https://twitter.com/akshay_pachaar/status/1748322389321265261
Retrieval Augmented Generation(RAGs) 是增强 LLMs(Large Language Models) 性能的强大工具,通过在生成过程中整合额外的知识.
如图:
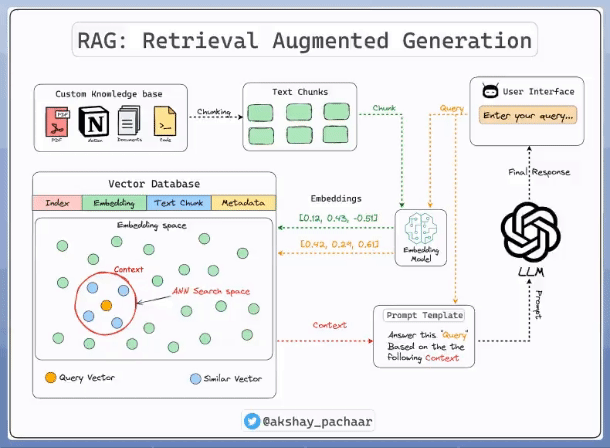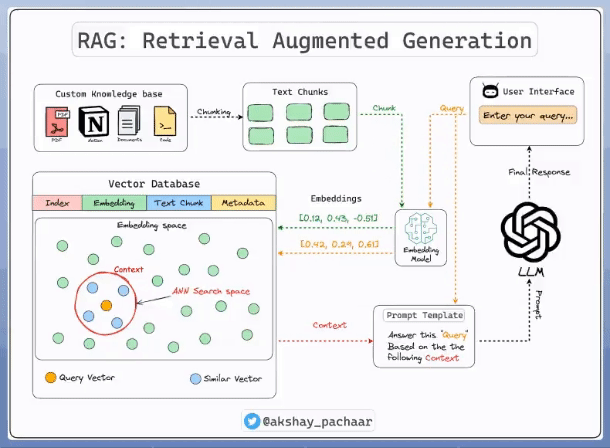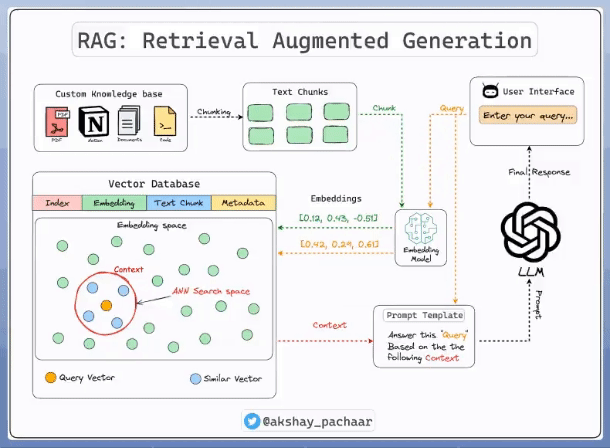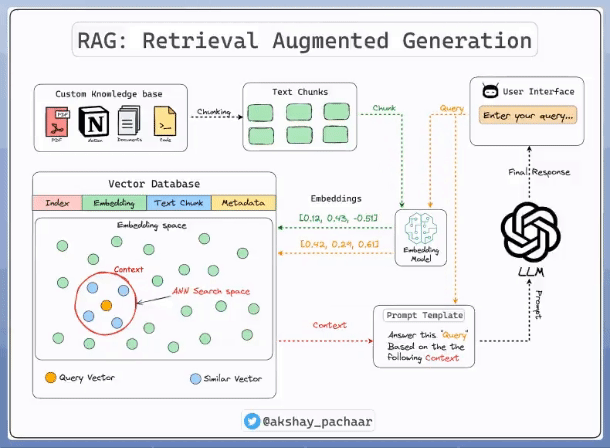
1. Custom Knowledge base
定制知识库:相关最新信息的集合,作为 RAG 的支撑. 其可以是 database、documents sets 等等.

