原文:Surpassing Human Judgement for Fashion Style - 2019.02.21
这里主要分析机器如何区分时尚风格.
对此,超越了之前对于时尚风格分类的艺术表现,并证明计算机视觉算法能够在感知服装风格方面明显超过人类用户.
目标:从 14 个不同的时尚风格中,检测时尚照片的风格.
采用 ResNet-34 模型,这里分享一些技术以及 fastai v1 的定制化,用于解决该问题.
1. 方法
论文 What Makes a Style: Experimental Analysis of Fashion Prediction-2017 中,Simo-Serra 新创建了 13234 张图片数据集,并尝试区分 14 种不同的时尚风格.
还可以进一步参考 Hipsterwars dataset,其仅有 1893 张图片,5 种不同的风格类.
1.1. Fashion 14 Dataset
时尚风格相关数据的收集是很有挑战性的. 数据集中的图片往往是从时尚网站收集得到的,如 chictopia.com,以及利用网站的 meta-information 噪声标签.
Simo-Serra 手工删除了容易误分类的图片,并得到了清晰标注的 Fashion 14 数据集. 例如:
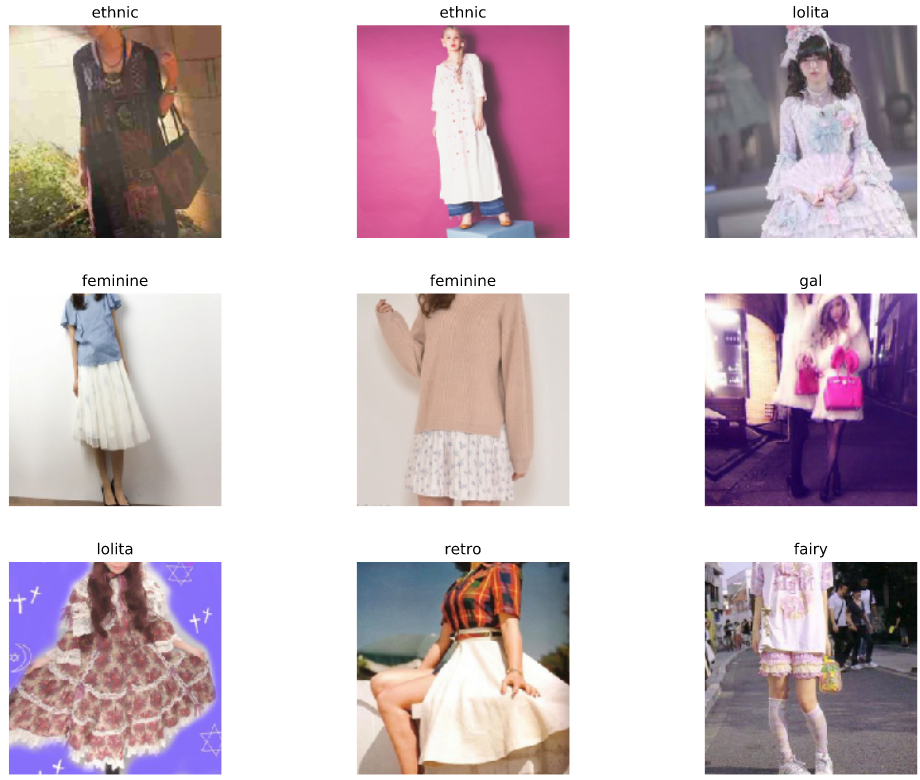
图 1 - Fashion 14 数据集例示
What Makes a Style: Experimental Analysis of Fashion Prediction-2017 论文里介绍了作者将数据集划分为了 training、validation 和 test 数据集(60%, 5%, 35%),但是下载的数据包中, "train.csv", "val.csv", 和 "test.csv" 三个 csv 文件与论文里的说明存在许多差异,如图片总数、每个子集中的类别数、部分文件名缺失等.
1.2. 训练流程
类似于 Simo-Serra,这里也将数据集划分为 training、validation 和 test 三个数据子集(60%, 5%, 35%).
