题目: CenterLoss - A Discriminative Feature Learning Approach for Deep Face Recognition
作者: Yandong Wen, Kaipeng Zhang, Zhifeng Li and Yu Qiao
团队: CAS, CUHK
ECCV2016 poster
1. 摘要:
Center Loss For Face Recognition - 提高CNN学习的特征的判别能力.
Center Loss 通过学习每一类的深度特征的中心,同时惩罚深度特征与对应的类别中心的距离.
Softmax Loss + Center Loss,可以同时增加类间分散程度(inter-class dispension)与类内紧凑程度(intra-class compactness).
由于CNNs模型采用SGD方法以 mini-batch 的方式进行优化,难以很好的反应深度新特征的全局分布. 且对于大规模训练集,也很难将所有的训练样本一次性的输入到每次迭代.
contrastive loss 和 triplet loss 存在图像 pairs 和 triplets 构建的问题,训练样本的图像采样较为复杂.
基于 CNN 网络的典型框架:
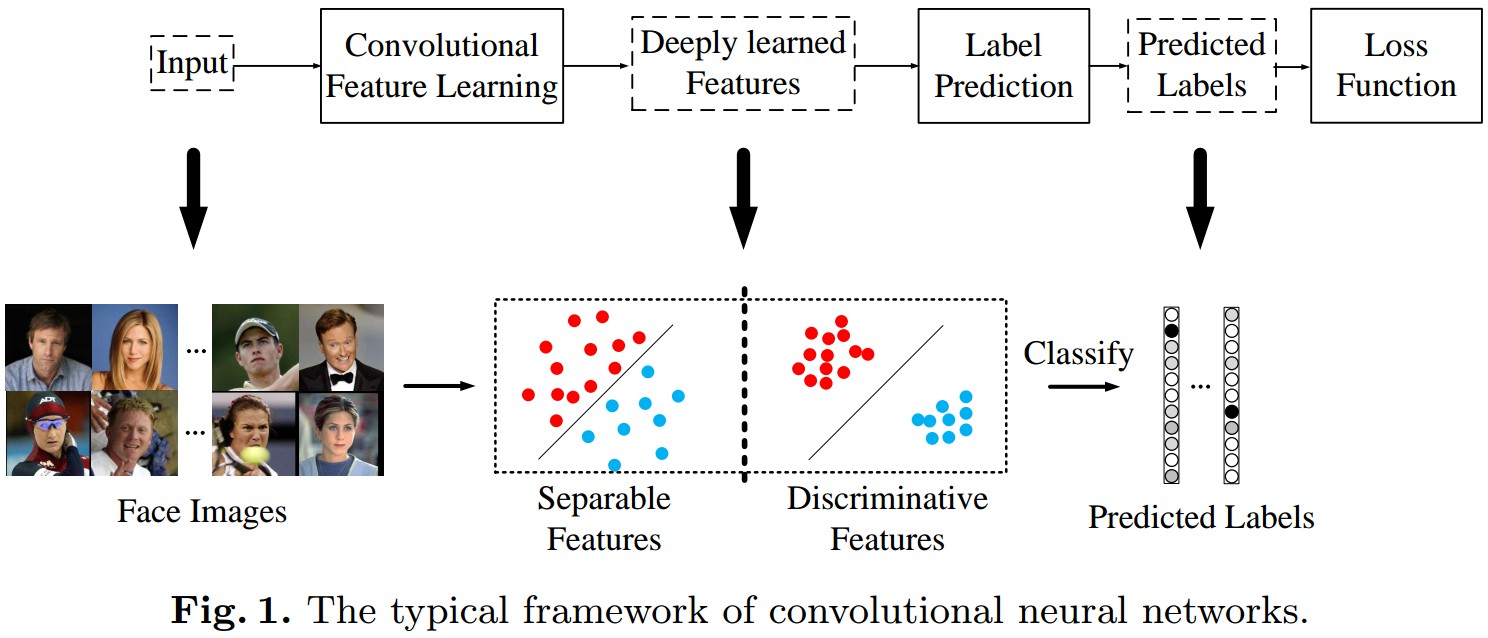
将人脸图片输入到 CNN 网络,进行特征学习以得到深度特征,包括可区分特征和判别特征,然后进行 label 预测.
对于深度特征分布情况的分析:
以 MNIST 数据集, 采用 LeNets 网络,Softmax Loss,提取最后一层网络输出的 2 维特征,并进行可视化.
