原文1:深度学习在用户画像标签模型中的应用 - 2019.07.04
原文2:电商用户标签服务系统建设及演进 - 2018.11.07
作者:Neway Liu
1. 用户画像标签
基于用户事实数据,进行一定抽象后的用户特征表示
拿电商为例,用户的购物性别,年龄,消费能力等都是用户画像的标签. 这些标签能帮助理解用户需求,将用户进行归类,进一步进行个性化运营,例如针对高消费人群,那可以展示比较有品味的服装给用户.
1.1. 标签建模方法
主要有两大类:
[1] - 人工建模
凭借经验,对标签定义一个数据描述口径,通过大数据ETL跑出标签结果,再逐步通过调整口径达到运营可接受的模型.
ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据.
ETL 是BI(商业智能)项目重要的一个环.
[2] - 机器建模
通过机器对标签样本数据的多维度学习,建立机器自学习的标签模型,可通过对样本数据的调整以及模型结构及参数的调整来逐步优化模型.
两种建模方式各有优缺点,这里介绍如何运用深度学习进行机器建模.
1.2. 基于深度学习的电商场景建模实例
以“孕妇标签”为例(电商场景下),逐步介绍基于深度学习的建模的.
1.2.1. 简陋模型
一开始思路很简单,将用户的各个品类购买行为做为模型训练的特征,并通过对品类划分中挑出和孕妇明显相关的品类(例如孕期护理,孕妇装,高跟鞋,彩妆等),通过某些品类的购买行为筛选出训练正负样本,例如按一年统计用户对各个品类的购买次数,若孕妇相关品类购买次数超过5次,则标识为正样本,若高跟鞋,彩妆类购买次数超过5次,则标识为负样本.
正负样本,模型训练需要的特征数据都有了,最简单的就是构造一个浅层神经网络模型,将数据丢给模型,看看模型能否自我训练学习,这就是模型最初的样子:
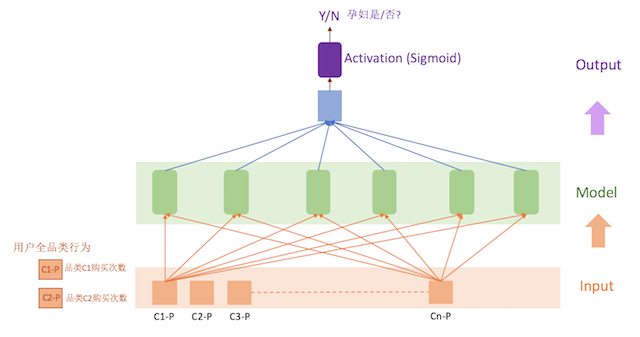
这个版本的模型直接用Keras构造,非常简单,也可以直接看到实时训练的情况. 准备了5万的样本训练数据,大概几分钟就可以发现模型的Training accuracy和Validate accuracy都达到了0.9以上,可以试试模型的效果,但要再找出一批已知是否孕妇的数据,是个大难题,所以比较直接的就是找了几个(女)同事的帐号,虽然测试数量少,但比较有代表性,很容易发现模型的问题: 对于几个月前是孕妇,现在已经是妈妈的情况,没有准确的识别出来. 想想,因为模型输入的数据是过去一年的购买记录,模型无法感知数据在时间维度上的变化.
1.2.2. 时序模型
由于孕妇标签的时间敏感性,模型中需要考虑时间维度,比如6个月前有购买过孕妇类,最近2个月已经不再买了,而是开始买婴幼品类的商品,这个说明现在已经不再是孕妇了,应该打上新生妈妈的标签了.
因此,首先在模型的特征维度上需要将一年的购买行为按时间间隔(月)拆开,同时将用户的购买行为数据放在一个时间轴上,这样可以提供更立体的特征数据给模型训练,于是选用了可以 感知时序数据的RNN模型,对用户某段短时间内的购买行为综合分析学习,这样模型更容易准确地判断出孕妇标签.
比如,用户购买平底鞋这个行为,一般情况下,对孕妇标签的判断没有太大的作用,但如果用户购买平底鞋的时候,还买了孕妇裤,这就不同了,购买平底鞋这个行为就变得和孕妇行为相关了,和标签结果就有一定的相关性. 就是因为加上用户前后购买行为这个Context,而让数据更立体,更丰富,模型对标签的判断也就更准确.