采用 fastai 实现一系列的图像变换,因此得到的网络可以很容易的概括每种时尚风格.
然后,利用 fastai 实现的学习率调整策略(Leslie Smith’s 1cycle learning rate policy),采用 5e-2 的学习率,对分类器的 head 网络层 fine-tuned 两个 epochs.
接着,采用 1e-6 和 5e-4 之间的学习率,对整个网络训练多于 13 个 epochs.
最终,在 vailidation 数据集上取得了 77.6% 的最大准确率.
2. Results
采用比 Simo-Serra 所使用网络更浅的网络,由于 fastai 提供的优化方法,作者取得了领先的结果,在某些场景下超越了人类的分类能力.
经过测试时的变换(TTA, test time transformations),得到了 78.49% 的准确率,而 Simo-Serra 的最高准确率为 72.0%. 且在 14 个时尚类别中,12 个都是占优的.
| conserv. | dressy | ethnic | fairy | feminine | gal | girlish | casual | lolita | mode | natural | retro | rock | street | average | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ResNet34 fastai | 0.72 | 0.90 | 0.79 | 0.91 | 0.80 | 0.73 | 0.61 | 0.69 | 0.95 | 0.73 | 0.80 | 0.72 | 0.78 | 0.86 | 0.78 |
| ResNet50 | 0.66 | 0.91 | 0.74 | 0.88 | 0.64 | 0.74 | 0.47 | 0.66 | 0.92 | 0.72 | 0.70 | 0.62 | 0.68 | 0.69 | 0.72 |
| VGG19 | 0.54 | 0.79 | 0.57 | 0.81 | 0.43 | 0.50 | 0.26 | 0.54 | 0.80 | 0.62 | 0.56 | 0.42 | 0.53 | 0.60 | 0.58 |
| Xception | 0.44 | 0.79 | 0.63 | 0.84 | 0.45 | 0.50 | 0.33 | 0.54 | 0.80 | 0.61 | 0.56 | 0.44 | 0.52 | 0.53 | 0.58 |
| Inception v3 | 0.37 | 0.73 | 0.54 | 0.78 | 0.41 | 0.39 | 0.27 | 0.45 | 0.78 | 0.55 | 0.44 | 0.35 | 0.47 | 0.46 | 0.51 |
| VGG16 | 0.31 | 0.78 | 0.49 | 0.78 | 0.42 | 0.45 | 0.22 | 0.43 | 0.81 | 0.58 | 0.57 | 0.23 | 0.43 | 0.43 | 0.51 |
表 1 - 采用 ResNet34 fastai 的模型结果和 [1] 中的结果在前行.
论文作者还测试了两组人类对这些图片的分类,一组是专业的,一组是业余的. 专业组得到了 82% 的准确率;业余组得到了 62% 的准确率.
如下表,本文得到的模型结果在几类时尚风格类都超过了专业组: conservative (72% vs 59%), fairy (91% vs 89%), mode (73% vs 69%) and rock (78% vs 74%).
| conserv. | dressy | ethnic | fairy | feminine | gal | girlish | casual | lolita | mode | natural | retro | rock | street | average | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Savvy (human) | 0.59 | 0.92 | 0.80 | 0.89 | 0.84 | 0.92 | 0.71 | 0.75 | 0.95 | 0.69 | 0.81 | 0.79 | 0.74 | 0.91 | 0.82 |
| ResNet34 Fastai | 0.72 | 0.90 | 0.79 | 0.91 | 0.80 | 0.73 | 0.61 | 0.69 | 0.95 | 0.73 | 0.80 | 0.72 | 0.78 | 0.86 | 0.78 |
| Naive (human) | 0.35 | 0.87 | 0.64 | 0.83 | 0.60 | 0.62 | 0.51 | 0.50 | 0.83 | 0.29 | 0.57 | 0.50 | 0.58 | 0.74 | 0.62 |
表 2 - [1] 中专业组和业余组用户的结果与本文的 ResNet34 fast-ai 结果的对比.
