PyTorch 提供了一些预训练模型,便于网络测试,迁移学习等应用.
1. torchvison.models
torchvison.models 包括:
1.1. ImageNet 1-crop error rates (224x224)
| Network | Top-1 error | Top-5 error |
|---|---|---|
| AlexNet | 43.45 | 20.91 |
| VGG-11 | 30.98 | 11.37 |
| VGG-13 | 30.07 | 10.75 |
| VGG-16 | 28.41 | 9.62 |
| VGG-19 | 27.62 | 9.12 |
| VGG-11 with batch normalization | 29.62 | 10.19 |
| VGG-13 with batch normalization | 28.45 | 9.63 |
| VGG-16 with batch normalization | 26.63 | 8.50 |
| VGG-19 with batch normalization | 25.76 | 8.15 |
| ResNet-18 | 30.24 | 10.92 |
| ResNet-34 | 26.70 | 8.58 |
| ResNet-50 | 23.85 | 7.13 |
| ResNet-101 | 22.63 | 6.44 |
| ResNet-152 | 21.69 | 5.94 |
| SqueezeNet 1.0 | 41.90 | 19.58 |
| SqueezeNet 1.1 | 41.81 | 19.38 |
| Densenet-121 | 25.35 | 7.83 |
| Densenet-169 | 24.00 | 7.00 |
| Densenet-201 | 22.80 | 6.43 |
| Densenet-161 | 22.35 | 6.20 |
| Inception v3 | 22.55 | 6.44 |
1.2. 网络模型的使用
1.2.1. 基于随机初始化权重参数的模型构建
如:
import torchvision.models as models
resnet18 = models.resnet18()
alexnet = models.alexnet()
vgg16 = models.vgg16()
squeezenet = models.squeezenet1_0()
densenet = models.densenet161()
inception = models.inception_v3()1.2.2. 基于预训练模型初始化权重参数的模型构建
import torchvision.models as models
resnet18 = models.resnet18(pretrained=True)
alexnet = models.alexnet(pretrained=True)
squeezenet = models.squeezenet1_0(pretrained=True)
vgg16 = models.vgg16(pretrained=True)
densenet = models.densenet161(pretrained=True)
inception = models.inception_v3(pretrained=True)某些模型在训练和评价阶段,包含不同的操作行为,如 batch normalization. 其切换可以采用 model.train() 和 model.eval().
torchvision 提供的所有预训练模型,需要保证网络输入图像是以相同的归一化方式进行处理的. 如,3-channel RGB 图像的 mini-batches,(3xHxW),其中 H 和 W 最小是 224. 图像像素值的区间范围是 [0, 1],然后采用均值mean = [0.485, 0.456, 0.406] 和方差 std = [0.229, 0.224, 0.225] 进行归一化.
如:
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
train_loader = torch.utils.data.DataLoader(
datasets.ImageFolder(traindir,
transforms.Compose([
transforms.RandomSizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize, ])),
batch_size=args.batch_size,
shuffle=True,
num_workers=args.workers,
pin_memory=True)2. 网络结构定义
2.1. AlexNet
Paper - One weird trick for parallelizing convolutional neural networks - 2014
# AlexNet
torchvision.models.alexnet(pretrained=False, **kwargs)网络结构定义 - alexnet
# https://pytorch.org/docs/stable/_modules/torchvision/models/alexnet.html#alexnet
import torch.nn as nn
import torch.utils.model_zoo as model_zoo
__all__ = ['AlexNet', 'alexnet']
model_urls = {
'alexnet': 'https://download.pytorch.org/models/alexnet-owt-4df8aa71.pth',
}
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), 256 * 6 * 6)
x = self.classifier(x)
return x
def alexnet(pretrained=False, **kwargs):
"""
AlexNet model architecture
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = AlexNet(**kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['alexnet']))
return model2.2. VGGNet
# vgg11 & vgg11_bn
torchvision.models.vgg11(pretrained=False, **kwargs)
torchvision.models.vgg11_bn(pretrained=False, **kwargs)
# vgg13 & vgg13_bn
torchvision.models.vgg13(pretrained=False, **kwargs)
torchvision.models.vgg13_bn(pretrained=False, **kwargs)
# vgg16 & vgg16_bn
torchvision.models.vgg16(pretrained=False, **kwargs)
torchvision.models.vgg16_bn(pretrained=False, **kwargs)
# vgg19 & vgg19_bn
torchvision.models.vgg19(pretrained=False, **kwargs)
torchvision.models.vgg19_bn(pretrained=False, **kwargs)网络结构定义 - VGGNet
# https://pytorch.org/docs/stable/_modules/torchvision/models/vgg.html
import torch.nn as nn
import torch.utils.model_zoo as model_zoo
import math
__all__ = [
'VGG', 'vgg11', 'vgg11_bn', 'vgg13', 'vgg13_bn', 'vgg16', 'vgg16_bn',
'vgg19_bn', 'vgg19',
]
model_urls = {