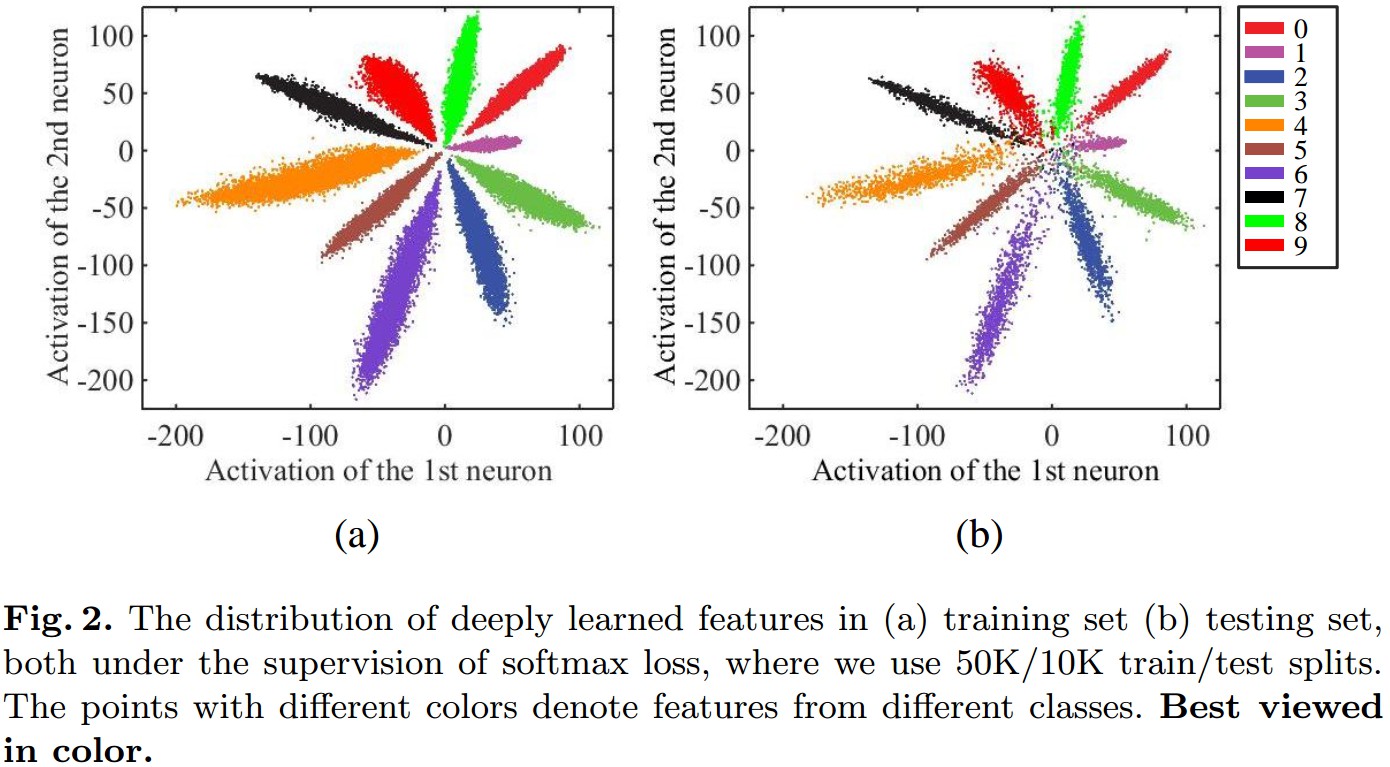
Figure 2. 深度学习特征分布的可视化. (a) 训练集 (b) 测试集.
网络的最后一个全连接层相当于线性分类器,不同类的深度特征通过决策边界(decision boundaries)被区分.
由 Figure 2 可知,
- 基于 Softmax Loss 监督学习的深度特征是可区分的;
- 由于特征显著的类内变化,深度特征的判别能力不够. 某些类内距离大于类间距离.
