题目: Human Attribute Recognition by Deep Hierarchical Contexts - ECCV2016
作者: Yining Li, Chen Huang, Chen Change Loy, and Xiaoou Tang
团队: CUHK
基于深度层次内容信息的人体属性识别
1. 摘要
训练CNN网络,以从所有检测部位中选取最具描述属性的人体部分;并结合整体人体作为归一化的姿态深度表示.
采用从以人为中心层次到场景层次的深度层次内容信息,进一步提升识别结果.
以人为中心的内容信息捕捉了人体间的关系,在CNN特征图的金字塔上计算最邻近的其它人体的部位,匹配的部分再进行平均池化(average pooled),以此作为相似性正则项.
场景内容信息,采用CNN中联合学习的全局场景分类分数来重新对以人为中心的预测结果进行重新打分,以得到最终的场景相关预测.
人体属性,比如性别、衣服风格等,有益于如视频中人体识别等许多应用.
遇到的挑战有,图片中人体视角变化、姿态、光照及缺失等很多因素. 如,

Figure1 中,由于缺失问题和图像质量低问题,只根据目标人物来对“西装”、“太阳镜”进行推断是困难的. 但是可以利用目标人物所在的图片全局信息,找到相似邻近人物的相关部分,得到分层的内容信息.
2. 网络结构
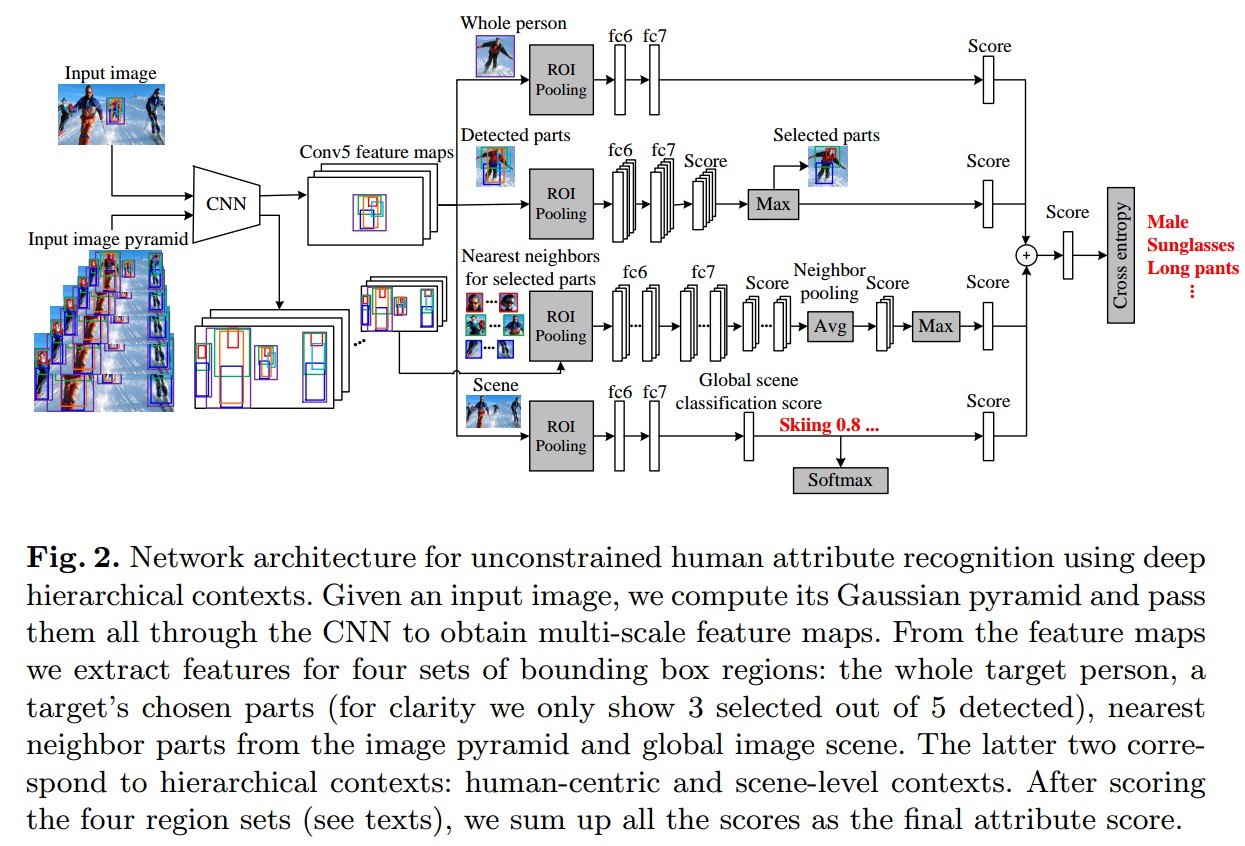
Figure2 采用深度层次内容信息的无约束人体属性识别的网络结构.
给定输入图片,计算其Gaussian金字塔,并送入CNN网络中,以得到多尺度的特征图.
从特征图中,提取四种边界框区域的特征集合:整个目标人物、目标人物的选定部位、图像金字塔中的邻近部位、全局图像场景. 后两种特征集分别对应分层内容信息:以人为中心信息和场景信息. 分别对四种区域进行分数计算,并相加以得到最终的属性分数.
基于 Fast R-CNN. 采用在ImageNet分类上预训练的VGG16作为基础网络,Fast R-CNN 首先得到候选区域,然后利用分类器和学习的特征将候选区域进行分类. 考虑到计算效率,共享了图像级的卷积操作,得到全局 conv5 特征图,以便于其后对各区域的ROI Pooling操作都基于conv5 特征图.
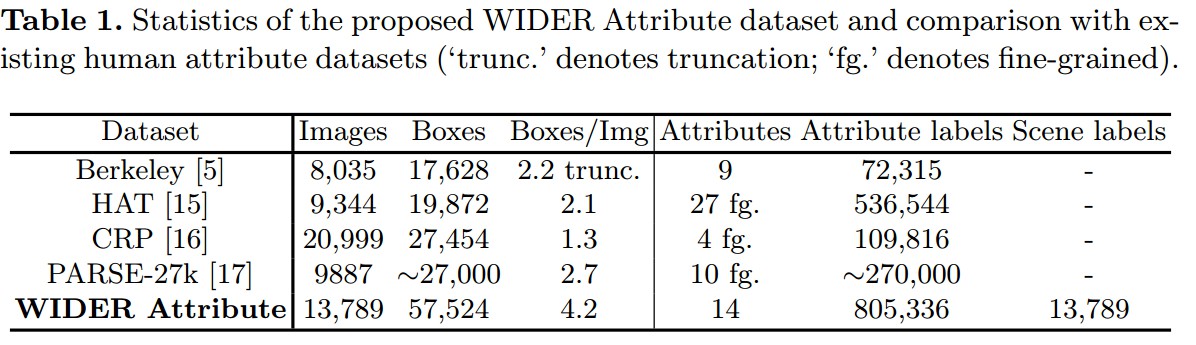
3. WIDER Attribute 数据集
Human Attribute Datasets
[Images (Google Drive)], [ Annotations]