混淆矩阵更清晰的描述了不同时尚风格类别的区分情况. 如下图,可以注意到,模型主要难以区分 kireime-casual 和 conservative 两个时尚风格.
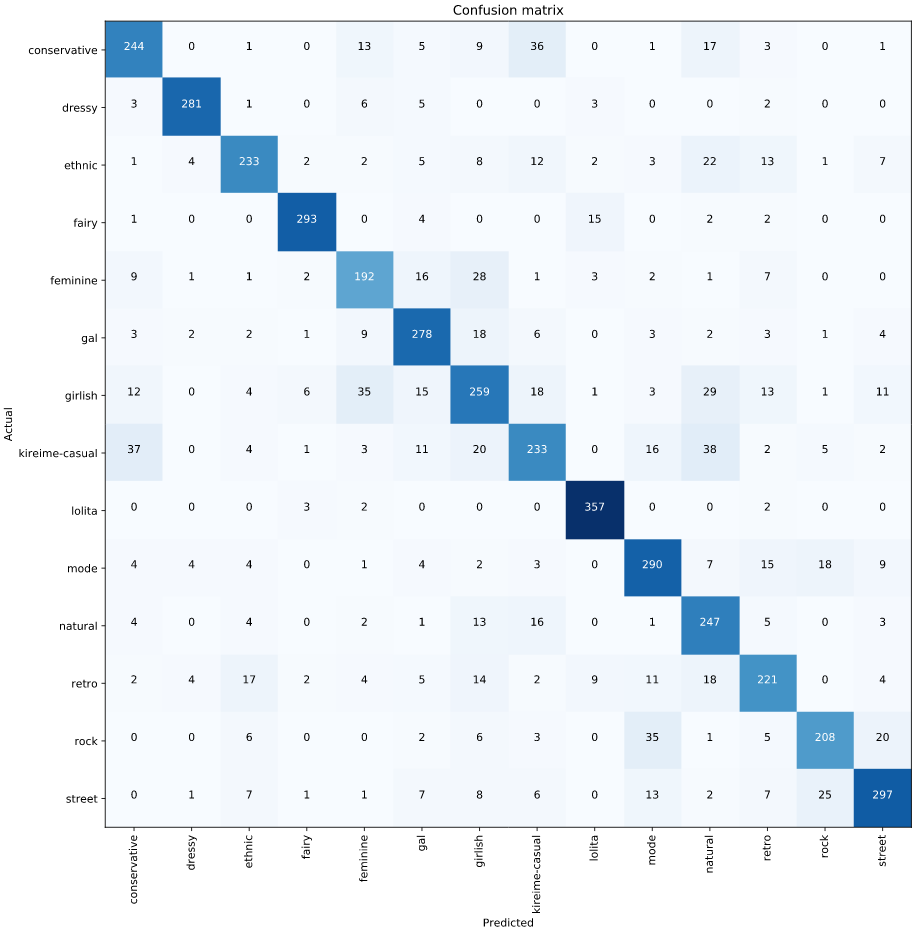
表 3 - test 数据子集的混淆矩阵
另外,还画出了一些 heatmaps,以显示网络模型是在关注于人的服装,以理解其风格,而不去关注背景区域.
