原文:PixelAI : 手淘客户端上的实时视觉算法应用 - 2019.07.25
出处:LiveVideoStack_ - CSDN
基于PixelAI上层视频业务可以快速搭建符合自身业务特色的实时交互视觉特效。在LiveVideoStackCon2019上海大会中,淘宝高级算法专家李晓波(篱悠)详细介绍了手淘在实现客户端上基于深度学习的视觉算法应用时如何在资源受限的情况下达到性能与效果之间的平衡。
本次分享将从设计原则与整体架构、基础算法和上层应用三个部分来介绍手淘视频业务在客户端上实时视觉算法领域的探索。
1. 设计原则与整体架构
1.1. 手淘多媒体算法整体链路
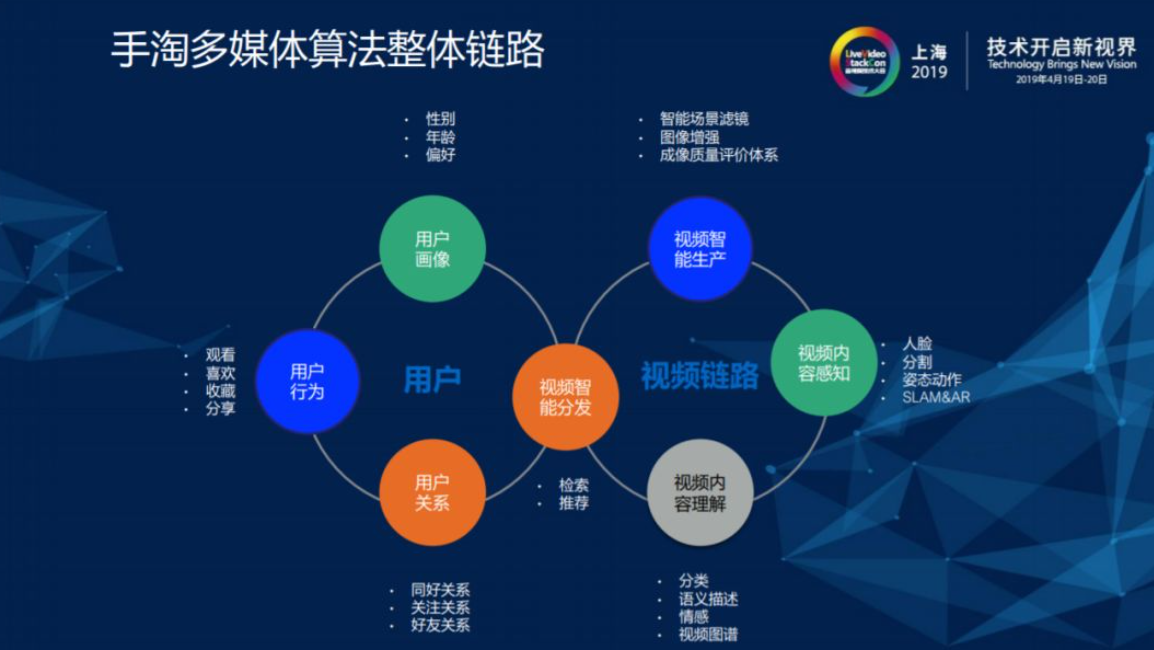
手淘多媒体算法分为视频生产和用户消费两部分,上图左半部环更多是由广告和搜索团队进行收集,算法团队主要负责右半部环中视频智能生产、内容感知及内容理解部分,当算法能够解决高级语义理解和结构化信息时,就可以结合左半部环内容结合起来做视频的个性化分发。
1.2. 手淘多媒体算法面临的挑战
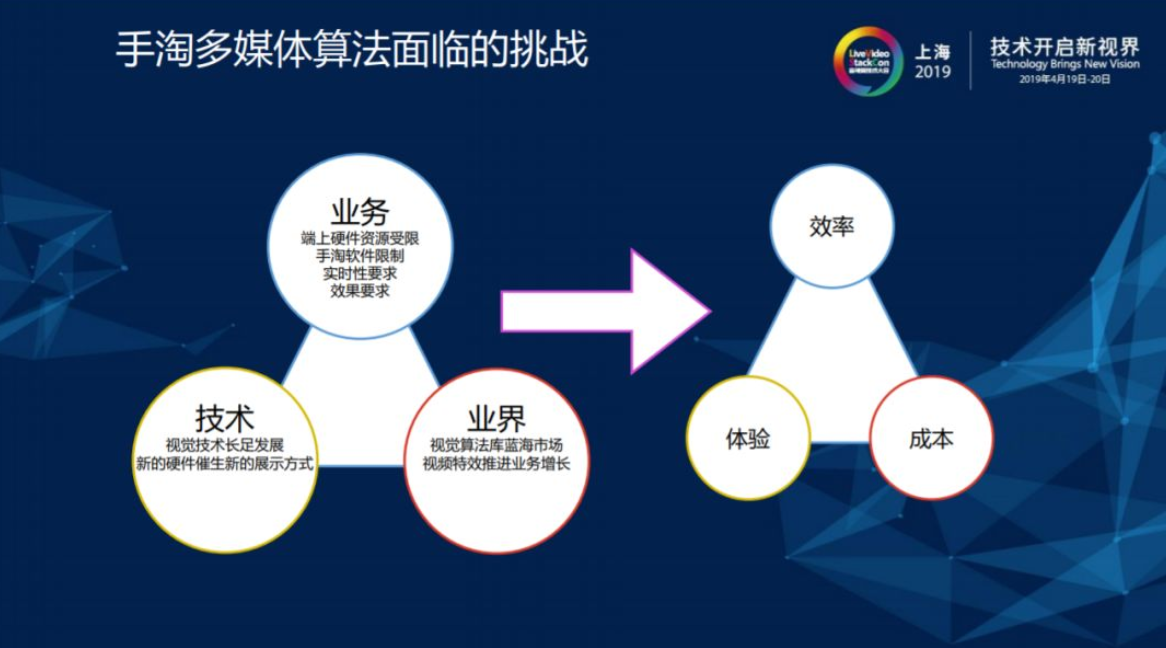
手淘多媒体算法目前面临业务、技术和业界进展变化(环境)三方面的挑战,应对这些挑战手淘分别在效率、体验和成本三个方面做出控制和改变。
