LLM 部署框架综合对比图:
From: LLM Serving Frameworks
Ollama vs vLLM
From: ollama与vllm的深度比对 - 知乎
综合对比:
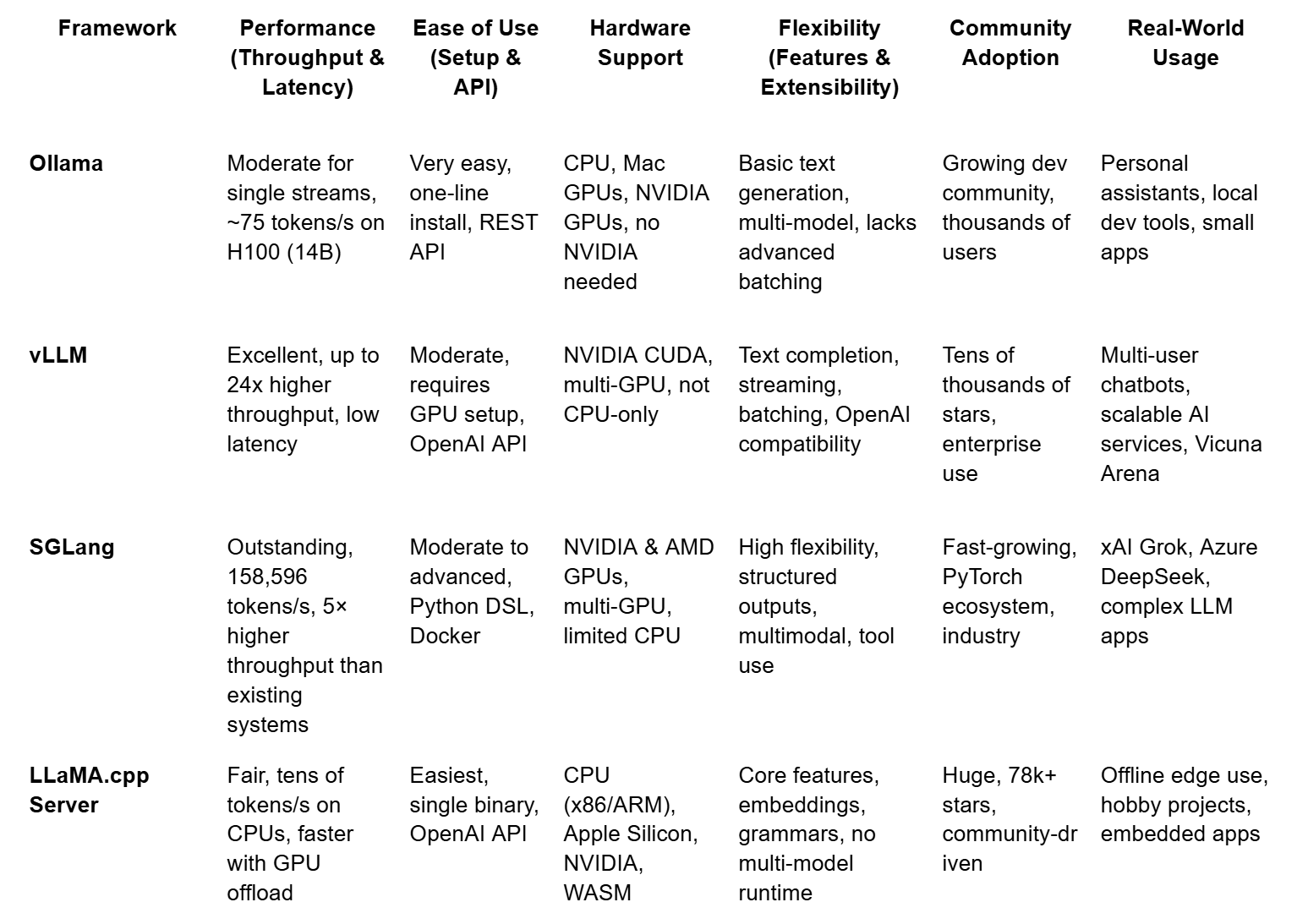
| 对比维度 | Ollama | vLLM |
|---|---|---|
| 核心定位 | 轻量级本地化工具,适合个人开发者和小规模实验 | 生产级推理框架,专注高并发、低延迟的企业级场景 |
| 硬件要求 | 支持 CPU 和 GPU,低显存占用(默认使用量化模型) | 必须依赖 NVIDIA GPU,显存占用高 |
| 模型支持 | 内置预训练模型库(支持1700+模型),自动下载量化版本(int4为主) | 需手动下载原始模型文件(如 HuggingFace 格式),支持更广泛模型 |
| 部署难度 | 一键安装,开箱即用,无需编程基础 | 需配置 Python 环境、CUDA 驱动,依赖技术经验 |
| 性能特性 | 单次推理速度快,但并发处理能力弱 | 高吞吐量,支持动态批处理和千级并发请求 |
| 资源管理 | 灵活调整资源占用,空闲时自动释放显存 | 显存占用固定,需预留资源应对峰值负载 |
Ollama 显存占用低的原因
- 模型量化技术
Ollama 默认下载的模型为 int4 量化版本(如Qwen2.5-14B 模型权重从 9GB 压缩至 4.7GB),显著减少显存需求。
而 vLLM 通常使用原始 FP16/BF16 模型,显存占用更高(例如 Qwen2.5-14B 在 vLLM 中需要 39GB 显存,而 Ollama 仅需 11GB)。 - 优化的显存管理
Ollama 基于 llama.cpp 的底层优化(如分块加载和混合精度计算),结合轻量级框架设计,进一步降低显存压力。
vLLM 则通过 PagedAttention 技术提升并发效率,但需固定分配显存块,导致资源占用较高。
性能与速度
- 推理速度
- 单次请求:Ollama 因量化模型和轻量级架构,单次推理速度更快(例如 Qwen2.5-7B 平均响应时间 3 秒左右,vLLM 约 3.5-4.3 秒)。
- 高并发场景:vLLM 凭借动态批处理和并行计算,吞吐量显著优于 Ollama(如 vLLM 的并发请求处理速度可达 Ollama 的 24 倍)。
- 模型质量损失
量化可能导致模型精度下降(如生成内容质量或指令遵循能力降低),部分用户实测发现 Ollama 的生成效果弱于 vLLM 的原始模型。 - 扩展性限制
Ollama 主要面向单机本地化场景,多 GPU 并行支持有限;vLLM 支持分布式部署和多卡扩展,适合大规模服务。
适用场景
选择 Ollama:
- 个人开发者快速验证模型效果、低配置硬件(如仅有 16GB 内存的笔记本电脑);
- 需要快速交互式对话或原型开发。
选择 vLLM:
- 企业级 API 服务、高并发批量推理(如智能客服、文档处理);
- 需要高精度模型输出或定制化参数调整。