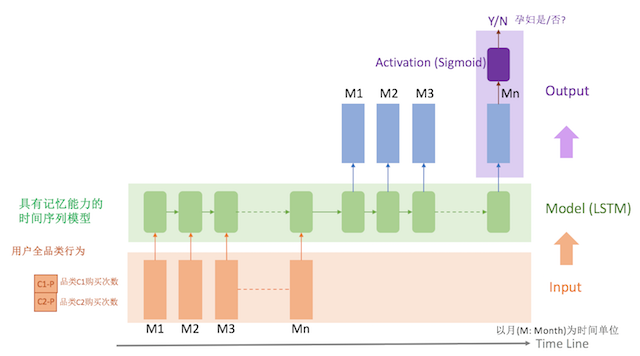
模型的特征是用户每个月对各个品类的购买次数,比如对最近18个月的,2000个品类进行统计,得到18*2000 的矩阵,作为一个用户的特征表示,所以模型的inputs维度是:user_num * months * categorys (e.g. 10000 18 2000),output targets维度是:user_num * 1 (e.g. 10000 * 1).
模型采用LSTM,对LSTM的最后一个output通过sigmoid映射到[0,1]后和target对比,计算得出lost函数.
模型训练完后,再用测试数据校验了下,已经可以准确区分出新生妈妈和孕妇了.
但这个模型的输入特征不够丰富,用户的行为除了购买之外,点击行为也是放进来,让学习维度更加丰富.
1.2.3. 多时序模型
从用户的浏览->点击->购买这个转化漏斗可以知道,用户的点击行为远比购买行为更频繁. 以月为单位,一个用户在某个品类的购买次数一般为1次,很少超过10次. 但点击不同,如果以月为单位统计,点击的数量会很大,这样会有什么问题?
假设按自然月统计,如果一个用户在1号那天就对某个品类点击次数达到10次,我们知道用户对这个品类是有偏好的,但如果放到1个月统计这个维度,10次可能还没达到模型认为有强相关的程度. 换句话说,就是模型无法实时感知到用户的偏好变化.
所以,针对点击行为,我们得采用以天为单位统计用户在各个品类下的点击次数,作为模型的输入. 这样就出现了购买行为和点击行为的两套时序模型,他们的时间维度不同,不能放在一套 LSTM 模型里,只能分开两套,再通过一层fully connected layer,将两套LSTM的输出作为这层的输入,得到最终的模型结果.
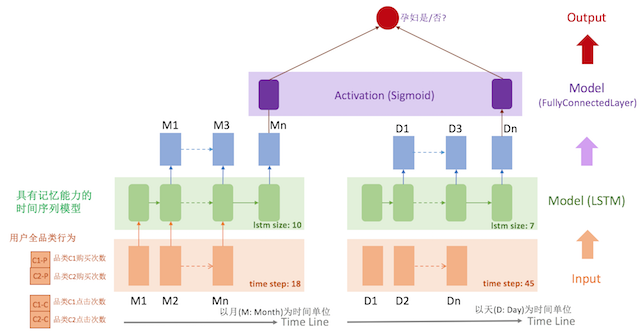
1.2.4. 模型调优
结合点击和购买时序行为的模型,使用样本的筛选规则得到的数据,都可以准确的识别出结果,但模型的泛化能力如何,会不会overfit,由于缺乏更丰富的数据样本,并不好验证这点.
所以,对于模型的评估,采取人工伪造数据的方式来校验,比如将训练样本中的购买数据全部抹掉,这样用一份只有点击的数据来校验模型对点击行为的学习能力;再比如将训练样本中强孕妇相关品类的购买,点击数据抹掉,来验证模型对其他“潜在”的相关维度的学习能力.
值得一提的是,模型的训练样本是按照一定的规则进行人工筛选标注完成的,而筛选的条件同时也是模型的学习维度中的一部分,这意味着模型很容易学习到这些“人工设定”的规则,而忽略那些“潜在”的维度和结果之间的相关性. 模型容易出现“Memorize more than Learning”,也就是缺失泛化能力.
