竞赛:MICCAI 2017 Robotic Instrument Segmentation Sub-Challenge
基于 U-Net,TernausNet-11, TernausNet-16,LinkNet-34 的高分辨率语义分割.Github项目 - robot-surgery-segmentation
Paper - Automatic Instrument Segmentation in Robot-Assisted Surgery Using Deep Learning - 2018
该项目主要描述对于竞赛 [MICCAI 2017 Endoscopic Vision Sub-Challenge: Robotic Instrument Segmentation] 的解决方案. 原始方案基于 U-Net 网络结构,采用 LinkNet 和 TernausNet 来提升了语义分割结果.
对于二类(binary) 和多类(multi-class) 的机器人仪器分割(robotic instrument segmentation) 取得优秀的分割结果.
对于医学的手术场景,能够很好的进行追踪和姿态估计.
概述
机器人仪器的语义分割是在机器人辅助医学领域中很重要的研究问题.
一个最重要的挑战是,手术场景中仪器位置的正确检测,以进行追踪和姿态估计.
精确的像素级仪器分割有待解决.
该项目采用神经网络结构取得了较为优秀的分割表现.
其主要处理二值语义分割问题,手术视频流中,图像每个像素被标注为仪器类或背景类(非仪器类).
另外,还解决多类分割问题(multi-class segmentation),对不同的机器人仪器和一个仪器的不同部分(包括背景类) 进行语义分割区分.
该项目的解决方案中,在机器人仪器分割的每个子任务中均取得了突出表现.
数据
训练数据集包括 8x255-帧高分辨率相机图像序列,由 da Vinci Xi 外科系统 在几个不同的手术场景中捕捉得到.
训练数据集序列以 2 Hz 帧率,避免冗余.
每个视频序列有两个立体通道组成,分别有左相机和右相机拍摄,为 1920x1080 分辨图的 RGB 图像.
机器人医学仪器的铰链部分,例如 rigid shaft(刚性轴),articulated wrist(铰接手腕) 和 claspers(扣环),分别在每一帧进行了手工标注.
此外,还包括仪器类型标签,将仪器划分为几类:left/right prograsp forceps, monopolar curved scissors, large needle driver, 和 a miscellaneous category for any other surgical instruments(其它手术器械的杂类).
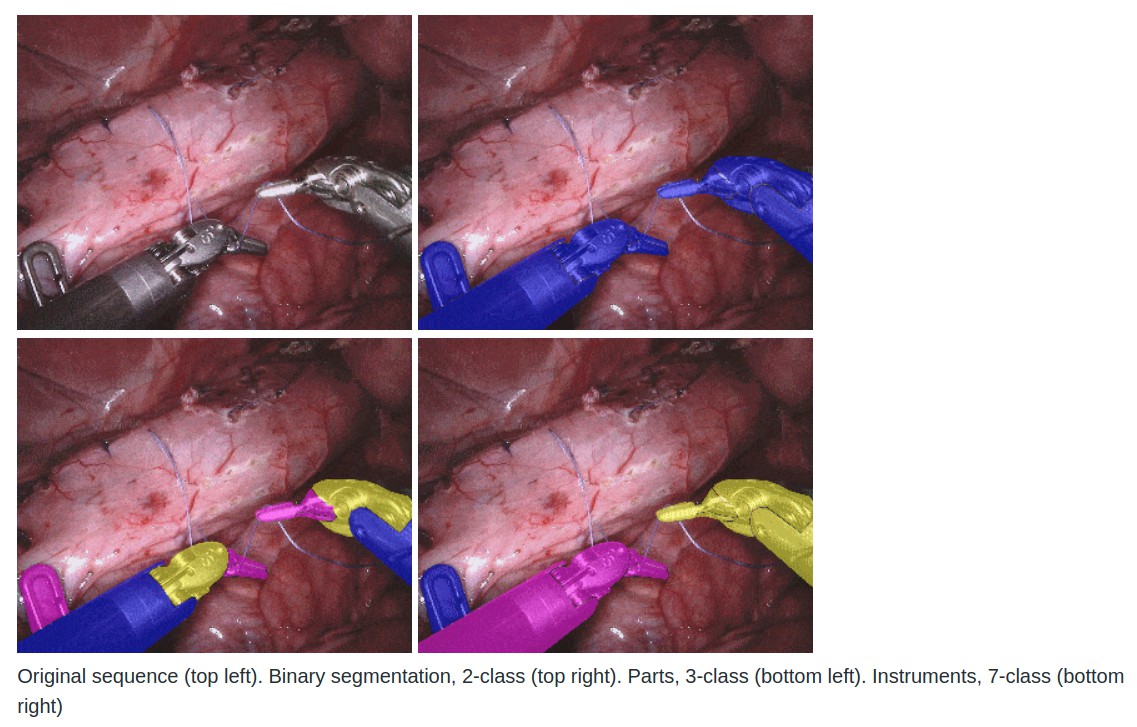
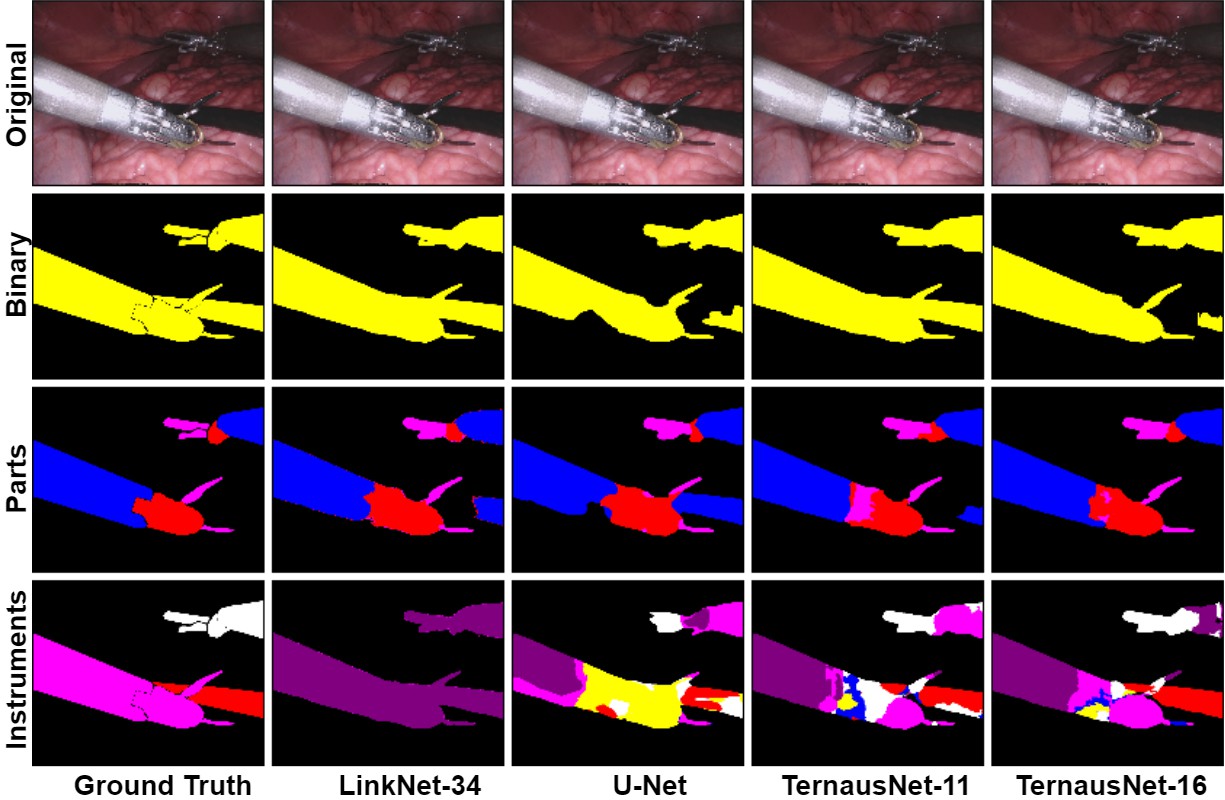
原图序列 - 二值分割(2 类) - Parts(3 类) - Instruments(7 类)
方法
项目采用了 4 个不同的语义分割网络:U-Net,TernausNet 的两个改进网络,LinkNet 的改进网络.
