - Fusion Module:融合 T-Net 和 M-Net 的输出,生成最终的 alpha matte 结果.
2.1. 融合模块 Fusion Module
Fusion Module 主要为了融合 T-Net 输出的前景背景语义信息和 M-Net 输出的结构(structure)和纹理(textural)细节信息,以得到精细的 alpha matte.
记 T-Net softmax 层前的预测输出的前景(foreground),背景(background) 和未知区域(unknown region) 分别为:${F}$,${B}$,${U}$.
前景 ${F_s}$ 的概率图可以表示为:
$$ F_s = \frac{exp(F)}{exp(F) + exp(B) + exp(U)} $$
类似地,${B_s}$ 和 ${U_s}$ 可以表示为相同的形式.
${F_s + B_s + U_s = \mathbf{1}}$ (与输入图片尺寸相同的矩阵,矩阵每个元素值都是 1).
记 M-Net 的输出为 ${\alpha_r}$.
预测的 trimap 表示了每个像素属于前景,背景和未知区域三类的概率.
当像素位于未知区域之内时,则该像素靠近于人体的轮廓,构成着人体的复杂结构部分,如头发等,matting 时需要重点处理,以精确得到 alpha matte. 此时则采用 matting 网络的输出 ${\alpha_r}$ 作为精确的预测.
当像素位于未知区域之外时,则像素属于前景的条件概率,可以计算为 matte 的逼近估计,如 ${\frac{F_s}{F_s + B_s}}$.
因为 ${U_s}$ 是每个像素属于未知区域的概率,因此,所有像素的 alpha matte 的概率估计为:
$$ \alpha_p = (\mathbf{1} - U_s) \frac{F_s}{F_s + Bs} = U_s \alpha_r $$
其中,${\alpha_p}$ 表示 Fusion Module 的输出.
由 ${F_s + B_s = 1 - U_s}$,有:
$$ \alpha_p = F_s + U_s \alpha_r $$
当 ${U_s}$ 接近于 1,${F_s}$ 接近于 0,则,${\alpha_p}$ 是由 ${\alpha_r}$ 来逼近.
当 ${U_s}$ 接近于 0,${\alpha_p}$ 是由 ${F_s}$ 来逼近.
2.2. Loss 函数
loss 主要有 alpha 预测 loss 和 compositional loss 两种组成.
alpha 预测 loss 定义为 groundtruth alpha ${\alpha_g}$ 和预测 alpha ${\alpha_p}$ 间的绝对差值.
compositional loss 定义为 groundtruth compositional 图片值 ${c_g}$ 和预测图片值 ${c_p}$.
每个像素的整体预测 loss 为:
$$ \mathcal{L}_p = \gamma ||\alpha_p - \alpha_g||_1 + (1 - \gamma)||c_p - c_g||_1 $$
其中,${\gamma = 0.5}$.
最终的 loss 为:
$$ \mathcal{L} = \mathcal{L}_p + \lambda \mathcal{L}_t $$
其中,${\mathcal{L}_t}$ 为分类 loss,${\lambda} = 0.01$.
3. 实现细节
[1] - T-Net 训练:基于 ResNet50 的 PSPNet50,输入图片尺寸为 400x400. 采用的是交叉熵损失函数(cross entropy loss),${\mathcal{L}_t}$.
[2] - M-Net 训练:其输入为 3-channel 图片 3-channel trimap 组成的 6-channel. 其中,trimap 是采用对 groundtruth alpha mattes 进行膨胀(dilate)和腐蚀(erode) 得到. 不同的膨胀和腐蚀 kernel 尺寸得到的 trimap 对于 Matting 的结果十分重要. 输入为 320x320.
[3] - End-to-end 训练:采用训练的 T-Net 和 M-Net 进行初始化. 图片裁剪尺寸为 800x800 作为 T-Net 的输入,得到语义预测结果. 随机裁剪不同的图片块(320x320, 480x480, 640x640),并调整尺寸为 320x320 作为 M-Net 的输入.
实际上,为了不损失图像的分辨率,大图像是在 CPU 上进行测试的. GPU 显存限制.
4. Results



实际上论文里主要是对图片中的人体进行精细抠图,但方法方面主要是结合两个语义分割模型,如 PSPNet50 和 Encoder-Decoder(如,SegNet),最后是融合语义分割模型的输出.