'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth',
'vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth',
'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth',
'vgg11_bn': 'https://download.pytorch.org/models/vgg11_bn-6002323d.pth',
'vgg13_bn': 'https://download.pytorch.org/models/vgg13_bn-abd245e5.pth',
'vgg16_bn': 'https://download.pytorch.org/models/vgg16_bn-6c64b313.pth',
'vgg19_bn': 'https://download.pytorch.org/models/vgg19_bn-c79401a0.pth',
}
class VGG(nn.Module):
def __init__(self, features, num_classes=1000, init_weights=True):
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.weight.data.normal_(0, 0.01)
m.bias.data.zero_()
def make_layers(cfg, batch_norm=False):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
cfg = {
'A': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'B': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'E': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
def vgg11(pretrained=False, **kwargs):
"""
VGG 11-layer model (configuration "A")
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
if pretrained:
kwargs['init_weights'] = False
model = VGG(make_layers(cfg['A']), **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['vgg11']))
return model
def vgg11_bn(pretrained=False, **kwargs):
"""
VGG 11-layer model (configuration "A") with batch normalization
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
if pretrained:
kwargs['init_weights'] = False
model = VGG(make_layers(cfg['A'], batch_norm=True), **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['vgg11_bn']))
return model
def vgg13(pretrained=False, **kwargs):
"""
VGG 13-layer model (configuration "B")
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
if pretrained:
kwargs['init_weights'] = False
model = VGG(make_layers(cfg['B']), **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['vgg13']))
return model
def vgg13_bn(pretrained=False, **kwargs):
"""
VGG 13-layer model (configuration "B") with batch normalization
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
if pretrained:
kwargs['init_weights'] = False
model = VGG(make_layers(cfg['B'], batch_norm=True), **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['vgg13_bn']))
return model
def vgg16(pretrained=False, **kwargs):
"""
VGG 16-layer model (configuration "D")
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
if pretrained:
kwargs['init_weights'] = False
model = VGG(make_layers(cfg['D']), **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['vgg16']))
return model
def vgg16_bn(pretrained=False, **kwargs):
"""
VGG 16-layer model (configuration "D") with batch normalization
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
if pretrained:
kwargs['init_weights'] = False
model = VGG(make_layers(cfg['D'], batch_norm=True), **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['vgg16_bn']))
return model
def vgg19(pretrained=False, **kwargs):
"""
VGG 19-layer model (configuration "E")
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
if pretrained:
kwargs['init_weights'] = False
model = VGG(make_layers(cfg['E']), **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['vgg19']))
return model
def vgg19_bn(pretrained=False, **kwargs):
"""
VGG 19-layer model (configuration 'E') with batch normalization
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
if pretrained:
kwargs['init_weights'] = False
model = VGG(make_layers(cfg['E'], batch_norm=True), **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['vgg19_bn']))
return model2.3. ResNet
# resnet18
torchvision.models.resnet18(pretrained=False, **kwargs)
# resnet34
torchvision.models.resnet34(pretrained=False, **kwargs)