如何提高模型的泛化能力:
[1] - 减少Hidden Size,降低模型记忆单元数
[2] - 增加Dropout,通过随机抹掉部分hidden layer的节点,类似通过让模型变得简单,同时通过将多个简单的模型的结果综合起来,达到提高泛化能力的目的
[3] - 采用L2 Regularizer,通过对权重的惩罚,来提高模型泛化能力
[4] - 提供更丰富的训练样本,让模型接触更多不一样的数据
1.2.5. 总结
[1] - 深度学习模型更像一个黑盒子,无法通过因果关系进行逻辑推导,而只能通过不同的数据不断从外部试探,理解模型
[2] - 人的很多特征都是会随着时间变化的,用户画像的标签建模是需要考虑好时间维度的数据
[3] - 用户画像标签模型的数据样本获取成本大,通过规则筛选的数据,不够丰富,容易导致模型泛化能力差
2. 电商用户标签服务系统
随着电商平台的体量越来越大,用户个性化运营的诉求也越来越突出,用户标签系统,做为个性化千人千面运营的基础服务,应运而生. 唯品会的用户标签系统,目前已全面服务于唯品会的各种个性化运营场景,包括站外广告定向人群投放,站内个性化运营玩法,用户触达个性化沟通,提供包括用户的基础人口属性标签,设备属性标签,用户兴趣标签,用户行为标签,以及用户的会员属性标签等,为公司的千人千面策略提供最基础的数据服务.
用户标签系统搭建的初期,主要还是依靠运营同学的人工经验基于规则圈人群运营,之后随着不断提升运营的效率,系统逐步转变成为运营赋能的用户标签数据平台,不仅仅提供用户标签数据,还包括用户画像分析服务,辅助业务运营进行人群洞察分析,以及通过算法能力,帮助业务方优化运营策略,实现策略的效果最大化. 整个演进的过程围绕着业务的诉求不断升级,可分为三个阶段,本文将逐一进行介绍.
2.1. 用户标签服务0-1
其实在用户标签服务这个系统诞生之前,公司存在多个提供用户标签数据的系统,有些标签是由A系统提供,有些由B系统提供,同时根据数据最终提供的形式的不同,又分别存在以人群包为维度提供离线批量获取用户的系统以及将人群包标签化打到用户上,提供以用户为维度的在线标签查询的系统. 因此,用户标签服务系统的搭建,一方面是整合管理散乱在各处的用户标签数据,另一方面也是对用户标签业务的统一管理.
系统建设的初期,业务诉求主要集中在基于已经存在的用户基础标签之上,根据业务经验总结出的各类规则进行圈人群,从而达到精准营销的目的. 比如针对华南区的用户做一次美妆活动,业务要找出最近一个月有收藏过美妆品类商品或者最近一个月有浏览过美妆品类商品的华南区女性用户,对她们进行精准触达召回营销,同时在站内也会针对这群用户投入相应的广告位来吸引她们.
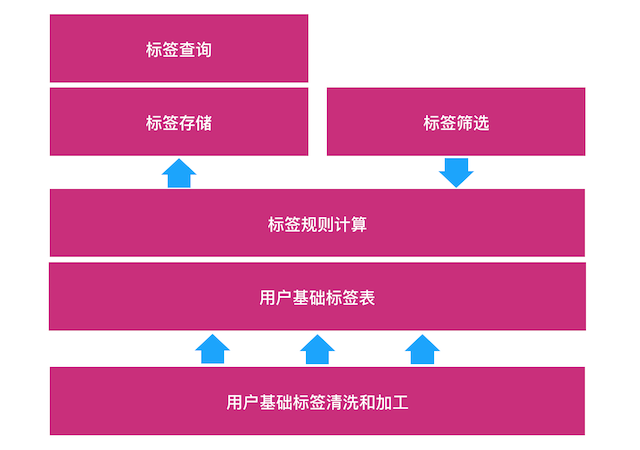
围绕业务的需求场景,用户标签系统初期的建设主要围绕:
- 用户基础标签清洗和加工
- 业务运营标签规则计算
- 标签存储
- 标签查询
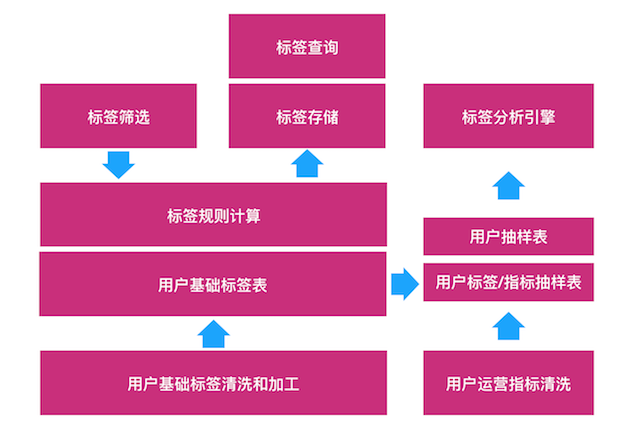
系统整体架构如下:
2.1.1. 用户基础标签清洗加工
根据不同的场景需求以及数据本身的时效性特点,目前基础标签的清洗加工分为离线和实时两套处理方式.