1.3. 手淘客户端上实时视觉算法库
1.3.1. 模型设计与压缩
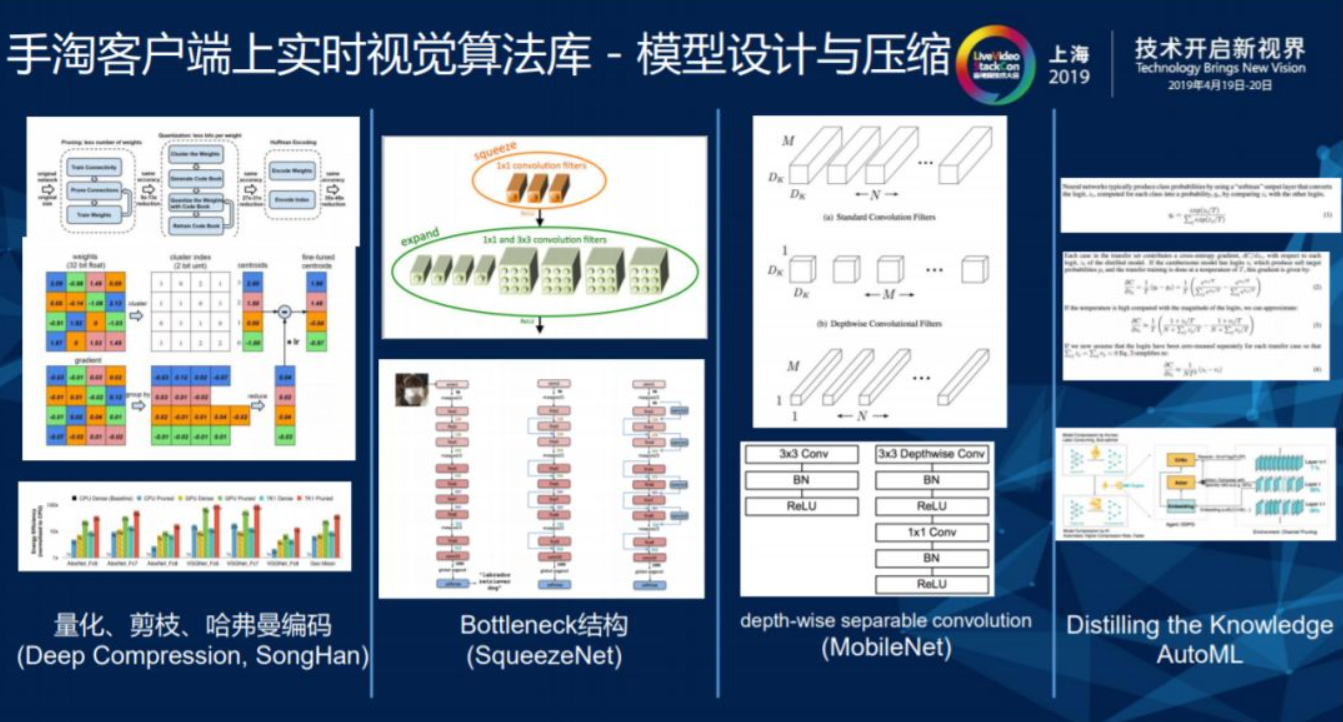
在端上做算法面临计算资源和内存受限的问题,移动端上存在很多实时交互的操作,例如视频的帧率一般都是 25FPS,如果算法对视频处理的速度很慢,那么用户实时交互的体验就无法得到保障。近几年深度学习在服务器上取得了很大的进展,但是由于计算资源和内存受限导致性能上存在差距,无法照搬深度学习的模型来解决移动端遇到的问题。
关于手淘客户端上的实时视觉算法库有几个大的设计原则,第一个原则是模型的设计和压缩,模型本身存在部分冗余信息,对冗余信息进行删减只是减少了存储和传输过程的成本,并没有改变计算成本。在对模型进行量化、剪枝和哈弗曼编码之后,压缩率在10-20倍之间,但想要使得计算量减少,还需要采取一些特殊结构。比如最早的矩阵在分解时可以把二维矩阵拆成两个一维矩阵进行分解,在深度学习里存在一些3×3或5×5的滤波器深度可分离卷积,结合这部分技术加以运用。另外一部分,在设计整个客户端的过程中不可避免要对stage进行减少,在层次更深的同时缩减宽度,使得非线性连接增多,这其中需要AutoML来替代人工手动实现高效的模型构建和超参数调整。
1.3.2. 多任务学习