# resnet50
torchvision.models.resnet50(pretrained=False, **kwargs)
# resnet101
torchvision.models.resnet101(pretrained=False, **kwargs)
# resnet152
torchvision.models.resnet152(pretrained=False, **kwargs)网络结构定义 - ResNet:
# https://pytorch.org/docs/stable/_modules/torchvision/models/resnet.html
import torch.nn as nn
import math
import torch.utils.model_zoo as model_zoo
__all__ = ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101',
'resnet152']
model_urls = {
'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
}
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes,
kernel_size=3, stride=stride,
padding=1, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes,
kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def resnet18(pretrained=False, **kwargs):
"""
Constructs a ResNet-18 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(BasicBlock, [2, 2, 2, 2], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet18']))
return model
def resnet34(pretrained=False, **kwargs):
"""
Constructs a ResNet-34 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(BasicBlock, [3, 4, 6, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet34']))
return model
def resnet50(pretrained=False, **kwargs):
"""
Constructs a ResNet-50 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(Bottleneck, [3, 4, 6, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet50']))
return model
def resnet101(pretrained=False, **kwargs):
"""
Constructs a ResNet-101 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(Bottleneck, [3, 4, 23, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet101']))
return model
def resnet152(pretrained=False, **kwargs):
"""
Constructs a ResNet-152 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(Bottleneck, [3, 8, 36, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet152']))
return model2.4. SqueezeNet
squeezenet1_0:网络结构来自论文 SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size.
squeezenet1_1:网络结构来自于 official SqueezeNet repo.
squeezenet1_1 相比于 squeezenet1_0 计算量少了 2.4x 倍,参数量也稍微少了一些,但并未牺牲精度.
torchvision.models.squeezenet1_0(pretrained=False, **kwargs)
torchvision.models.squeezenet1_1(pretrained=False, **kwargs)网络结构定义 - SqueezeNet.
import math
import torch
import torch.nn as nn
import torch.nn.init as init
import torch.utils.model_zoo as model_zoo
__all__ = ['SqueezeNet', 'squeezenet1_0', 'squeezenet1_1']
model_urls = {
'squeezenet1_0': 'https://download.pytorch.org/models/squeezenet1_0-a815701f.pth',
'squeezenet1_1': 'https://download.pytorch.org/models/squeezenet1_1-f364aa15.pth',
}
class Fire(nn.Module):
def __init__(self, inplanes, squeeze_planes,
expand1x1_planes, expand3x3_planes):
super(Fire, self).__init__()
self.inplanes = inplanes
self.squeeze = nn.Conv2d(inplanes, squeeze_planes, kernel_size=1)
self.squeeze_activation = nn.ReLU(inplace=True)
self.expand1x1 = nn.Conv2d(squeeze_planes, expand1x1_planes,
kernel_size=1)
self.expand1x1_activation = nn.ReLU(inplace=True)
self.expand3x3 = nn.Conv2d(squeeze_planes, expand3x3_planes,
kernel_size=3, padding=1)
self.expand3x3_activation = nn.ReLU(inplace=True)
def forward(self, x):
x = self.squeeze_activation(self.squeeze(x))
return torch.cat([
self.expand1x1_activation(self.expand1x1(x)),
self.expand3x3_activation(self.expand3x3(x))
], 1)
class SqueezeNet(nn.Module):
def __init__(self, version=1.0, num_classes=1000):
super(SqueezeNet, self).__init__()
if version not in [1.0, 1.1]:
raise ValueError("Unsupported SqueezeNet version {version}:"
"1.0 or 1.1 expected".format(version=version))
self.num_classes = num_classes
if version == 1.0:
self.features = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=7, stride=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(96, 16, 64, 64),