语义分割网络模型的输出是像素级的 mask,分别对每一个像素进行了分类.
MICCAI 2017 Endoscopic Vision Sub-Challenge 提交的版本采用的是 U-Net 网络的轻微改进版本.
作为 U-Net 的提升版,采用了类似的网络作为预训练的编码器(encoders). TernausNet 是 U-Net 类型的网络结构,采用了相对简单的预训练 VGG11 和 CGG16 网络作为编码器.
LinkNet 模型采用 ResNet 类型的网络结构作为编码器. 这里采用了预训练的 ResNet34.
网络编码器包括几个解码器(decoder) 模块,每个解码器模块与对应的解码器模块相连接. 每个编码器模块包含 1x1 卷积层,以减少 filters 的数量为 1/4,其后接 Batch Normalization 和 Transposed Convolution 层,以上采样 feature map:
训练
采用 Jaccard Index(Intersection Over Union,IoU) 作为评价度量. 其可以解释为,有限集间的相似度量.
对于两个集 A 和 B,Jaccard Index 定义为: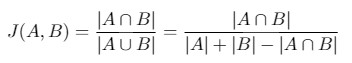
由于图像有像素组成,Jaccard Index 可以转换为: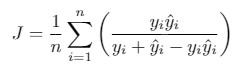
${y_i}$ 和 ${\hat{y}_i}$ 分别为第 i 个像素的 groundtruth 二值标签和预测的概率值.
由于图像语义分割任务还可以看作像素分类问题,因此,新增了通用分类 loss 函数,记为 H.
对于二值分割问题,H 是二值交叉熵损失函数(binary cross entropy).
对于多类(multi-class) 分割问题,H 是类别交叉熵损失函数(categorical cross entropy).
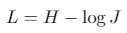
作为模型的输出,会得到一张 mask 图片,其每一个像素值对应了属于某个类别的概率值.
输出图片尺寸与输入图片尺寸相匹配.
对于二值分割,采用 0.3 作为阈值来进行二值化像素概率值. 小于阈值 0.3 的像素设为 0. 大于阈值的像素设为 255,作为最终的预测 mask.
对于 multi-class 分割,采用类似的方法,但是对于每一类设置为不同的整数.
Results
对于二值分割,最佳的结果是 TernausNet-16,其 IoU=0.836,Dice=0.901.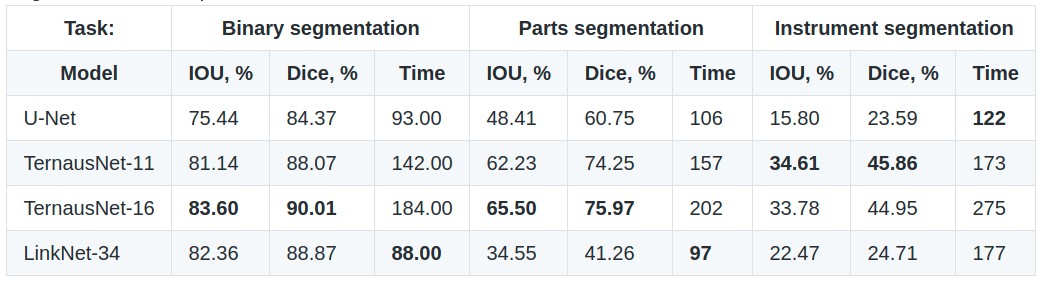
预训练的模型 - models-googledrive
项目运行
依赖项:
- Python 3.6
- PyTorch 0.4.0
- TorchVision 0.2.1
- numpy 1.14.0
- opencv-python 3.3.0.10
- tqdm 4.19.4
如:
sudo pip install pytorch==0.4.0数据集组织
数据集文件夹形式:
├── data
│ ├── cropped_train
│ ├── models
│ ├── test
│ │ ├── instrument_dataset_1
│ │ │ ├── left_frames
│ │ │ └── right_frames
| | .......................
