题目:Cascaded Pyramid Network for Multi-Person Pose Estimation - CVPR2018
作者:Yilun Chen∗ Zhicheng Wang∗ Yuxiang Peng1 Zhiqiang Zhang2 Gang Yu Jian Sun
团队:Tsinghua University, HuaZhong University of Science and Technology, Megvii Inc. (Face++)
任务场景为多人姿态估计.
多人姿态估计所面临的挑战,关键点遮挡,关键点不可见,复杂背景等.
提出的 Cascaded Pyramid Network (CPN) 方法,即着重于处理 “困难hard” 关键点.
CPN 包括两阶段网络:GlobalNet 和 RefineNet
[1] - GlobalNet - 特征金字塔网络(feature pyramid network),用于定位估计 “简单simple” 关键点,比如,eyes 和 hands;但难以精确识别遮挡或不可见的关键点.
[2] - RefineNet - 通过将 GlobalNet 得到的所有层次的特征表示整合一起,并结合在线困难关键点挖掘loss(online hard keypoint mining loss),定位检测 “困难hard” 关键点.
一般情况下,多人姿态估计问题的解决方案是 top-down 的,即,首先采用检测器检测人体边界框;然后采用关键点估计方法估计每个人体边界框内的人体关键点. CPN 算法即是对每个人体边界框内进行关键点估计.
此外,CPN 还探索了其它可能影响多人关键点估计的其它因素,比如人体检测器,数据预处理等.
1. 多人关键点估计
主要包括两部分,
[1] - 人体边界框检测 Human Detector
[2] - 关键点估计 CPN
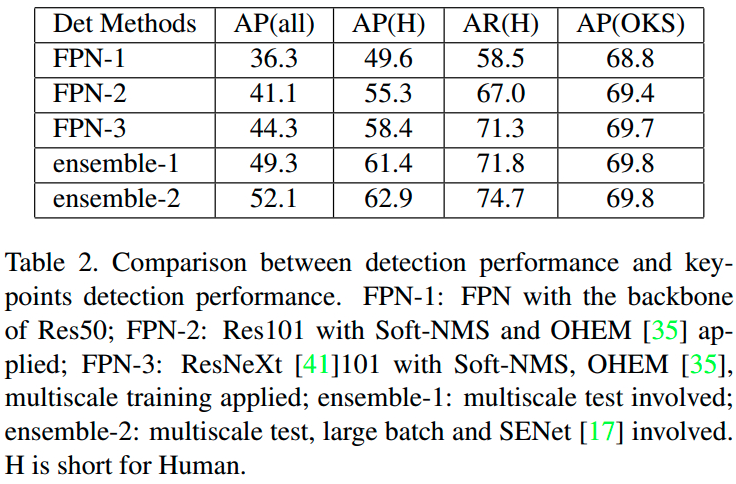
1.1. 人体边界框检测
直接采用基于 FPN 目标检测算法. 其中,采用 Mask R-CNN 中的 ROIAlign 替换 FPN 的 ROIPooling.
目标检测器训练时,使用了 COCO 数据集的全部 18 个类别;但只有人体类别的边界框被用于多人关键点估计任务.

1.2. CPN
单人姿态估计算法:
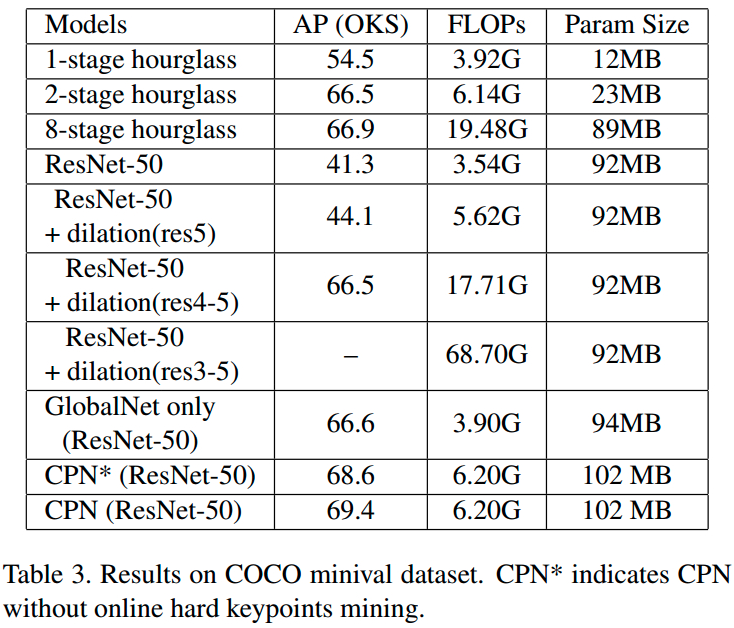
[stacked hourglass] - 堆叠 8 个 hourglass,每个 hourglass 由下采样,上采样,以及残差连接组成;但,实际上堆叠 2 个 hourglass 模块,则足以达到与 8 个 hourglass 模块相当的效果.
CPN(cascaded pyramid network) 网络如图Fig 1:
主要包括两个子网络:
[1] - GlobalNet
基于 ResNet backbone.