[1] - 离线处理主要通过Hive/Spark以天为单位进行数据清洗和加工;
[2] - 实时处理则通过Kafka接入业务实时数据源,再由Storm流式处理,实时清洗和加工.
2.1.2. 业务圈人标签规则计算
基于用户的基础标签,业务方从运营的角度可筛选各类日常运营的人群标签,例如最近一周有浏览Nike运动鞋但没有购买的人,有这样行为的人,可认为是近期对Nike运动鞋非常感兴趣的人群,给他们打上标签后,便能针对这群人进行精准触达沟通和站内外的广告投放了.
标签规则计算大部分是通过离线(以天为单位)计算完成,借助一套标签规则的解析引擎,将标签规则转化为数据层面的计算逻辑,完成计算后得到该标签对应人群,同时系统提供一套灵活的基础标签配置管理,在基础标签数据开发完成后,通过配置便可快速完成该标签的上线工作.
为了保证标签数据的准确性,系统提供了一套简单有效的数据质量检查机制,例如通过对比圈选的人群最近几天的人数变化情况,对有人数突变的人群及时告警,再通过人工的介入进行二次排查,可及时发现至少80%的数据质量问题. 同时,为了减低数据问题对业务的影响,系统保留了最近1-2天的数据版本,在当前数据版本出现问题时,可快速回退至之前的数据版本,降级提供前天(有损)的数据.
2.1.3. 标签存储及查询
通过标签规则计算的标签结果,最终以用户ID List的形式存储在Hive表里,鉴于公司用户规模比较庞大,最终一个标签的用户数量往往有百万级,多的甚至达到千万级. 为了提供稳定快速的人群取数服务,系统内部会先将标签结果拉取到Redis,最终查询接口通过Redis里的标签数据提供查询服务.
标签查询服务从业务使用的方式上可划分为两类:A)以标签为维度,将符合该标签的所有用户都取出来,业务使用方式以批量发送Push/短信为主;B)以用户为维度,查询该用户身上是否符合某个标签或多个标签,业务使用方式包括广告定向投放,站内个性化运营等. A是离线批量查询,B是在线实时查询,在标签存储上对这两类以不同的形式分开存储.
首先,将Hive表中的标签结果用户ID List数据同步到Redis中,也是以 List 的形式存储,为了避免产生Redis 的大Key,以及提高数据同步的并行度,这里的 List 是逻辑上的,实际存储时则是以一段段的小List 拼接而成,同时,为了节省Redis的存储空间,将多个User的ID拼接作为List的一个element:
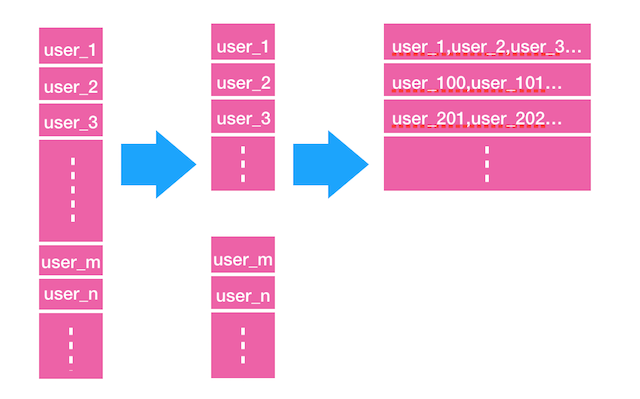
另外,为了提供用户维度的标签查询,需要对用户打标签,在上面的生产的Redis List数据中,对拥有该标签的每个user进行遍历,以用户id为key,标签id为field,标签值(符合/不符合该标签)为value构造Redis的hash结构,一个hash存储一个用户身上的所有标签. 对用户标签的查询,采用Redis针对hash结构的hmget 操作即可获取某个用户的一个或多个标签的值.