│ └── train
│ ├── instrument_dataset_1
│ │ ├── ground_truth
│ │ │ ├── Left_Prograsp_Forceps_labels
│ │ │ ├── Maryland_Bipolar_Forceps_labels
│ │ │ ├── Other_labels
│ │ │ └── Right_Prograsp_Forceps_labels
│ │ ├── left_frames
│ │ └── right_frames
│ .......................训练数据集只包含 8 个 videos,每个 video 包含 225 帧. 在每个 video 内,所有的帧是相关的,因此,实验中采用 4-fold 交叉验证.
数据预处理
- prepare_data.py,合并不同 instruments 标注的 masks 为一个二值 mask;从图像和对应的 masks 裁剪空白边界.
- prepare_train_val.py,数据集划分,4-fold 交叉验证.
模型训练.
- train.py,模型训练主文件.
python3 train.py --help 返回所有的可输入参数.
import argparse
import json
from pathlib import Path
from validation import validation_binary, validation_multi
import torch
from torch import nn
from torch.optim import Adam
from torch.utils.data import DataLoader
import torch.backends.cudnn as cudnn
import torch.backends.cudnn
from models import UNet11, LinkNet34, UNet, UNet16, AlbuNet ## 网络结构
from loss import LossBinary, LossMulti ## Loss 函数
from dataset import RoboticsDataset ## 数据集类
import utils
from prepare_train_val import get_split
from albumentations import (
HorizontalFlip, VerticalFlip, Normalize, Compose ) ## 数据增强库
def main():
parser = argparse.ArgumentParser()
arg = parser.add_argument
arg('--jaccard-weight', default=0.5, type=float)
arg('--device-ids', type=str, default='0', help='For example 0,1 to run on two GPUs')
arg('--fold', type=int, help='fold', default=0)
arg('--root', default='runs/debug', help='checkpoint root')
arg('--batch-size', type=int, default=1)
arg('--n-epochs', type=int, default=100)
arg('--lr', type=float, default=0.0001)
arg('--workers', type=int, default=12)
arg('--type', type=str, default='binary', choices=['binary', 'parts', 'instruments'])
arg('--model', type=str, default='UNet', choices=['UNet', 'UNet11', 'LinkNet34', 'AlbuNet'])
args = parser.parse_args()
root = Path(args.root)
root.mkdir(exist_ok=True, parents=True)
if args.type == 'parts':
num_classes = 4
elif args.type == 'instruments':
num_classes = 8
else:
num_classes = 1
if args.model == 'UNet':
model = UNet(num_classes=num_classes)
elif args.model == 'UNet11':
model = UNet11(num_classes=num_classes, pretrained=True)
elif args.model == 'UNet16':
model = UNet16(num_classes=num_classes, pretrained=True)
elif args.model == 'LinkNet34':
model = LinkNet34(num_classes=num_classes, pretrained=True)
elif args.model == 'AlbuNet':
model = AlbuNet(num_classes=num_classes, pretrained=True)
else:
model = UNet(num_classes=num_classes, input_channels=3)
if torch.cuda.is_available():
if args.device_ids:
device_ids = list(map(int, args.device_ids.split(',')))
else:
device_ids = None
model = nn.DataParallel(model, device_ids=device_ids).cuda()
if args.type == 'binary':
loss = LossBinary(jaccard_weight=args.jaccard_weight)
else:
loss = LossMulti(num_classes=num_classes, jaccard_weight=args.jaccard_weight)
cudnn.benchmark = True
def make_loader(file_names, shuffle=False, transform=None, problem_type='binary', batch_size=1):
return DataLoader(
dataset=RoboticsDataset(file_names, transform=transform, problem_type=problem_type),
shuffle=shuffle,
num_workers=args.workers,
batch_size=batch_size,
pin_memory=torch.cuda.is_available()
)
train_file_names, val_file_names = get_split(args.fold)