Fire(128, 16, 64, 64),
Fire(128, 32, 128, 128),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(256, 32, 128, 128),
Fire(256, 48, 192, 192),
Fire(384, 48, 192, 192),
Fire(384, 64, 256, 256),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(512, 64, 256, 256),
)
else:
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(64, 16, 64, 64),
Fire(128, 16, 64, 64),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(128, 32, 128, 128),
Fire(256, 32, 128, 128),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(256, 48, 192, 192),
Fire(384, 48, 192, 192),
Fire(384, 64, 256, 256),
Fire(512, 64, 256, 256),
)
# Final convolution is initialized differently form the rest
final_conv = nn.Conv2d(512, self.num_classes, kernel_size=1)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
final_conv,
nn.ReLU(inplace=True),
nn.AvgPool2d(13, stride=1)
)
for m in self.modules():
if isinstance(m, nn.Conv2d):
if m is final_conv:
init.normal(m.weight.data, mean=0.0, std=0.01)
else:
init.kaiming_uniform(m.weight.data)
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x):
x = self.features(x)
x = self.classifier(x)
return x.view(x.size(0), self.num_classes)
def squeezenet1_0(pretrained=False, **kwargs):
"""
SqueezeNet model architecture
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = SqueezeNet(version=1.0, **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['squeezenet1_0']))
return model
def squeezenet1_1(pretrained=False, **kwargs):
"""
SqueezeNet 1.1 model
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = SqueezeNet(version=1.1, **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['squeezenet1_1']))
return model2.5. DenseNet
# densenet121
torchvision.models.densenet121(pretrained=False, **kwargs)
# densenet169
torchvision.models.densenet169(pretrained=False, **kwargs)
# densenet161
torchvision.models.densenet161(pretrained=False, **kwargs)
# densenet201
torchvision.models.densenet201(pretrained=False, **kwargs)网络结构定义 - DenseNet:
# https://pytorch.org/docs/stable/_modules/torchvision/models/densenet.html
import re
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.model_zoo as model_zoo
from collections import OrderedDict
__all__ = ['DenseNet', 'densenet121', 'densenet169', 'densenet201', 'densenet161']
model_urls = {
'densenet121': 'https://download.pytorch.org/models/densenet121-a639ec97.pth',
'densenet169': 'https://download.pytorch.org/models/densenet169-b2777c0a.pth',
'densenet201': 'https://download.pytorch.org/models/densenet201-c1103571.pth',
'densenet161': 'https://download.pytorch.org/models/densenet161-8d451a50.pth',
}
def densenet121(pretrained=False, **kwargs):
"""
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = DenseNet(num_init_features=64, growth_rate=32, block_config=(6, 12, 24, 16),
**kwargs)
if pretrained:
# '.'s are no longer allowed in module names, but pervious _DenseLayer
# has keys 'norm.1', 'relu.1', 'conv.1', 'norm.2', 'relu.2', 'conv.2'.
# They are also in the checkpoints in model_urls. This pattern is used
# to find such keys.
pattern = re.compile(
r'^(.*denselayer\d+\.(?:norm|relu|conv))\.((?:[12])\.(?:weight|bias|running_mean|running_var))$')
state_dict = model_zoo.load_url(model_urls['densenet121'])
for key in list(state_dict.keys()):
res = pattern.match(key)
if res:
new_key = res.group(1) + res.group(2)
state_dict[new_key] = state_dict[key]
del state_dict[key]
model.load_state_dict(state_dict)
return model
def densenet169(pretrained=False, **kwargs):
"""
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = DenseNet(num_init_features=64, growth_rate=32, block_config=(6, 12, 32, 32),
**kwargs)
if pretrained:
# '.'s are no longer allowed in module names, but pervious _DenseLayer
# has keys 'norm.1', 'relu.1', 'conv.1', 'norm.2', 'relu.2', 'conv.2'.
# They are also in the checkpoints in model_urls. This pattern is used
# to find such keys.
pattern = re.compile(
r'^(.*denselayer\d+\.(?:norm|relu|conv))\.((?:[12])\.(?:weight|bias|running_mean|running_var))$')
state_dict = model_zoo.load_url(model_urls['densenet169'])
for key in list(state_dict.keys()):
res = pattern.match(key)
if res:
new_key = res.group(1) + res.group(2)
state_dict[new_key] = state_dict[key]
del state_dict[key]
model.load_state_dict(state_dict)
return model
def densenet201(pretrained=False, **kwargs):
"""
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = DenseNet(num_init_features=64, growth_rate=32, block_config=(6, 12, 48, 32),
**kwargs)
if pretrained:
# '.'s are no longer allowed in module names, but pervious _DenseLayer
# has keys 'norm.1', 'relu.1', 'conv.1', 'norm.2', 'relu.2', 'conv.2'.
# They are also in the checkpoints in model_urls. This pattern is used
# to find such keys.
pattern = re.compile(
r'^(.*denselayer\d+\.(?:norm|relu|conv))\.((?:[12])\.(?:weight|bias|running_mean|running_var))$')
state_dict = model_zoo.load_url(model_urls['densenet201'])
for key in list(state_dict.keys()):
res = pattern.match(key)
if res:
new_key = res.group(1) + res.group(2)
state_dict[new_key] = state_dict[key]
del state_dict[key]
model.load_state_dict(state_dict)
return model
def densenet161(pretrained=False, **kwargs):
"""
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = DenseNet(num_init_features=96, growth_rate=48, block_config=(6, 12, 36, 24),
**kwargs)
if pretrained:
# '.'s are no longer allowed in module names, but pervious _DenseLayer
# has keys 'norm.1', 'relu.1', 'conv.1', 'norm.2', 'relu.2', 'conv.2'.
# They are also in the checkpoints in model_urls. This pattern is used
# to find such keys.
pattern = re.compile(
r'^(.*denselayer\d+\.(?:norm|relu|conv))\.((?:[12])\.(?:weight|bias|running_mean|running_var))$')
state_dict = model_zoo.load_url(model_urls['densenet161'])
for key in list(state_dict.keys()):
res = pattern.match(key)
if res:
new_key = res.group(1) + res.group(2)
state_dict[new_key] = state_dict[key]
del state_dict[key]
model.load_state_dict(state_dict)
return model
class _DenseLayer(nn.Sequential):
def __init__(self, num_input_features, growth_rate, bn_size, drop_rate):
super(_DenseLayer, self).__init__()
self.add_module('norm1', nn.BatchNorm2d(num_input_features)),
self.add_module('relu1', nn.ReLU(inplace=True)),
self.add_module('conv1', nn.Conv2d(num_input_features, bn_size *
growth_rate, kernel_size=1, stride=1, bias=False)),
self.add_module('norm2', nn.BatchNorm2d(bn_size * growth_rate)),
self.add_module('relu2', nn.ReLU(inplace=True)),
self.add_module('conv2', nn.Conv2d(bn_size * growth_rate, growth_rate,
kernel_size=3, stride=1, padding=1, bias=False)),
self.drop_rate = drop_rate
def forward(self, x):
new_features = super(_DenseLayer, self).forward(x)
if self.drop_rate > 0:
new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)
return torch.cat([x, new_features], 1)
class _DenseBlock(nn.Sequential):
def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate):
super(_DenseBlock, self).__init__()
for i in range(num_layers):
layer = _DenseLayer(num_input_features + i * growth_rate, growth_rate, bn_size, drop_rate)
self.add_module('denselayer%d' % (i + 1), layer)
class _Transition(nn.Sequential):
def __init__(self, num_input_features, num_output_features):
super(_Transition, self).__init__()
self.add_module('norm', nn.BatchNorm2d(num_input_features))
self.add_module('relu', nn.ReLU(inplace=True))
self.add_module('conv', nn.Conv2d(num_input_features, num_output_features,
kernel_size=1, stride=1, bias=False))
self.add_module('pool', nn.AvgPool2d(kernel_size=2, stride=2))
class DenseNet(nn.Module):
"""
Densenet-BC model class.