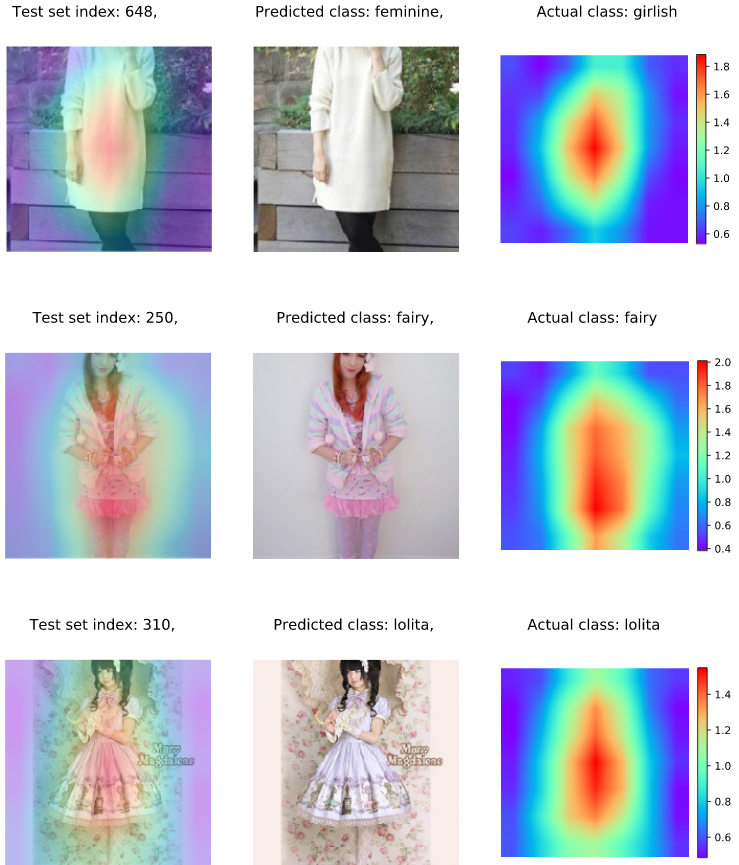

3. Hipsterwars Dataset
Hipster Wars: Discovering Elements of Fashion Styles - 2014
Hipsterwars 数据集共包含约 1900 张图片,5 种不同的风格: Hipster, Bohemian, Goth, Preppy, Pinup(时髦,波西米亚,哥特,Preppy,Pinup),其是通过游戏的方式人手工标注的.
这里尝试将得到的模型在 Hipsterwars 数据集上进行测试,验证模型的泛化能力.
3.1. 半监督分类
不进行额外的训练,直接根据 Fashion14 网络的中间层的输出之间的欧式距离,采用最近邻方法,得到结果. Simo Serrra 也对其论文里的中间层数据采用监督 SVM 进行处理.
这里计算在该投影空间中的 top1,top2 和 top3 的最近邻是否与输入图片具有相同标签. 结果显示了即使目标类别与训练类别不是相同的情况下,网络也可以聚类相似图片.
| Top 1 | Top 2 | Top 3 | |
|---|---|---|---|
| Stylenet Joint w SVM | 0.64 | 0.80 | 0.86 |
| ResNet34 Fastai (ours) | 0.53 | 0.69 | 0.78 |
| VGG CNN_M | 0.45 | 0.64 | 0.76 |
| VGG16 Places | 0.40 | 0.61 | 0.72 |
表 4 - 在 Hipsters Wars 数据集上采用特征距离的不同深度网络间的对比.
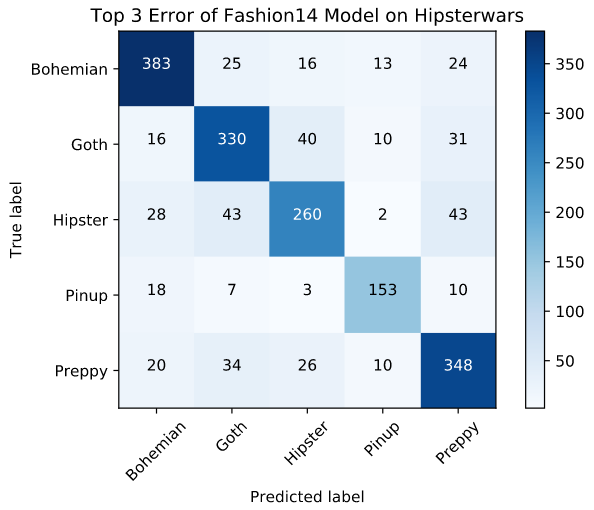
表 5 - 在 Hipsterwar 数据集上模型 top-3 预测结果的混淆矩阵.