print('num train = {}, num_val = {}'.format(len(train_file_names), len(val_file_names)))
def train_transform(p=1):
return Compose([VerticalFlip(p=0.5), HorizontalFlip(p=0.5),
Normalize(p=1)], p=p)
def val_transform(p=1):
return Compose([Normalize(p=1)], p=p)
train_loader = make_loader(train_file_names, shuffle=True, transform=train_transform(p=1),
problem_type=args.type, batch_size=args.batch_size)
valid_loader = make_loader(val_file_names, transform=val_transform(p=1),
problem_type=args.type, batch_size=len(device_ids))
root.joinpath('params.json').write_text(
json.dumps(vars(args), indent=True, sort_keys=True))
if args.type == 'binary':
valid = validation_binary
else:
valid = validation_multi
utils.train(
init_optimizer=lambda lr: Adam(model.parameters(), lr=lr),
args=args,
model=model,
criterion=loss,
train_loader=train_loader,
valid_loader=valid_loader,
validation=valid,
fold=args.fold,
num_classes=num_classes
)
if __name__ == '__main__':
main()- train.sh,shell 训练脚本:
#!/bin/bash for i in 0 1 2 3 do python train.py --device-ids 0,1,2,3 --batch-size 16 --fold $i --workers 12 --lr 0.0001 --n-epochs 10 --type binary --jaccard-weight 1 python train.py --device-ids 0,1,2,3 --batch-size 16 --fold $i --workers 12 --lr 0.00001 --n-epochs 20 --type binary --jaccard-weight 1 done
生成 Masks
- generate_masks.py,生成 masks.
python3 generate_masks.py --help 返回可设置输入参数.
如:
python3 generate_masks.py --output_path predictions/unet16/binary --model_type UNet16 --problem_type binary --model_path data/models/unet16_binary_20 --fold -1 --batch-size 4结果评估 Evaluation
- [1] - 二值语义分割,针对每张图像或每个 video,计算 Jaccard(Dice);然后平均化预测结果.
- [2] - 多类语义分割,先对每张图像独立计算每类的 Jaccard(Dice)再求平均化;然后针对每个 video 计算.
python3 evaluate.py --target_path predictions/unet16 --problem_type binary --train_path data/cropped_trainDemo 实例
import cv2
import numpy as np
import matplotlib.pyplot as plt
import torch
from utils import cuda
from dataset import load_image
from generate_masks import get_model
from albumentations import Compose, Normalize
from albumentations.torch.functional import img_to_tensor
def img_transform(p=1):
return Compose([Normalize(p=1)], p=p)
def mask_overlay(image, mask, color=(0, 255, 0)):
"""
Helper function to visualize mask on the top of the car
"""
mask = np.dstack((mask, mask, mask)) * np.array(color)
mask = mask.astype(np.uint8)
weighted_sum = cv2.addWeighted(mask, 0.5, image, 0.5, 0.)
img = image.copy()
ind = mask[:, :, 1]
img[ind] = weighted_sum[ind]
return img
model_path = 'models/unet11_binary_20/model_0.pt'
model = get_model(model_path, model_type='UNet11', problem_type='binary')
img_file_name = 'data/cropped_train/instrument_dataset_3/images/frame004.jpg'
gt_file_name = 'data/cropped_train/instrument_dataset_3/binary_masks/frame004.png'
image = load_image(img_file_name)
gt = cv2.imread(gt_file_name, 0)
plt.imshow(image)
with torch.no_grad():
input_image = torch.unsqueeze(img_to_tensor(img_transform(p=1)(image=image)['image']).cuda(), dim=0)
mask = model(input_image)
mask_array = mask.data[0].cpu().numpy()[0]
plt.imshow(mask_array)
plt.imshow(mask_overlay(image, (mask_array).astype(np.uint8)))
plt.show()
print('Done.')