上面说了标签存储和如何进行查询,那么标签数据的更新是怎样的呢?对于业务会经常使用的标签,数据是保持每天更新的,但往往变化的差异是比较小,因此为了提升用户打标签的速度,在同步标签结果时,系统会生成多一份该标签的用户id bitset,通过和昨天的数据bitset进行差集比较,可快速标识出每天变化的用户,进行增量打标,可大幅提高打标速度.
最后,在数据可靠性上,对极其重要的业务所用到的标签数据,数据的可靠性要求非常高,使用Redis作为存储的方案存在一定的风险,因此,针对这部分重要标签,同时会有一套MySQL的存储,当Redis出现问题时,可快速回源到MySQL进行标签的查询. 在MySQL的表结构设计上,没有采用以用户id为主键的方式,主要是考虑到数据的更新是以标签为维度,对用户进行批量更新,而一个用户也可能同时存在多个标签中,以用户id为主键会导致数据的更新逻辑复杂,无法对用户批量更新,数据更新速度慢;因此,同时考虑到数据更新的问题和标签查询的性能,最终采用以标签id为主键,沿用上面bitset的思路,将该标签的用户id构成的逻辑上的一个大bitset,按照顺序等长拆分为多个 bitset_segment:
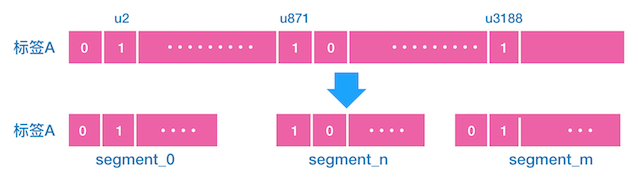
假设 bitset 的总长度有5亿,就代表最多可以表示5亿用户,例如上图中,符合标签 A 的有 u2,u871,u3188等,根据每个用户的序号,可以计算出每个用户所属的 bit index,在标签 A 的 bitset 中对应位置index 设为1,这是逻辑上的 bitset,实际存储时会将 bitset 按顺序拆分成多个 bitset segments,假设有50 个 segments,那么每个 segment 就1千万个bit,而每个用户所属的 segment index 以及 segment 中的 bit index 也是可以由用户的序号计算出来的,这样对用户标签的查询操作,更新操作,都转为标签id+segment_id 进行操作.
2.2. 用户标签服务2.0 – 用户画像分析引擎
在满足用户个性化标签运营需求后,为了帮助业务方高效的进行个性化人群标签的筛选,系统提供了一套用户画像分析引擎–天眼,借助天眼强大的分析能力,可实时地查看标签筛选人群结果的画像构成:包括人群数量规模;人群的基本用户信息,例如性别/年龄/地域/会员等级分布等;用户行为信息,例如购买品牌品类分布,访问频次,深度,时段等;以及人群维度的一些运营指标,例如最近UV,转化率等. 这样业务方可快速调整筛选人群的条件规则,找出认为适合的人群.
这是2.0的系统整体架构图:
为了能实时并且准确的提供用户画像分析能力,系统采用 Elasticsearch(ES)作为分析引擎,利用其快速的查询性能和数据聚合能力,可 实现秒级完成各种复杂的条件组合和数据聚合运算. 另外,由于用户的数据规模庞大,考虑到ES索引存储以及数据更新的压力,放入到ES的索引数据为抽样的用户数据,在满足数据准确性的同时,尽量降低ES的压力.
2.2.1. 索引数据结构设计
一个用户对应一个doc,用户的标签信息是doc fields,简单的标签例如性别,年龄,直接使用普通的fields即可;一些复杂的标签信息,例如用户对品牌A的最近一个月浏览次数这类,属于用户和品牌一对多的动态标签信息,需要采用 nested fields,一个简单的示例结构如下:
{
//normal fields
"basic_info": {
"age": 20,
"gender": "female"
},
//nested fields
"brand_info": [
{
"brand_id": "123456",
"brand_last_purchase_date": "2018-01-01",
"brand_30d_visit_cnt": 10
},
{
"brand_id": "67890",
"brand_last_purchase_date": "2018-01-05",
"brand_30d_visit_cnt": 16
}
]
}2.2.2. 用户标签抽样表设计
采用 id 取模的方式对用户进行抽样,可确保每次抽样的用户基本固定. 同时,抽样用户的标签信息由多张Hive 表存储,例如基础信息表,品牌行为信息表,品类行为信息表等,有的是和用户成1:1 关系,有的是和用户成 1:n 关系的,例如品牌行为信息表. 在处理这些表的数据时,也会做一些小优化,例如时间类型的统一采用日期形式,这样可以节省ES的存储空间.