整个视频处理过程中如果遇到多任务情况,算法模型均采用端到端来进行,计算资源会产生冗余。比如在人脸识别计算中,关键点和表情计算时都会传入人脸图片,这时就会产生资源浪费的现象。视频处理多任务情况时一定会有多任务学习框架,基于多任务降低冗余计算量。
1.3.3. 小样本学习
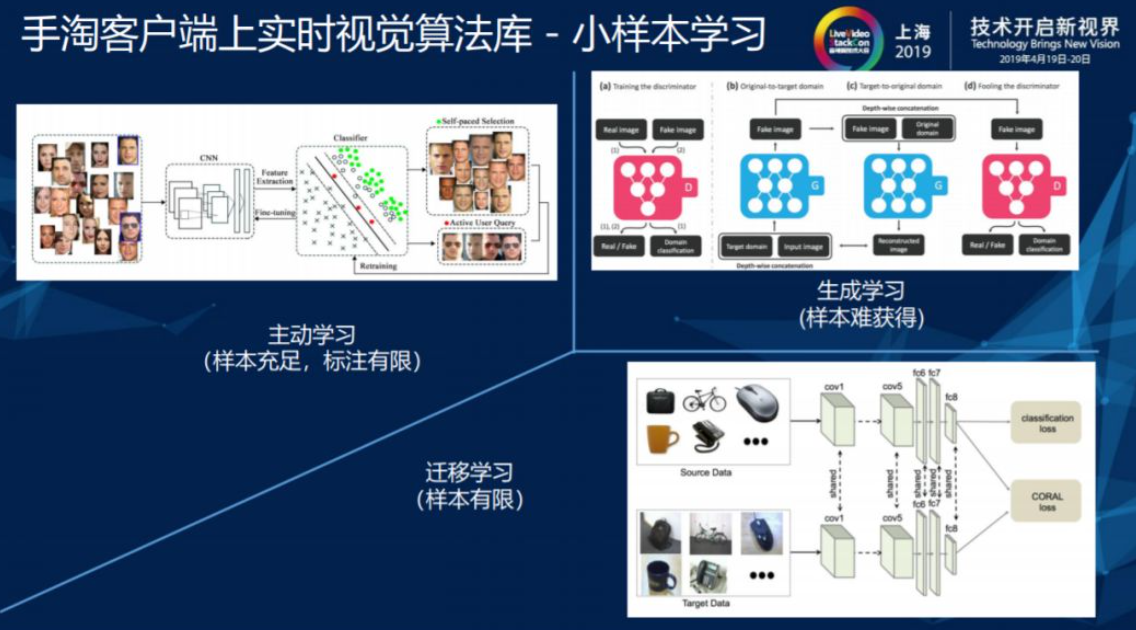
样本对于深度学习和视频处理过程是非常重要的,不论公司规模大小,在对标注样本方面的经费都是有限的,或是受到成本约束和样本获取难度的影响,无法满足充足的样本条件。如果在样本充足、标注预算有限的情况下,可以采用主动学习的方式对获取难度较高的样本进行标注,以此达到降低成本的目的。在样本获取难度较大的情况下,可以采用类似任务模型和小量任务相关样本做进一步的关联,像OCR或其他的字符识别软件在对字体进行识别时,不可能对所有字体进行采集,通常采用GAN网络或者其他技术去生成样本,这些模型会在提升识别精度和准确度的同时降低计算成本。
1.4. PixelAI的整体架构

PixelAI与手淘业务域直接相关,架构由业务中抽象而成,所有在端上实时运行的算法一定要有一个实时运行的深度学习可推理框架,在阿里内部叫AliNN,腾讯也有类似的开源框架叫做NCN。在3D渲染方面阿里内部在使用T3D引擎,Unity 3D也是同样的效果,同时阿里对于OPENCV的依赖性也比较大。