Args:
growth_rate (int) - how many filters to add each layer (`k` in paper)
block_config (list of 4 ints) - how many layers in each pooling block
num_init_features (int) - the number of filters to learn in the first convolution layer
bn_size (int) - multiplicative factor for number of bottle neck layers
(i.e. bn_size * k features in the bottleneck layer)
drop_rate (float) - dropout rate after each dense layer
num_classes (int) - number of classification classes
"""
def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16),
num_init_features=64, bn_size=4, drop_rate=0, num_classes=1000):
super(DenseNet, self).__init__()
# First convolution
self.features = nn.Sequential(OrderedDict([
('conv0', nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)),
('norm0', nn.BatchNorm2d(num_init_features)),
('relu0', nn.ReLU(inplace=True)),
('pool0', nn.MaxPool2d(kernel_size=3, stride=2, padding=1)),
]))
# Each denseblock
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = _DenseBlock(num_layers=num_layers, num_input_features=num_features,
bn_size=bn_size, growth_rate=growth_rate, drop_rate=drop_rate)
self.features.add_module('denseblock%d' % (i + 1), block)
num_features = num_features + num_layers * growth_rate
if i != len(block_config) - 1:
trans = _Transition(num_input_features=num_features, num_output_features=num_features // 2)
self.features.add_module('transition%d' % (i + 1), trans)
num_features = num_features // 2
# Final batch norm
self.features.add_module('norm5', nn.BatchNorm2d(num_features))
# Linear layer
self.classifier = nn.Linear(num_features, num_classes)
# Official init from torch repo.
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal(m.weight.data)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.bias.data.zero_()
def forward(self, x):
features = self.features(x)
out = F.relu(features, inplace=True)
out = F.avg_pool2d(out, kernel_size=7, stride=1).view(features.size(0), -1)
out = self.classifier(out)
return out2.6. Inception V3
Paper - Rethinking the Inception Architecture for Computer Vision - 2015
torchvision.models.inception_v3(pretrained=False, **kwargs)网络结构定义 - Inception V3:
# https://pytorch.org/docs/stable/_modules/torchvision/models/inception.html#inception_v3
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.model_zoo as model_zoo
__all__ = ['Inception3', 'inception_v3']
model_urls = {
# Inception v3 ported from TensorFlow
'inception_v3_google': 'https://download.pytorch.org/models/inception_v3_google-1a9a5a14.pth',
}
def inception_v3(pretrained=False, **kwargs):
"""
Inception v3 model architecture.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
if pretrained:
if 'transform_input' not in kwargs:
kwargs['transform_input'] = True
model = Inception3(**kwargs)
model.load_state_dict(model_zoo.load_url(model_urls['inception_v3_google']))
return model
return Inception3(**kwargs)
class Inception3(nn.Module):
def __init__(self, num_classes=1000, aux_logits=True, transform_input=False):
super(Inception3, self).__init__()
self.aux_logits = aux_logits
self.transform_input = transform_input
self.Conv2d_1a_3x3 = BasicConv2d(3, 32, kernel_size=3, stride=2)
self.Conv2d_2a_3x3 = BasicConv2d(32, 32, kernel_size=3)
self.Conv2d_2b_3x3 = BasicConv2d(32, 64, kernel_size=3, padding=1)
self.Conv2d_3b_1x1 = BasicConv2d(64, 80, kernel_size=1)