4. platform.ai 可视化
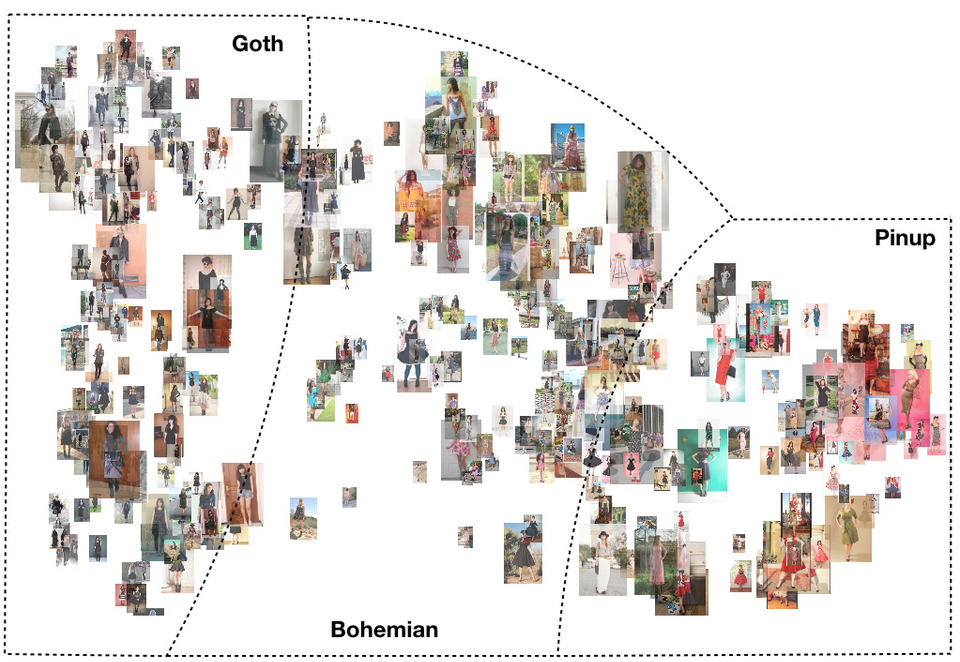
图 3 - Hipsterwars 的 3 种时尚风格的可视化
5. 总结
基于 fastai,可以很方便的采用迁移学习训练时尚风格分类器,并在 Fashion 14 数据集上取得了领先的结果.
fastai 的可视化工具有助于对数据集特点的分析理解,并确保模型能够感知时尚风格.
6. 参考文献
[1] - Moeko Takagi and Edgar Simo-Serra and Satoshi Iizuka and Hiroshi Ishikawa, What Makes a Style: Experimental Analysis of Fashion Prediction. Proceedings of the International Conference on Computer Vision Workshops. ICCVW, 2017.
[2] - M. Hadi Kiapour, Kota Yamaguchi, Alexander C. Berg, Tamara L. Berg. Hipster Wars: Discovering Elements of Fashion Styles. In European Conference on Computer Vision. 2014.
[3] - Edgar Simo-Serra and Hiroshi Ishikawa, Fashion Style in 128 Floats: Joint Ranking and Classification using Weak Data for Feature Extraction. Proceedings of the Conference on Computer Vision and Pattern Recognition. CVPR, 2016.
5 条评论
博主,我是一名研究生,正在做服装风格分类的课题,博主可以分享一下数据集吗,344513520@qq.com
这个数据集可以直接下载的,http://tamaraberg.com/hipsterwars/
博主您好,我是服装工程专业的学生,想做小样本的服装样板识别和分类,因为是自己做所以样本量很小,可能1000-1500张左右。
请问这个样本量您觉得用什么图像识别方法比较好呢?曾经咨询过,有人说这个样本量也能用卷积神经网络做,也有人建议SVM即可。
请问关于小样本学习,迁移学习可行吗?
感谢您在空闲之余回复!
特定训练样本数据集的话,尤其量比较少的情况下,现在涉及的相关研究不多,能做的方法很多,但能达到期望要求的可能需要具体情况具体分析了.
感谢回复!需要多试一些方法吗?请问您有一些推荐的图像识别方法吗?我想去了解一下,谢谢!