1.4.1. PixelAI内涵与外延

基础算法包括人脸检测、人形分割、手势识别、姿态识别、视觉跟踪、场景分类(分类、定位网络)和图像处理(锐化、美颜)模块,基于底层算法可以泛化出上层的内容。比如人脸检测拿到的106/240个点,这些点的数据需要进一步抽象成面部表情和动作再输出给上层做出反应。
1.4.1. PixelAI的数据体系
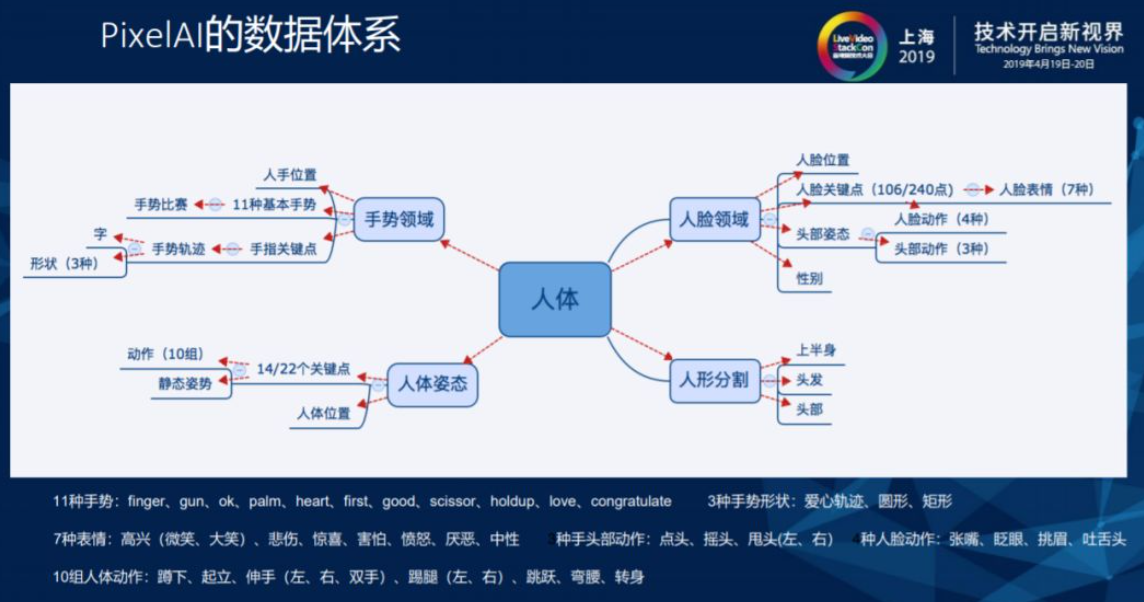
由于手淘的业务域是以直播和短视频为主,手淘基于业务域构建了以人体为中心,手势领域、人脸领域、人体姿态和人形分割四个分类的数据体系。
2. 基础算法
2.1. AliH265
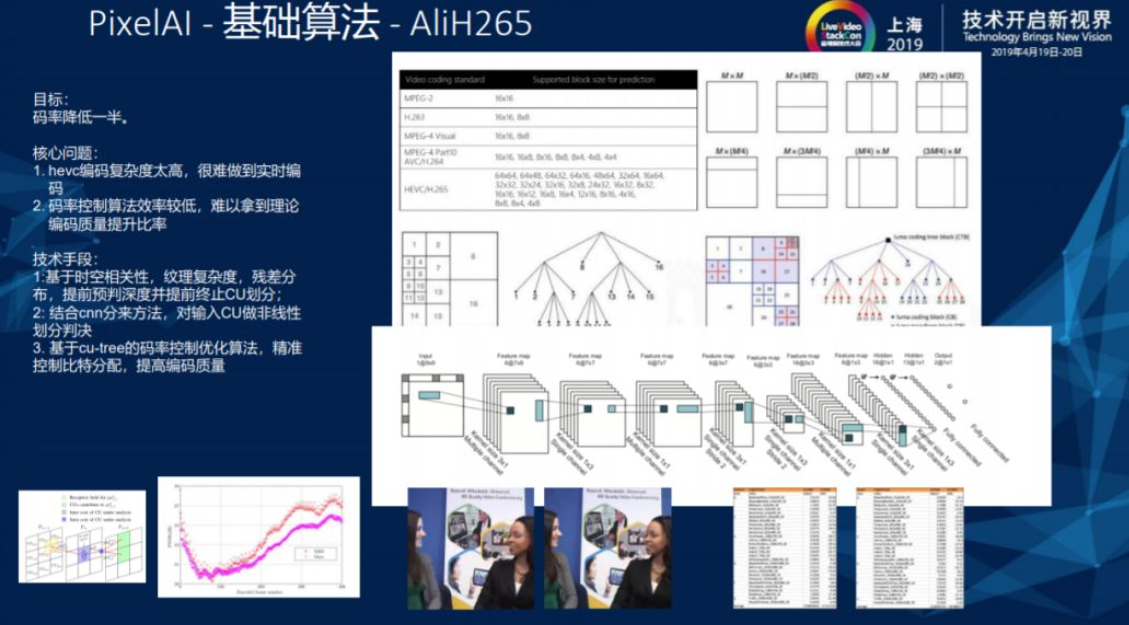
基础算法的第一部分,阿里做了一个在端上可以实时对720视频进行处理的AliH65算法,应用深度学习来解决H.265中对于CPU的划分问题,提升H.265的编码效率。
2.2. 画质增强

用户拍摄过程中出现模糊、光照条件不好、抖动情况都需要做实时的分层算法来实现画质增强的效果。
2.3. 人形分割
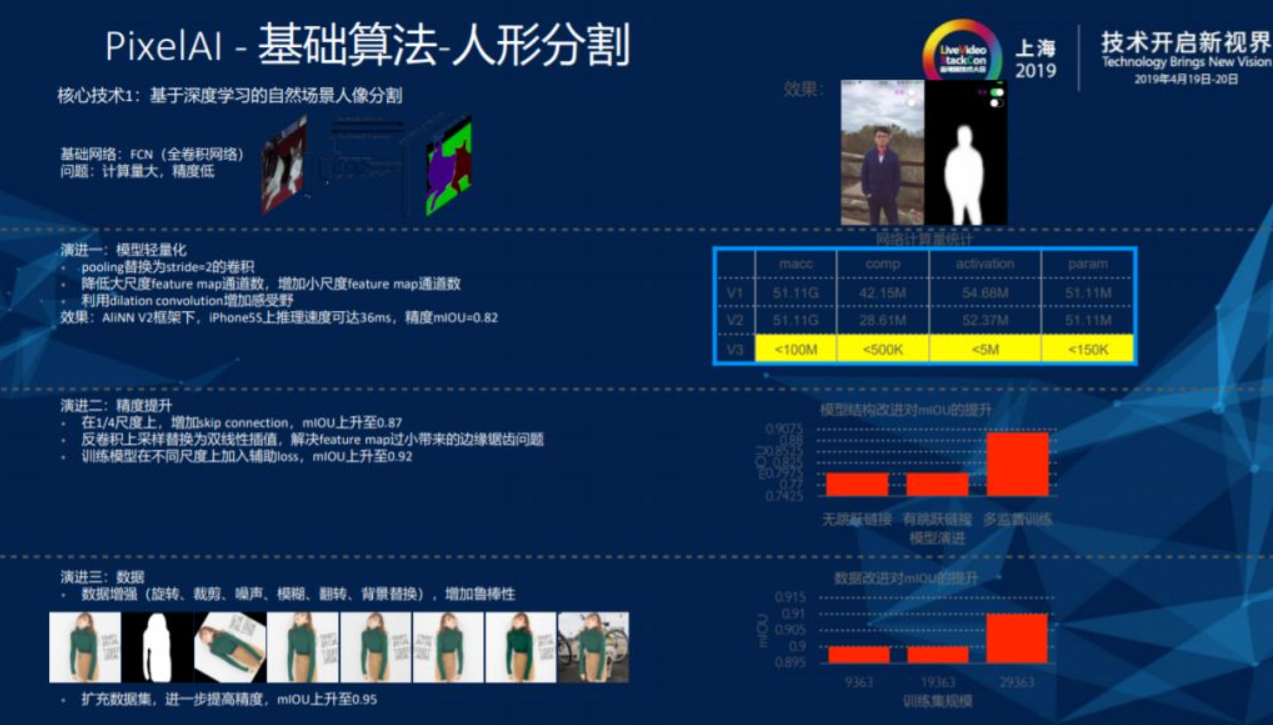