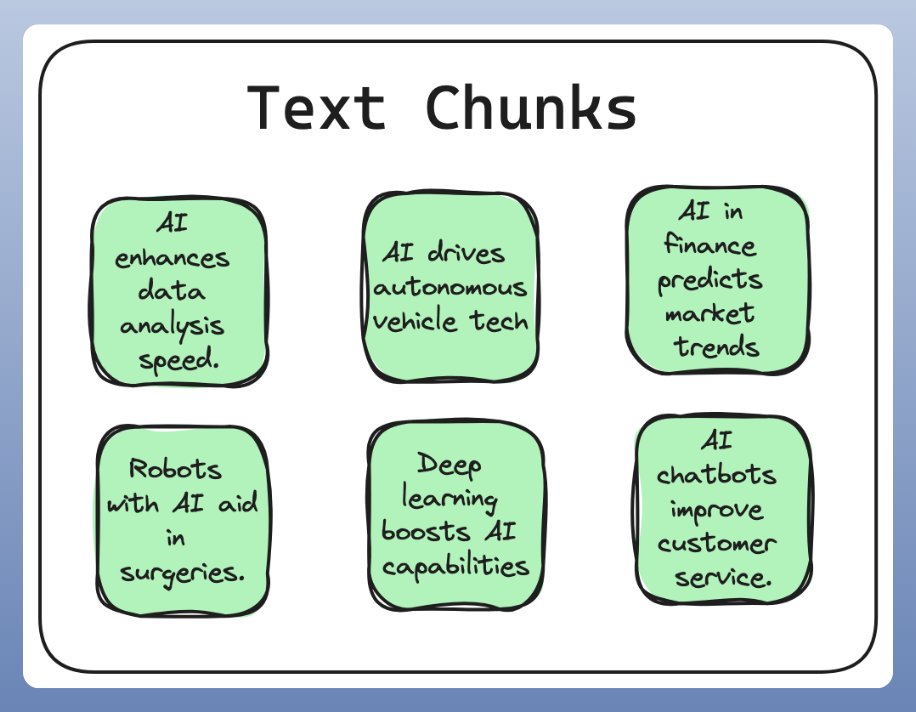
2. Chunking 分块
Chunking 是将大规模输入文本分解为小片的过程,以确保文本能够适应 embedding model 的输入尺寸,提升检索效率.
合适的分块策略能够大大增强 RAG 系统.
3. Embeddings & Embedding Model
Embedding 是一种用于将文本数据表示数值向量的技术,以作为机器学习的输入.
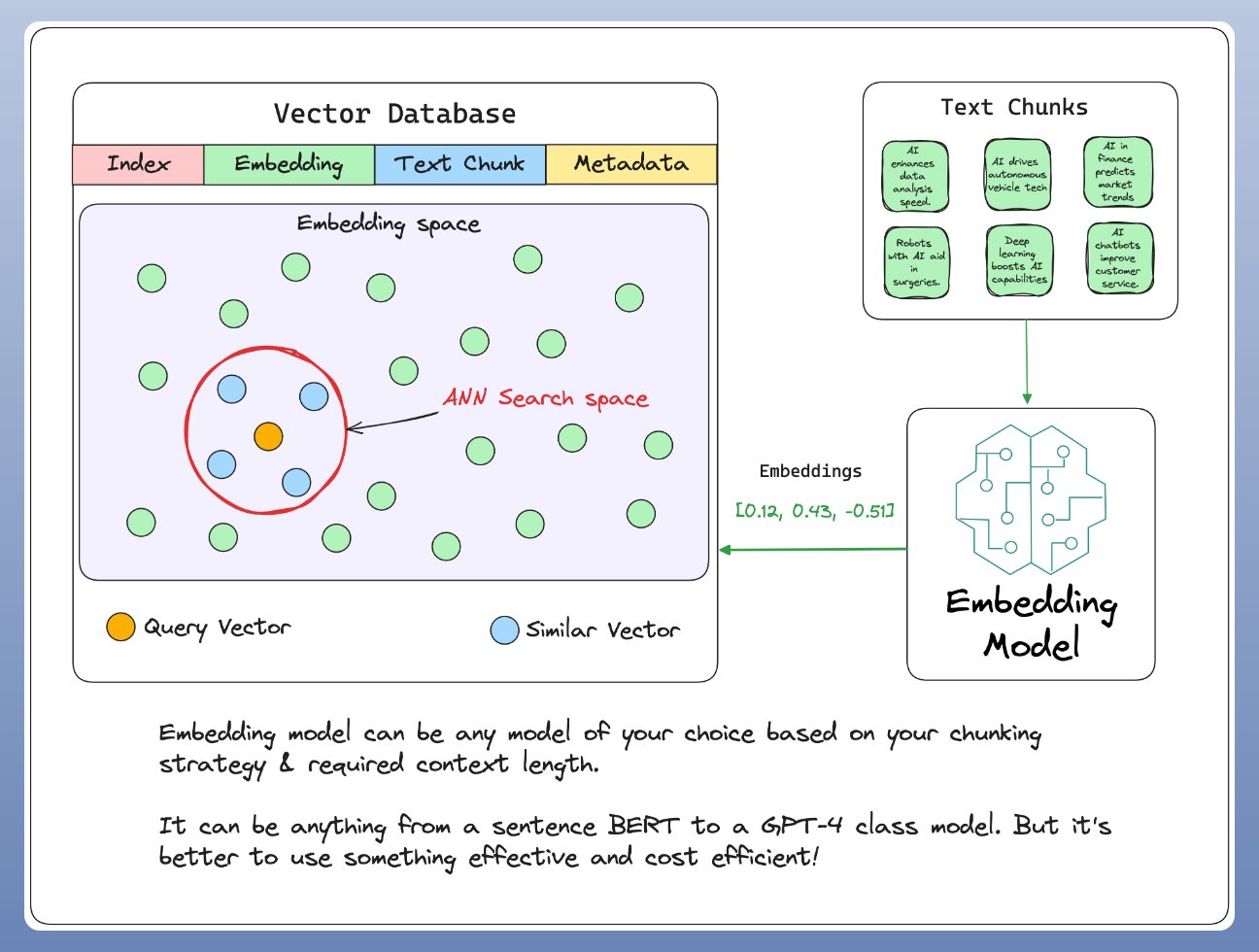
4. Vector Databases
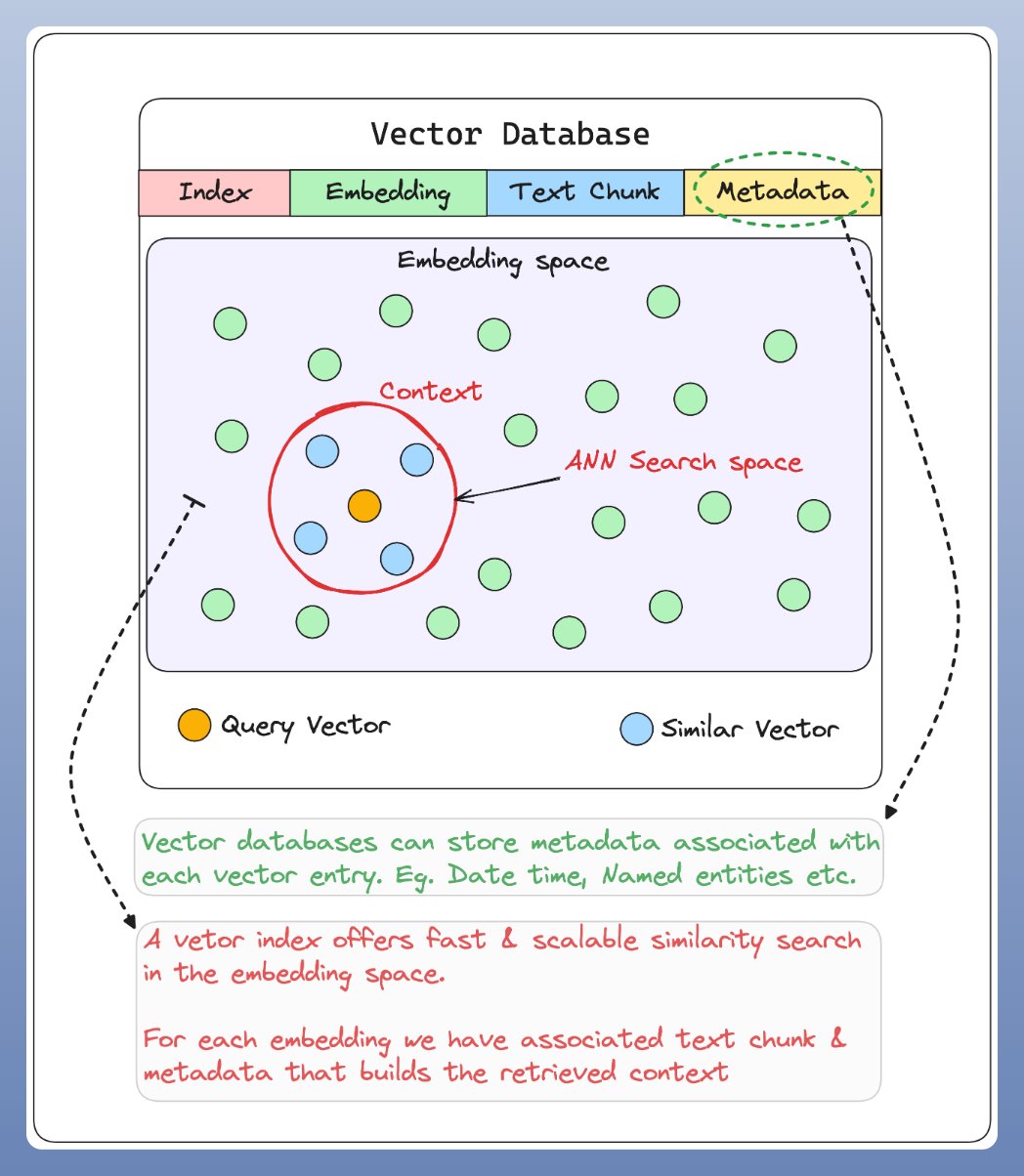
向量数据库,用于将预先计算的文本向量表示集合进行快速检索、相似度计算,其具有如 CRUD 操作、元数据过滤(metadata filtering)、横向扩展(horizontal scaling) 等功能.
5. User Chat Interface
用户聊天界面,用户友好的界面能够更好的实现与RAG系统的交互,提供输入查询、接受输出结果.
输入查询被转换为 embedding,以从向量数据库检索相关的内容.

6. Prompt Template
提示词模板是用于生成适合 RAG 系统 prompt 的过程,其可以是用户查询和定制数据库的结果. 其共同作为 LLM 的输入,以输出最终的响应结果.
