原文:并发和并行 | Python中实现多线程 threading 和多进程 multiprocessing-2021.06.22
简单来说,用多线程对应并发,多进程对应并行。
多线程并发更强调充分利用性能;多进程并行更强调提升性能上限。
并行计算,如图(多线性并行),开始并行后,程序从主线程分出许多小的线程并同步执行,此时每个线程在各个独立的CPU进行运行,在所有线程都运行完成之后,它们会重新合并为主线程,而运行结果也会进行合并,并交给主线程继续处理。
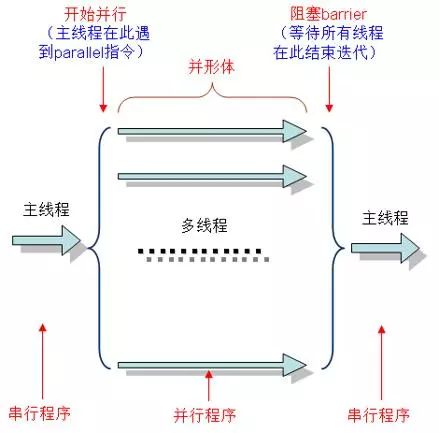
图:多线程并行
多线程并发,如图,是一个多线程的任务(沿线为线程时间),但它不是并行任务。这是因为task1与task2总是不在同一时刻执行,这个情况下单核CPU完全可以同时执行task1与task2。方法是在task1不执行的时候立即将CPU资源给task2用,task2空闲的时候CPU给task1用,这样通过时间窗调整任务,即可实现多线程程序,但task1与task2并没有同时执行过,所以不能称为并行。可以称它为并发(concurrency)程序,这个程序一定意义上提升了单个CPU的使用率,所以效率也相对较高。
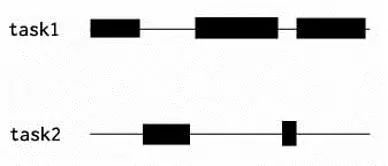
图:多线程并发
1. 多进程与多线程
1.1. 多进程
多个 CPU ( CPU 的多核)相当于多个学生。
一个任务可以拆成几个任务相互协作、同时进行,则是多进程。
比如研究生课程,写一片论文作业:
那就多线程并行搞呗。确定了大概思路,剩下的一股脑写就行。假设一共甲乙丙丁四名同学,那就:
- 甲同学负责 Introduction
- 乙同学负责 Background
- 丙同学负责 Related Works
- 丁同学负责 Methodology
可以预知,上述四部分同时进行,怎么也比一个人写四块要快。
所以说 多进程并行提升性能上限 。
在实际情况中,多进程更多地与高性能计算、分布式计算联系在一起。
1.2. 多线程
一个 CPU 相当于一个学生。
一个学生一周开一次组会,换句话说一周给老师汇报一次工作。
老师一般会给学生同时布置几个任务,比如做比赛、做项目、读论文,学生可能周一做做比赛、周二读读论文、周三做做项目… 到了组会,他就把三件事都拿出来汇报,老师很欣慰,因为在老师的视角里:学生这三件事是同时在做的。
多线程也是同一个道理,假设你的手机只有一块单核 CPU 。你的 CPU 这 0.01 秒用来播放音乐,下 0.01 秒用来解析网页… 在你的视角里:播放音乐和解析网页是同时进行的。你大可以畅快地边听音乐边网上冲浪
何谓充分利用性能? 如果这学生只有一项工作,那他这一周可能只需要花费两天来做任务,剩下时间摸鱼。因此,我们用多线程来让学生实现并发,充分利用学生能力。
在实际情况中,多线程、高并发这些词语更多地出现在服务端程序里。比如一个网络连接由一个线程负责,一块 CPU 可以负责处理多个异步的请求,大大提升了 CPU 利用率。
2. Python 实现
假设任务为:
def euler_func(n: int) -> int:
res = n
i = 2
while i <= n // i:
if n % i == 0:
res = res // i * (i - 1)
while (n % i == 0): n = n // i
i += 1
if n > 1:
res = res // n * (n - 1)
return res求一个数的欧拉函数值可能很快,但是一堆数呢?
所以期望用并行完成这个任务。
把任务分成三份。
task1 = list(range(2, 50000, 3)) # 2, 5, ...
task2 = list(range(3, 50000, 3)) # 3, 6, ...
task3 = list(range(4, 50000, 3)) # 4, 7, ...
def job(task: List):
for t in task:
euler_func(t)[1] - 正常的串行运行:
@timer
def normal():
job(task1)
job(task2)
job(task3)完成了 task1 再完成 task2 …
[2] - 多线程运行:
#import threading
#print(threading.active_count()) # 查看当前线程数量
#print(threading.enumerate()) # 枚举当前线程
#print(threading.current_thread()) # 当前线程
import threading as th
@timer
def mutlthread():
th1 = th.Thread(target=job, args=(task1, ))
th2 = th.Thread(target=job, args=(task2, ))
th3 = th.Thread(target=job, args=(task3, ))
th1.start()
th2.start()
th3.start()
th1.join()
th2.join()
th3.join()[3] - 多进程运行:
import multiprocessing as mp
@timer
def multcore():
p1 = mp.Process(target=job, args=(task1, ))
p2 = mp.Process(target=job, args=(task2, ))
p3 = mp.Process(target=job, args=(task3, ))
p1.start()
p2.start()
p3.start()
p1.join()
p2.join()
p3.join()上述代码的逻辑是这样的:
[1] - 创建线程/进程,其目的就是完成任务job(task1)、job(task2)或job(task3),注意这里函数名和参数被分开了target=job, args=(task1, )
[2] - 然后 start() ,告诉线程/进程:可以开始干活了
[3] - 他们自己干自己的,程序主逻辑还得继续往下运行
[4] - 到 join() 这里,是指让线程/进程阻塞住主逻辑,比如p1.join()是指:p1不干完活,主逻辑不往下进行(属于是阻塞)
[5] - 这样,函数multcore结束后,一定其中的线程/进程任务都完成了
查看运行结果:
if __name__ == '__main__':
print("同步串行:")
normal()
print("多线程并发:")
mutlthread()
print("多进程并行:")
multcore()
#输出如
'''
同步串行:
timer: using 0.24116 s
多线程并发:
timer: using 0.24688 s
多进程并行:
timer: using 0.13791 s
'''结果不太对,按理说,多进程并行的耗时应该是同步串行的三分之一,毕竟三个同等体量的任务在同时进行。
多线程并发比同步串行慢是应该的,因为多线程并发和同步串行的算力是一样的,但是多线程并发得在各个任务间来回切换,导致更慢。
由于全局解释锁存在,多线程的任务可能并没有正常程序快. 所以多线程适用于多IO的程序,不合适用于多计算程序
注: @timer 是修饰器,如下。
def timer(func):
@wraps(func)
def inner_func():
t = time.time()
rts = func()
print(f"timer: using {time.time() - t :.5f} s")
return rts
return inner_func