1. Softmax Loss
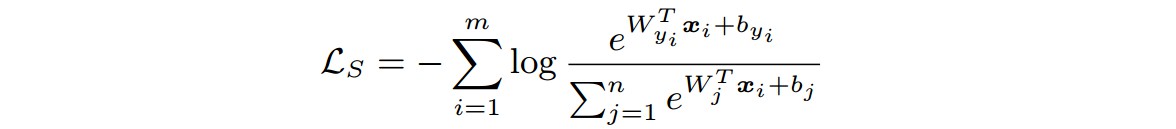
${ \mathbf{x}_i \in R^d }$ - 属于第 ${ y_i } $ 类的第 i 个深度特征;d - 特征维度;
${ W_j \in R^d }$ - 最后全连接层的权重 ${ W \in R^{d×n} }$ 的第 j 列;
${ \mathbf{b} \in R^n }$ - bias 项;
m - mini-batch 大小;
n - 类别数.
2. Center Loss
提升深度特征的判别能力:
最小化类内距离,同时保持不同类别特征的可区分性. [Intuitively, minimizing the intra-class variations while keeping the features of different classes separable is the key. ]
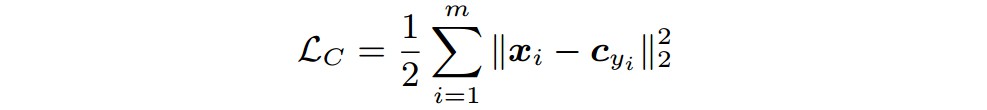
${ \mathbf{c}_{y_i} \in R^d }$ - 深度特征的第 ${ y_i }$ 个类别中心.
理想情况下,${ c_{y_i} }$ 随着深度特征的学习而进行更新. 也就是说,需要在每次迭代中将整个训练集都考虑在内,并对每一类的特征进行取平均. 但这是不可行,甚至不切实际的.
这里进行两处必要的改进:
[1] - 对 mini-batch 内的训练样本进行更新,而不是对整个训练集的各类别中心进行更新;每次迭代过程中,只对对应类别的特征进行平均计算,(某些类别中心可能不进行更新.)
[2] - 为了避免少样本类别造成的较大干扰,采用一个因子 ${ \alpha }$ 来控制类别中心的学习率.
${ L_c }$ 关于 ${ \mathbf{x}_i }$ 的梯度和 ${ \mathbf{c}_{y_i} }$ 的更新计算为:
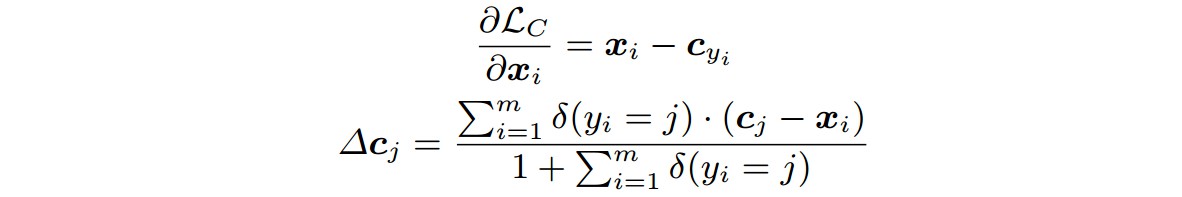
如果 condition=True, 即条件成立, 则 ${ \delta(condition) = 1}$,否则, ${ \delta(condition)=0 }$;
${ \alpha \in [0, 1] }$.
采用 Softmax Loss + Center Loss 来进行判别特征学习:
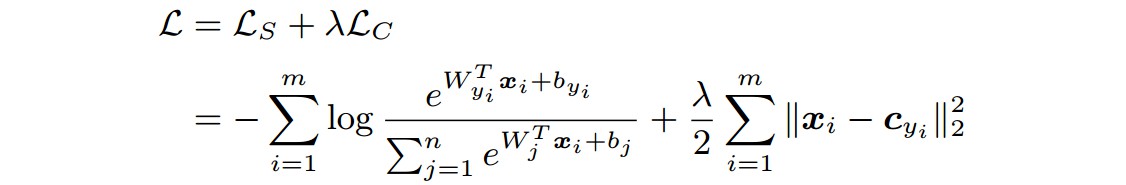
其中,${ \lambda }$ 为控制两个损失函数的 balance 因子,如果 ${ \lambda = 0 }$ ,即是 Softmax Loss.