self.Conv2d_4a_3x3 = BasicConv2d(80, 192, kernel_size=3)
self.Mixed_5b = InceptionA(192, pool_features=32)
self.Mixed_5c = InceptionA(256, pool_features=64)
self.Mixed_5d = InceptionA(288, pool_features=64)
self.Mixed_6a = InceptionB(288)
self.Mixed_6b = InceptionC(768, channels_7x7=128)
self.Mixed_6c = InceptionC(768, channels_7x7=160)
self.Mixed_6d = InceptionC(768, channels_7x7=160)
self.Mixed_6e = InceptionC(768, channels_7x7=192)
if aux_logits:
self.AuxLogits = InceptionAux(768, num_classes)
self.Mixed_7a = InceptionD(768)
self.Mixed_7b = InceptionE(1280)
self.Mixed_7c = InceptionE(2048)
self.fc = nn.Linear(2048, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear):
import scipy.stats as stats
stddev = m.stddev if hasattr(m, 'stddev') else 0.1
X = stats.truncnorm(-2, 2, scale=stddev)
values = torch.Tensor(X.rvs(m.weight.data.numel()))
values = values.view(m.weight.data.size())
m.weight.data.copy_(values)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def forward(self, x):
if self.transform_input:
x = x.clone()
x[:, 0] = x[:, 0] * (0.229 / 0.5) + (0.485 - 0.5) / 0.5
x[:, 1] = x[:, 1] * (0.224 / 0.5) + (0.456 - 0.5) / 0.5
x[:, 2] = x[:, 2] * (0.225 / 0.5) + (0.406 - 0.5) / 0.5
# 299 x 299 x 3
x = self.Conv2d_1a_3x3(x)
# 149 x 149 x 32
x = self.Conv2d_2a_3x3(x)
# 147 x 147 x 32
x = self.Conv2d_2b_3x3(x)
# 147 x 147 x 64
x = F.max_pool2d(x, kernel_size=3, stride=2)
# 73 x 73 x 64
x = self.Conv2d_3b_1x1(x)
# 73 x 73 x 80
x = self.Conv2d_4a_3x3(x)
# 71 x 71 x 192
x = F.max_pool2d(x, kernel_size=3, stride=2)
# 35 x 35 x 192
x = self.Mixed_5b(x)
# 35 x 35 x 256
x = self.Mixed_5c(x)
# 35 x 35 x 288
x = self.Mixed_5d(x)
# 35 x 35 x 288
x = self.Mixed_6a(x)
# 17 x 17 x 768
x = self.Mixed_6b(x)
# 17 x 17 x 768
x = self.Mixed_6c(x)
# 17 x 17 x 768
x = self.Mixed_6d(x)
# 17 x 17 x 768
x = self.Mixed_6e(x)
# 17 x 17 x 768
if self.training and self.aux_logits:
aux = self.AuxLogits(x)
# 17 x 17 x 768
x = self.Mixed_7a(x)
# 8 x 8 x 1280
x = self.Mixed_7b(x)
# 8 x 8 x 2048
x = self.Mixed_7c(x)
# 8 x 8 x 2048
x = F.avg_pool2d(x, kernel_size=8)
# 1 x 1 x 2048
x = F.dropout(x, training=self.training)
# 1 x 1 x 2048
x = x.view(x.size(0), -1)
# 2048
x = self.fc(x)
# 1000 (num_classes)
if self.training and self.aux_logits:
return x, aux
return x
class InceptionA(nn.Module):
def __init__(self, in_channels, pool_features):
super(InceptionA, self).__init__()
self.branch1x1 = BasicConv2d(in_channels, 64, kernel_size=1)
self.branch5x5_1 = BasicConv2d(in_channels, 48, kernel_size=1)
self.branch5x5_2 = BasicConv2d(48, 64, kernel_size=5, padding=2)
self.branch3x3dbl_1 = BasicConv2d(in_channels, 64, kernel_size=1)
self.branch3x3dbl_2 = BasicConv2d(64, 96, kernel_size=3, padding=1)
self.branch3x3dbl_3 = BasicConv2d(96, 96, kernel_size=3, padding=1)
self.branch_pool = BasicConv2d(in_channels, pool_features, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch5x5, branch3x3dbl, branch_pool]
return torch.cat(outputs, 1)
class InceptionB(nn.Module):
def __init__(self, in_channels):
super(InceptionB, self).__init__()
self.branch3x3 = BasicConv2d(in_channels, 384, kernel_size=3, stride=2)
self.branch3x3dbl_1 = BasicConv2d(in_channels, 64, kernel_size=1)
self.branch3x3dbl_2 = BasicConv2d(64, 96, kernel_size=3, padding=1)
self.branch3x3dbl_3 = BasicConv2d(96, 96, kernel_size=3, stride=2)
def forward(self, x):