人形分割基本分为两步,第一步是通过深度学习找到人形的边界,基础网络FCN主要针对云上大模型,通过量化裁剪、深度卷积可分类、AutoML 搜索超参设计出可以在端上实时运行的小模型。
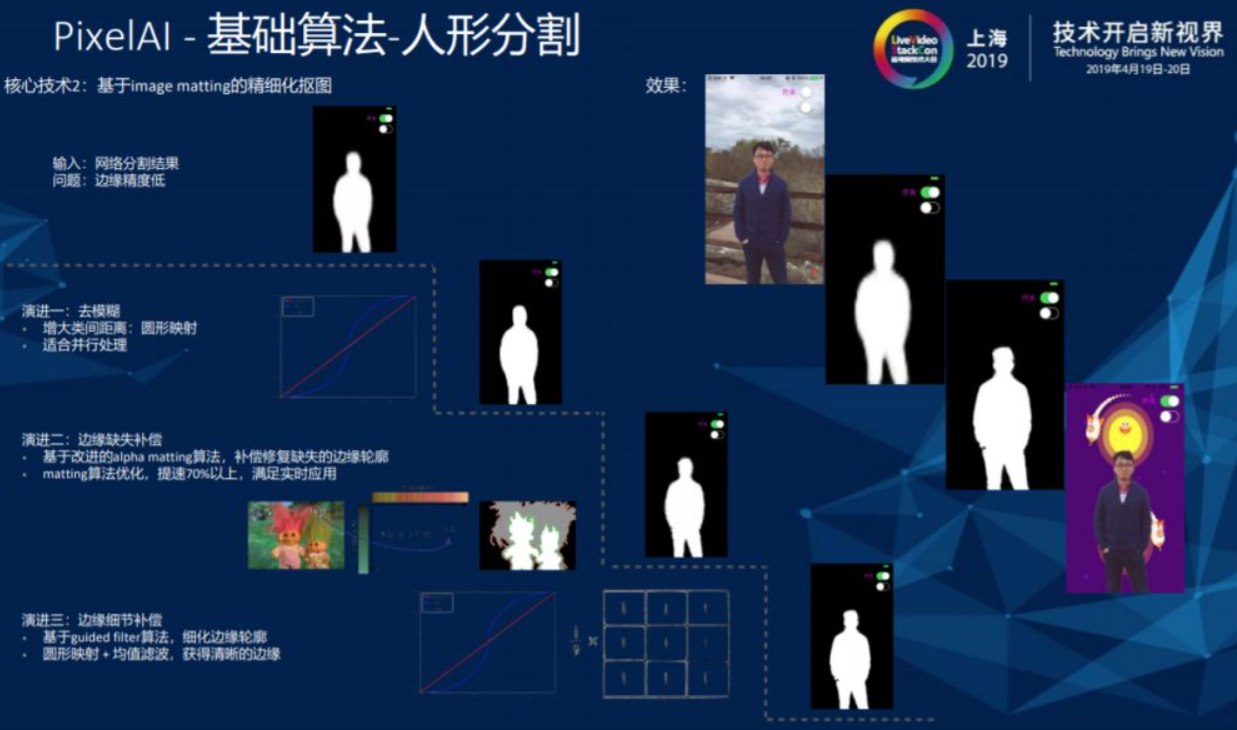
在得到初步轮廓之后,就可以进行第二步对人形基于image matting的精细化抠图。

在实现人形分割后对于业务层面能够实现人像分割、头发分割及染发应用、弹幕穿人和人脸分割等功能。
2.4. 人体姿态估计
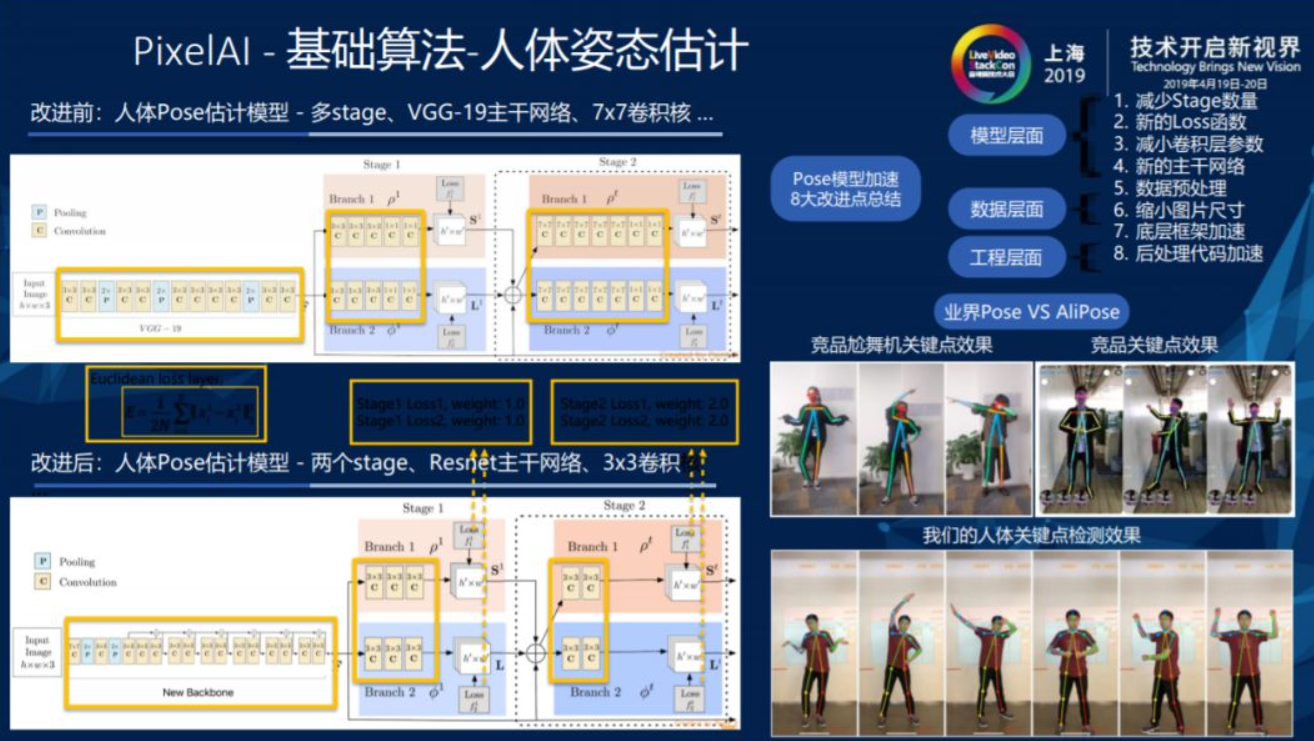
人体Pose模型加速有8个改进点,模型层面能够减少Stage数量和卷积层参数,提供新的Loss函数和新的主干网络。数据层面能够对数据进行预处理、缩小图片尺寸。工程层面能够实现底层框架加速和后台处理代码加速。
2.5. 成像质量
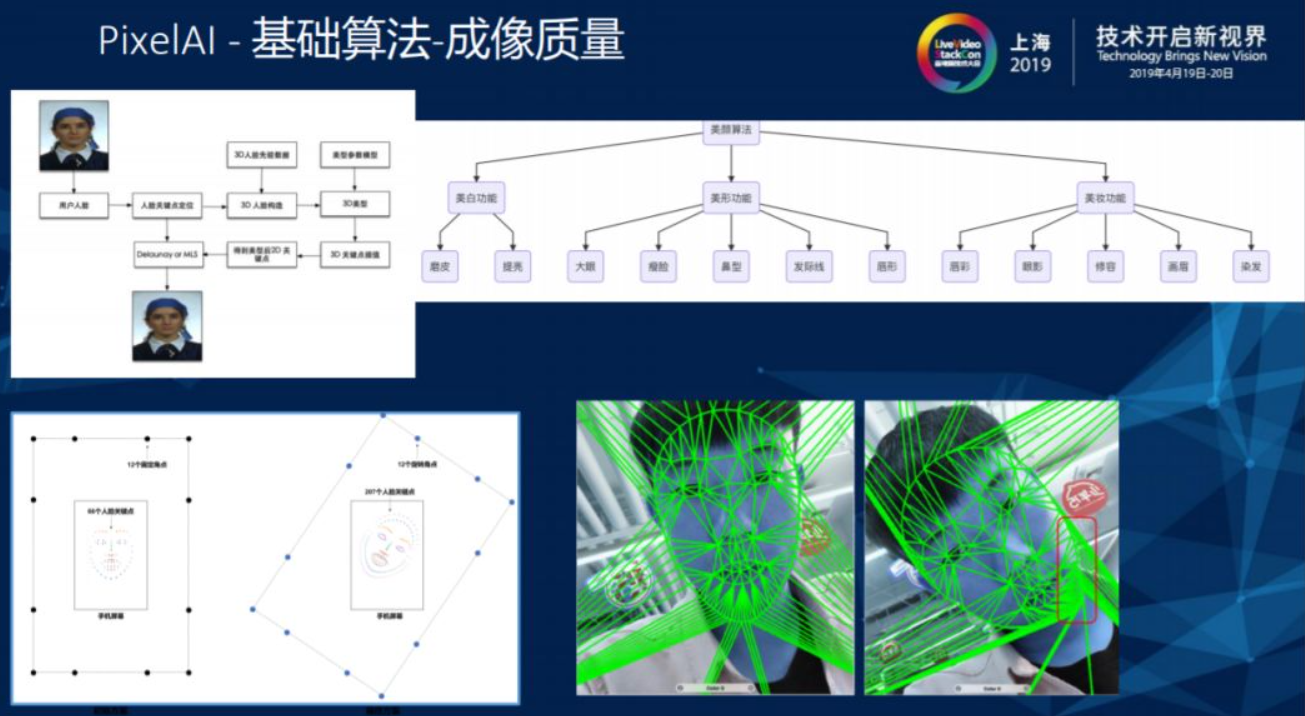
美颜是成像质量中比较重要的功能,在拿到用户输入的2D视频后首先进行人脸检测和关键性检测,人脸检测和关键性检测的数据会将用户2D的数据重新映射成3D模型,在3D模型上进行人脸调整后再重新映射回2D关键点,新生成的关键点与初始关键点进行三角抛分,最后通过映射得到最终的美颜效果。
2.6. 人脸检测