SGD 优化过程:

$\lambda$ 对于特征分布的影响如图:

Figure 3. 基于 Softmax Loss 和 Center Loss 联合监督所学习深度特征的分布情况. 不同颜色的点表示不同类别的特征. 不同的 ${ \lambda }$ 值对应不同的深度特征分布(${ \alpha = 0.5 }$). 白色的圆点(${ \mathbf{c}_0, \mathbf{c}_1, ..., \mathbf{c}_9 }$) 分别表示 10 类深度特征的类别中心.
合适的 ${ \lambda }$ 值能够明显提高深度特征的判别能力. 而且,在一个较大范围内的 ${ \lambda }$ 值,特征均具有可区分性. 这对于人脸识别是很有帮助的.
3. Discussion
3.1. Softmax Loss + Center Loss 联合训练的必要性
如果只采用 Softmax Loss,深度特征类内离散度较大.
如果只采用 Center Loss,深度特征和类别中心将趋近于 0(此时,Center Loss 非常小.)
单独的采用一个 Loss,难以达到判别性特征学习的目的. 因此,需要进行联合训练.
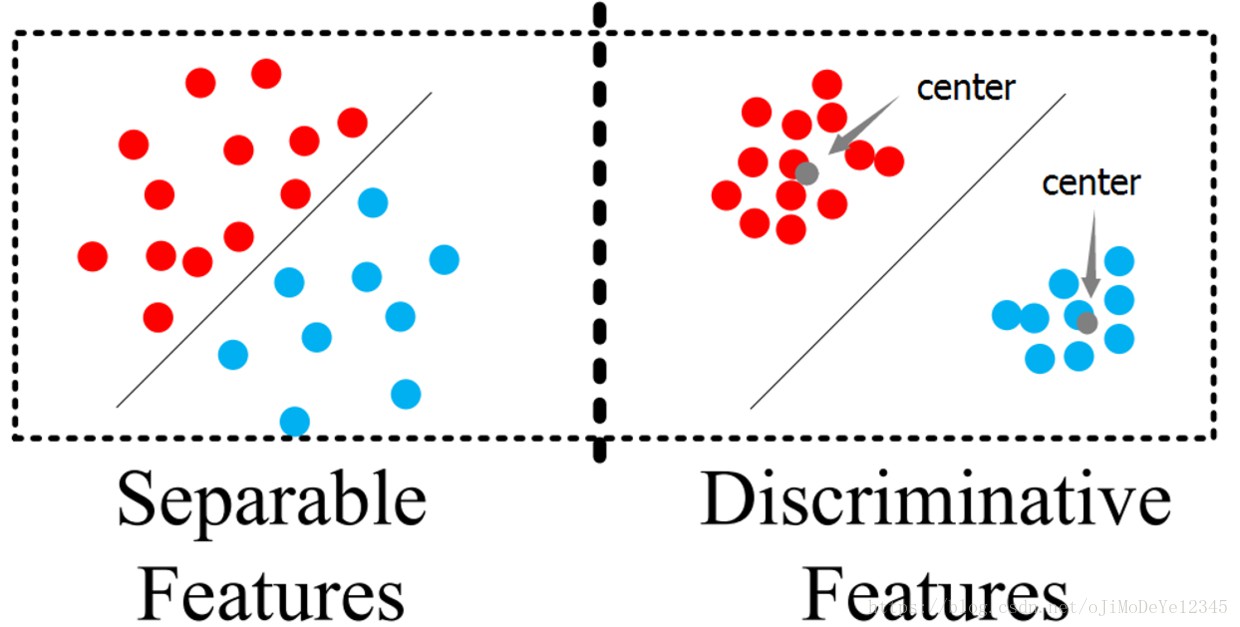
Figure . (左) 基于 Softmax Loss 的特征; (右) 基于 Center Loss 的特征. Center Loss 是使得任意红色特征点之间的距离小于红色特征点与蓝色特征点之间的距离,以确保最好的不同特征类别的划分.
3.2 对比 ContrastIve Loss 和 Triplet Loss
ContrastIve Loss 和 Triplet Loss 均是被用来提高深度特征的判别能力. 但是,基于大规模数据集时,需要面对庞大的样本对和样本 triplets 采样的问题.
Center Loss 与 Softmax Loss 采用相同的训练数据格式,不需要复杂的训练样本重采样.
因此,Center Loss 易于实现,效率更高;Center Loss 通过直接学习类间的紧凑度,更有利于判别性特征学习.