2.2.3. 索引数据更新机制
抽样的用户标签数据在Hive表中完成更新后,需要再同步到ES中,数据刷新的机制经历过多次的优化迭代,一开始通过Hive表中的数据为每个抽样用户构造完整的用户json数据,再通过一个Job将ES中的数据进行全量更新,更新过程中发现更新认为的Job应用cpu非常高,主要原因是每个用户的json数据特别大,而且很复杂,在将Hive的数据序列化成一个大json时CPU消耗非常大;后来逐步优化,将全量更新调整为用户级别增量更新,并且由原来的完整json改为仅对有变化的fields按Hive表拆分各个不同fields group构造json,分批部分更新,采用小步快跑的方式完成索引数据的更新.
3.3. 用户标签服务3.0 – 智选标签
回顾系统在1.0和2.0两个阶段,都是围绕业务根据经验筛选人群,建立标签而建设的,而业务的最终诉求,是要找出符合某些运营场景的人群,并结合运营策略实现运营目标的最大化. 例如前面例子中描述的“最近一周有浏览Nike运动鞋但没有购买的人”,背后的需求其实是找出“最近对Nike运动鞋有购买倾向的人”,放入到对应的广告/Push等运营活动中,达成活动的运营目标,比如转化率达到多少,至于如何找出最近有购买倾向的人呢?根据业务经验,认为“最近一周有浏览过但又没有购买的人”是一个潜在的购买客群,但并不一定是最精准的人群,在现在这样一个智能时代,运用数据的积累,算法的挖掘,借助机器学习建立模型,能找出更合适的人群,同时再结合运营策略,满足运营目标的最大化需求,这就是3.0的智选标签服务.
3.0的标签模型框架:
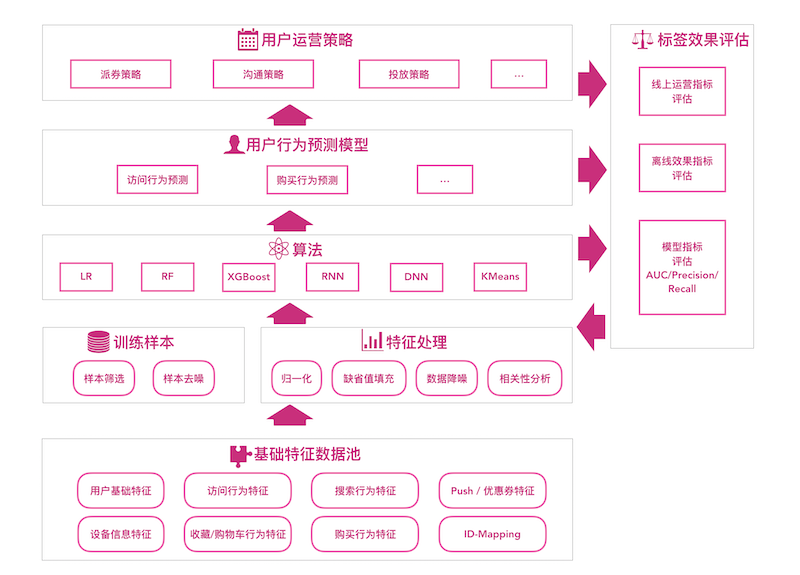
- 用户特征池:为标签模型构造用户全方位的特征数据,包括用户基础信息特征,用户设备信息特征,用户访问/搜索/购买等行为特征,以及用户品牌/品类行为特征等.
- 用户行为预测模型:基于Spark ML的机器学习模型和Tensorflow的深度学习模型,构建用户基础行为预测模型.
- 用户运营策略:运营策略的目标考虑因素比较多,现阶段主要以人工的方式基于用户行为预测模型制定运营策略.
- 效果评估:包括模型层面的评估指标,以及模型应用场景下的业务指标,离线验证模型的有效性,再结合运营策略通过线上ABTest进行验证最终运营效果.