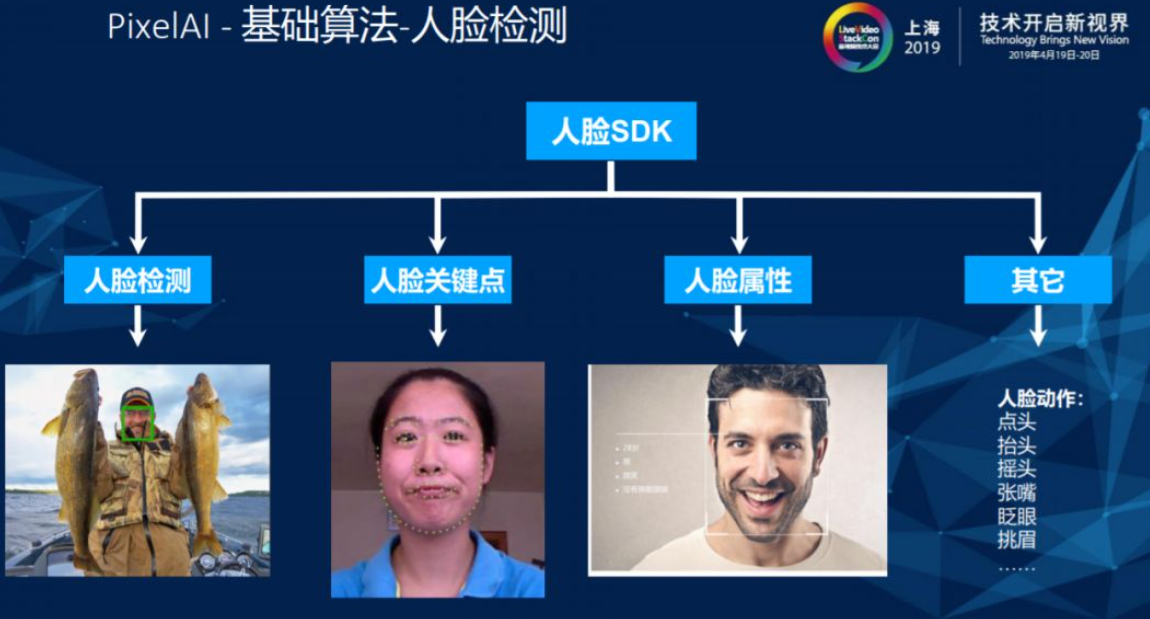
人脸SDK可细分为人脸检测、人脸关键点、人脸属性和人脸动作四大类。
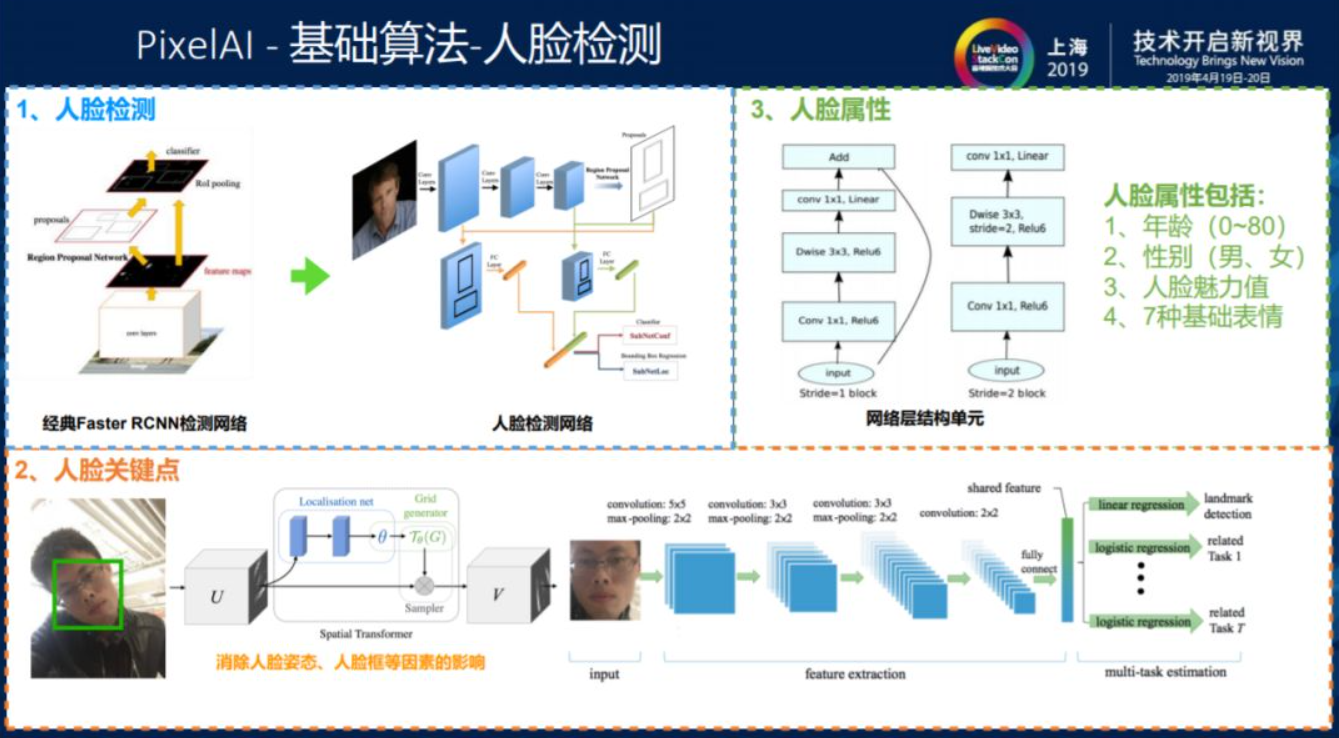
上图主要展示人脸检测功能中所用到的技术。
检测类的网络模型并不多,人脸检测是由经典Faster RCNN检测网络中根据之前提到的原则设计方案泛化到端上的小模型。人脸关键点最早是像SDM一类的技术,但在深度学习领域都是端到端的,先根据关键点检测框的位置,在框中用小网络去回归关键点。做人脸检测需要全图像搜索,关键点回归只是在小的图像上进行回归,所以检测和关键点回归在执行速度上是完全不同的。为了控制人脸检测的耗时问题,阿里在首帧检测中使用全图像搜索,之后十帧通过跟踪网络进行关键点回归,图像在短时间内出现较大幅度变化时再使用全图像搜索,如此循环执行使检索时间缩短到15ms以内。在跟踪过程中涉及到单目标跟踪和多目标跟踪的问题,单目标跟踪会有一些基于相关滤波的算法,比如KCF等高效实现,多目标跟踪时会有一些基于深度学习的网络模型对人像做出各种各样的预测,根据不同场景来对模型进行不同的设计。
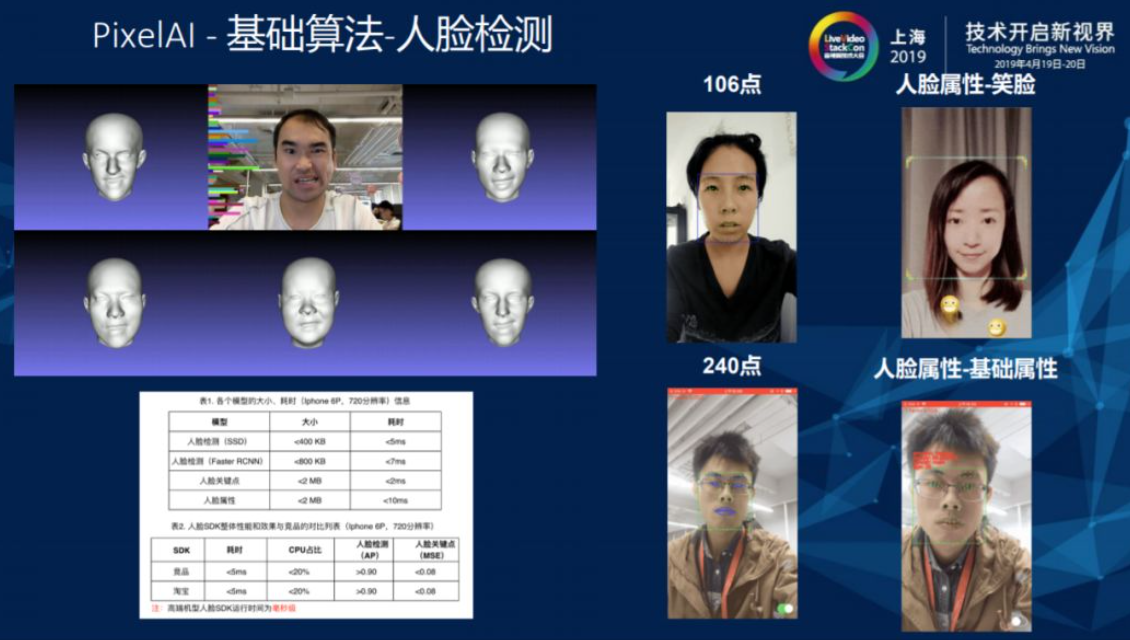