4. Center Loss for Face Recognition
- 网络结构
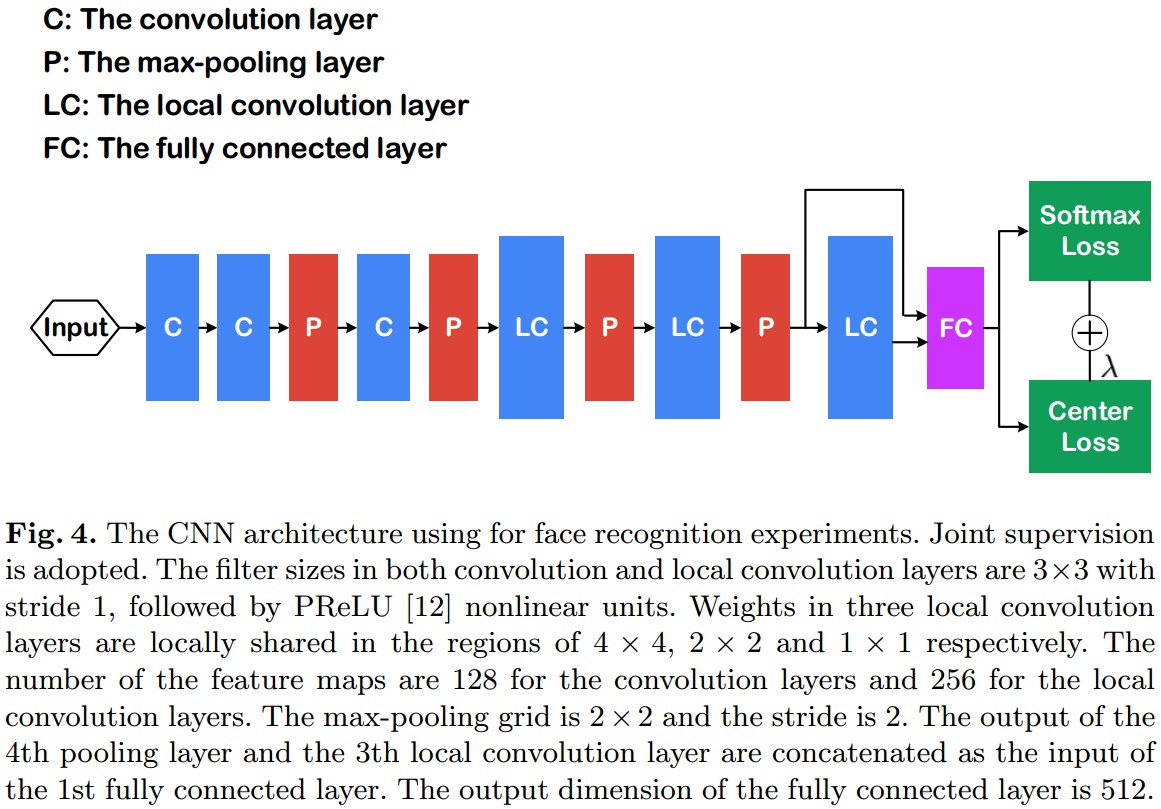
Figure 4. 人脸识别的 CNN 网络. 基于 Center Loss + Softmax Loss. - 数据
首先检测所有的人脸图片及对应的 landmarks. 采用 5 个landmarks(2 eyes, nose 和 mouth corners) 来进行相似度变换.
如果训练图片的人脸和 landmarks 检测失败 ,则丢弃该图片;但如果是测试图片,则仍采用提供的 landmarks.
人脸图片裁剪为 112×96 的 RGB 图片. 每个像素值减去 127.5 的均值(中心化),并乘以 1/128=0.0078125 的尺度.
- 数据集
CASIAWebFace
CACD2000
Celebrity+ - 数据增广 —— 水平翻转
- 数据集
CNNs 网络设置
models - batchsize = 256 / 2 GPUs(Titan X)
model A - Softmax Loss
model B - Softmax Loss + Contrastive Loss
model C - Softmax Loss + Center Loss测试设置
将第一个 FC 层的输出作为深度特征.
提取每张图片和其翻转图片的特征,一起作为图像特征. 然后进行PCA 降维.
计算降维后的两个特征间的 Cos 距离,得到最终的 Score.
参考
[1] - Center Loss - A Discriminative Feature Learning Approach for Deep Face Recognition 论文理解
[2] - 人脸识别之caffe-face