摘自论文:SIFT Meets CNN: A Decade Survey of Instance Retrieval - 2016

图:SIFT是计算从人工设定特征,CNN是利用大量神经网络提取特征。
实例检索发展:
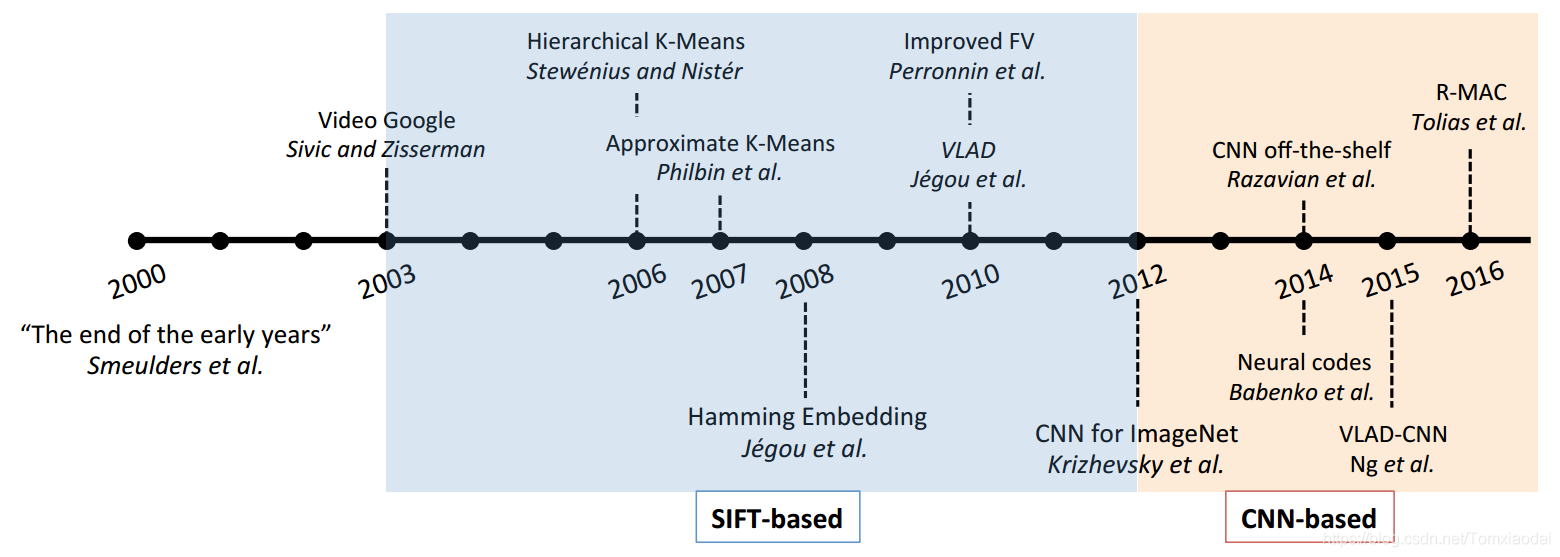
视觉表征可分为基于SIFT和基于CNN两大类:

基于SIFT的方法大多依赖于BoW 模型.
基于SIFT的方法分为以下三类:
[1] - 使用小码本. 视觉单词(visual words)不到几千字. 压缩向量(Compact vectors)是在降维和编码之前生成的
[2] - 使用中型码本. 由于BoW的稀疏性和视觉词的识别能力较低,采用了倒排索引(inverted index)和二进制特征。精度和效率之间的权衡是一个主要的影响因素
[3] - 使用大的码本 .考虑到稀疏的BoW直方图和较高的视觉单词识别能力,采用了倒排索引和便于记忆的特征。在码本的生成和编码中使用了近似方法