当人脸属性、关键点、表情动作和姿态都能够识别出来时,就可以对表情进行上层的3D拟合。
3. 上层应用
3.1. PixelAI应用
3.1.1. 码率优化
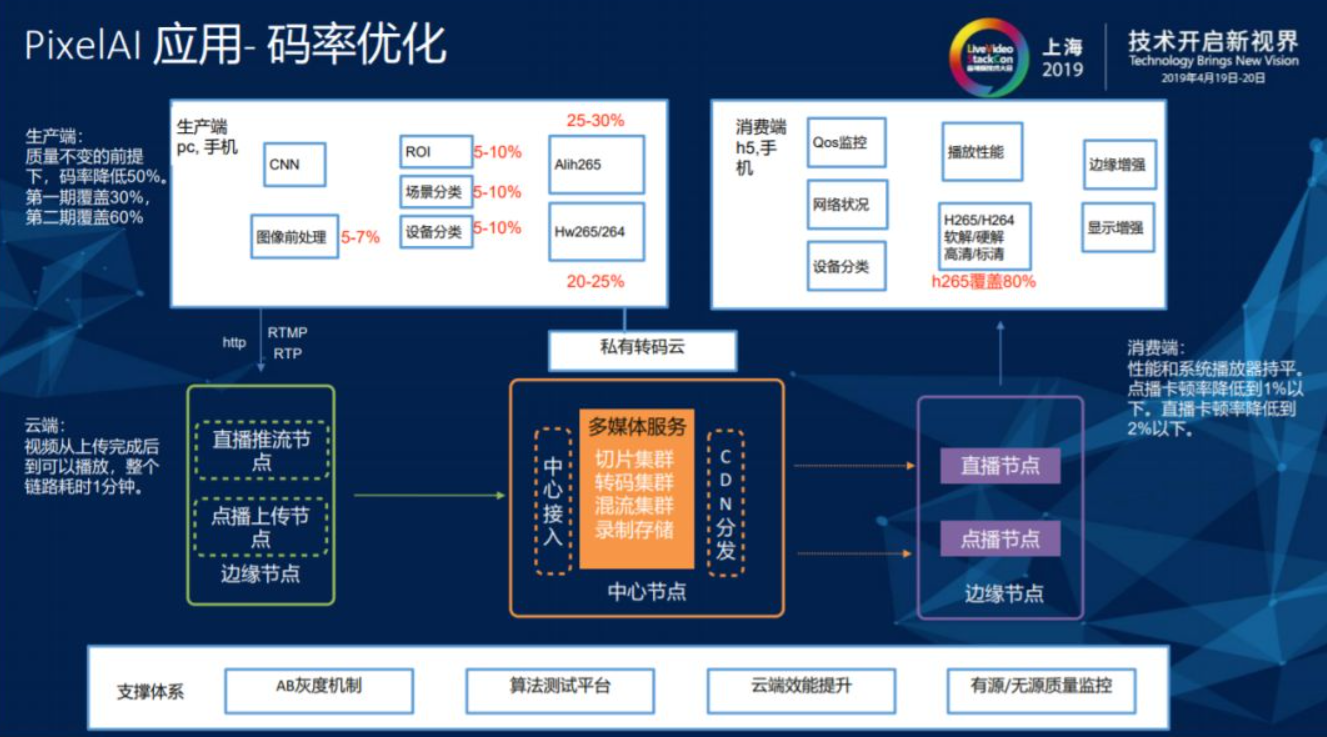
码率优化是在画质固定的情况下通过AI和视频编解码结合来降低码流。要保证画质不变就一定要做无源参考体系的评价系统,因为视频生产和编码过程中可以保证视频质量不变,但无法预测用户上传到服务器侧的视频质量。编码过程中无法计算视频的PSR码,小数据集上的证明无法保证在泛化的大数据上有效,所以质量分布不变指的是全网视频生产的无源视频平均分布不变。
3.1.2. 双十一笑脸大作战

在阿里第一次做人脸识别模块时,从开源大模型到满足设计需求的小模型,开发周期是六个月左右,但在之后开发相同模型支持上层业务时,用时便大大缩短。在笑脸大作战的功能开发过程中,网络模型使用人脸检测模型,唯一的改变是对识别笑脸通过 L-Softmax Loss进行分类,L-Softmax Loss的主要功能是拉大类间距离和缩小类内距离,由此提高分类正确率,减少误判。
3.1.3. 3D照片探索项目
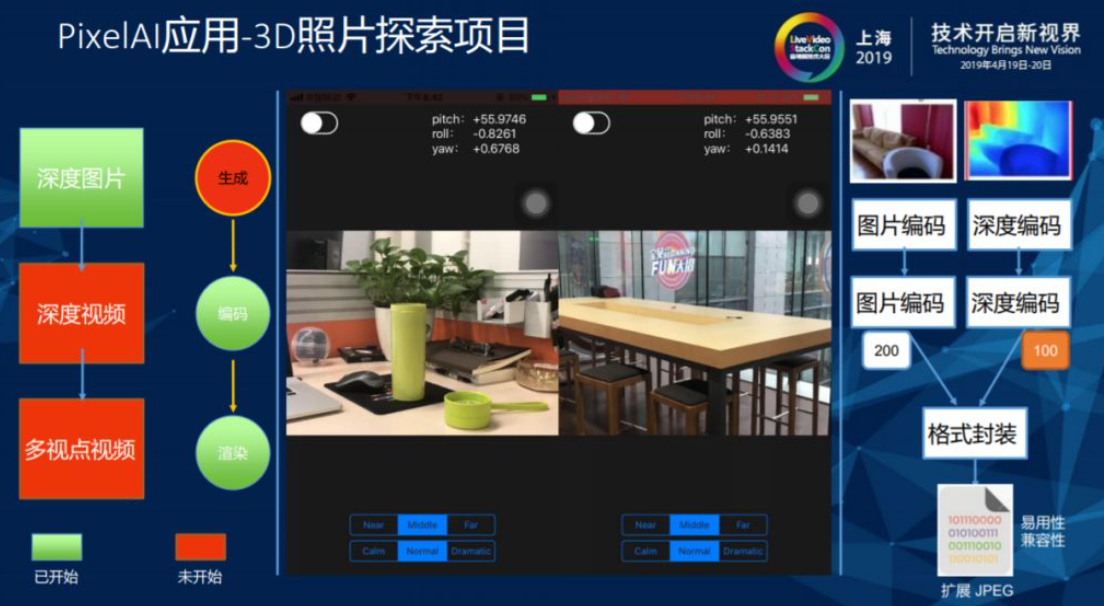