记不同的 conv 特征的最后一个残差模块分别为 C2,C3,C4,C5. 在 C2 - C5 后接 3x3 conv 核,以生成关键点的 heatmaps.
如图 Fig 2 中,C2 和 C3 的 feature maps 分辨率较大,但语义信息较少. 而 C4 和 C5 的 feature maps 语义信息较多,但分辨率较低(由于卷积步长和 pooling 的作用).
因此,一般采用 U-型 结构同时保持特征层的空间分辨率和语义信息. 而 FPN 进一步提升.
GlobalNet 采用类似于 FPN 的特征金字塔结构,进行关键点估计. 与 FPN 的不同之处在于,GlobalNet 上采用时,在每个 elem-sum 前添加了 1x1 conv 核.
Fig 2 可知,基于 ResNet backbone 的 GlobalNet 可以有效的定位简单的关键点,如 eyes,但没有精确定位置 hips 关键点的位置. 因此,需要更多的上下文信息.
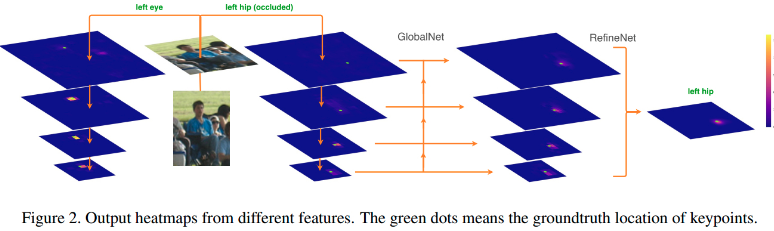
[2] - RefineNet
基于 GlobalNet 生成的特征金字塔表示,再添加 RefineNet,定位 “hard” 关键点.
RefineNet 利用了不同层的特征信息,并通过类似于 HyperNet 的上采样和链接,整合不同层的特征信息.
stacked Hourglass 网络仅利用了 hourglass 模块尾部输出的上采样特征,而 RefineNet 链接了所有层的金字塔特征.
2. 实验
COCO trainval 数据集,57K 张图片,15K 人体实例. (training)
COCO minival 数据集,5K 张图片. (validation)
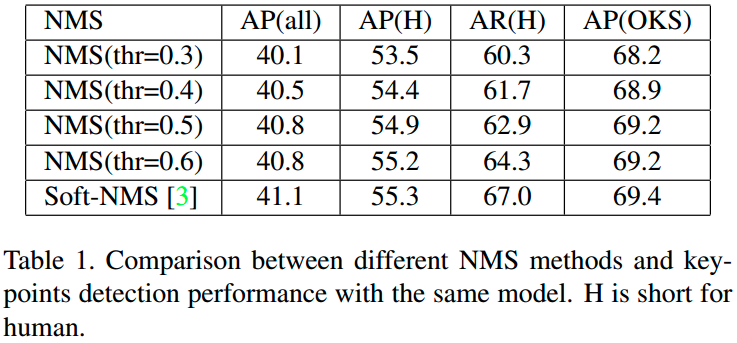
技巧:
裁剪策略:
对于每个人体检测边界框,扩展到保持固定的长宽比,如 height:width = 156:192;
然后不改变长宽比的进行裁剪;
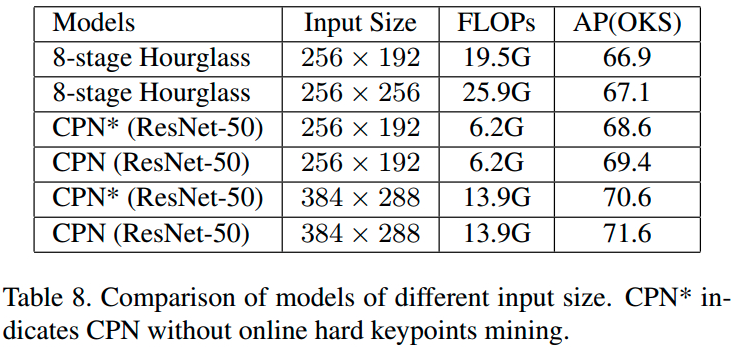
最后,将裁剪的图片 resize 到固定尺寸:height - 256 pixels;width - 192 pixels.
数据增强策略:
数据增强对于尺度不变性和旋转不变性很重要.
图片裁剪后,随机翻转(random flip),随机旋转(random rotation, -45 ~ + 45),随机尺寸变换(random scale, 0.7-1.35).
训练细节:
Adam 算法.
初始学习率 5e-4. 每 360000 次迭代,学习率减少 2x.weight decay = 5.
batchsize = 32.
BatchNormalization.
在 8 张 Titan X GPUs 上,ResNet50 模型的训练耗时 1.5 天左右.
采用 ImageNet 预训练模型进行参数初始化.
测试细节:
预测的 heatmaps 进行 gaussian filter 处理,最小化预测方差.
同时预测翻转图片的关键点估计,平均化 heatmaps 得到最终预测结果.
使用从最高响应到第二最高响应的方向上的四分之一偏移量来作为关键点的最终位置(a quarter offset in the direction from the highest response to the second highest response is used to obtain the final location of the keypoints.)
重新定位策略(Rescoring):人体框的 score 和所有关键点的平均 score 的乘积作为人体实例的最终 score.
2.1. Results