PixelAI在之前获取的内容全部是2D的RGB信息,随着双摄以及多摄像头技术在移动端上的普及,赋予图像在深度方面越来越多的信息,深度信息的获得、传输和渲染都是团队目前需要解决的问题。所有的数据分为存量数据和增量数据,增量数据可以通过移动端或者其它设备获取深度图。目前淘宝上有几百亿的存量数据,其中大部分商品信息都是由单目设备拍摄,如何恢复图像的深度信息也是手淘团队一直在关注的方向。
上图中标红的问题还未进入开发阶段,由于相机参数、角度、光照等因素不同,在内参外参都不得知的情况下想要对深度信息进行恢复,这其中充满了难点和挑战。手淘团队目前的解决方案是从增量信息开始对深度图片和RGB图片进行有机的压缩,这样做面临着两个问题,第一,从H.264就开始出现一些对深度的压缩标准,RGB的压缩有另一套标准,两种标准在同一文件中如何进行更高效的有机压缩。第二,获得深度信息之后,在应用如何对深度信息进行渲染。在VR、AR技术受到很高关注度期间,采取多视频建模之后通过点云恢复的方法完成3D建模,但空洞无法避免的问题使得这个方法没办法达到规模化生产,形成规模化的前提是要有一套没有人工介入的完全自动化的解决方案。在借鉴Facebook关于2.5D图片(有限视角下对3D模型的构建)的概念之后,手淘团队也通过将具有简单视角的深度图和RGB图结合的方式,构建出单视角下的3D模型,最后将模型与用户相机姿态结合起来,做出在定点视角下移动的效果。