branch3x3 = self.branch3x3(x)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)
branch_pool = F.max_pool2d(x, kernel_size=3, stride=2)
outputs = [branch3x3, branch3x3dbl, branch_pool]
return torch.cat(outputs, 1)
class InceptionC(nn.Module):
def __init__(self, in_channels, channels_7x7):
super(InceptionC, self).__init__()
self.branch1x1 = BasicConv2d(in_channels, 192, kernel_size=1)
c7 = channels_7x7
self.branch7x7_1 = BasicConv2d(in_channels, c7, kernel_size=1)
self.branch7x7_2 = BasicConv2d(c7, c7, kernel_size=(1, 7), padding=(0, 3))
self.branch7x7_3 = BasicConv2d(c7, 192, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_1 = BasicConv2d(in_channels, c7, kernel_size=1)
self.branch7x7dbl_2 = BasicConv2d(c7, c7, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_3 = BasicConv2d(c7, c7, kernel_size=(1, 7), padding=(0, 3))
self.branch7x7dbl_4 = BasicConv2d(c7, c7, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_5 = BasicConv2d(c7, 192, kernel_size=(1, 7), padding=(0, 3))
self.branch_pool = BasicConv2d(in_channels, 192, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch7x7 = self.branch7x7_1(x)
branch7x7 = self.branch7x7_2(branch7x7)
branch7x7 = self.branch7x7_3(branch7x7)
branch7x7dbl = self.branch7x7dbl_1(x)
branch7x7dbl = self.branch7x7dbl_2(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_3(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_4(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_5(branch7x7dbl)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch7x7, branch7x7dbl, branch_pool]
return torch.cat(outputs, 1)
class InceptionD(nn.Module):
def __init__(self, in_channels):
super(InceptionD, self).__init__()
self.branch3x3_1 = BasicConv2d(in_channels, 192, kernel_size=1)
self.branch3x3_2 = BasicConv2d(192, 320, kernel_size=3, stride=2)
self.branch7x7x3_1 = BasicConv2d(in_channels, 192, kernel_size=1)
self.branch7x7x3_2 = BasicConv2d(192, 192, kernel_size=(1, 7), padding=(0, 3))
self.branch7x7x3_3 = BasicConv2d(192, 192, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7x3_4 = BasicConv2d(192, 192, kernel_size=3, stride=2)
def forward(self, x):
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch7x7x3 = self.branch7x7x3_1(x)
branch7x7x3 = self.branch7x7x3_2(branch7x7x3)
branch7x7x3 = self.branch7x7x3_3(branch7x7x3)
branch7x7x3 = self.branch7x7x3_4(branch7x7x3)
branch_pool = F.max_pool2d(x, kernel_size=3, stride=2)
outputs = [branch3x3, branch7x7x3, branch_pool]
return torch.cat(outputs, 1)
class InceptionE(nn.Module):
def __init__(self, in_channels):
super(InceptionE, self).__init__()
self.branch1x1 = BasicConv2d(in_channels, 320, kernel_size=1)
self.branch3x3_1 = BasicConv2d(in_channels, 384, kernel_size=1)
self.branch3x3_2a = BasicConv2d(384, 384, kernel_size=(1, 3), padding=(0, 1))
self.branch3x3_2b = BasicConv2d(384, 384, kernel_size=(3, 1), padding=(1, 0))
self.branch3x3dbl_1 = BasicConv2d(in_channels, 448, kernel_size=1)
self.branch3x3dbl_2 = BasicConv2d(448, 384, kernel_size=3, padding=1)
self.branch3x3dbl_3a = BasicConv2d(384, 384, kernel_size=(1, 3), padding=(0, 1))
self.branch3x3dbl_3b = BasicConv2d(384, 384, kernel_size=(3, 1), padding=(1, 0))
self.branch_pool = BasicConv2d(in_channels, 192, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch3x3 = self.branch3x3_1(x)
branch3x3 = [
self.branch3x3_2a(branch3x3),
self.branch3x3_2b(branch3x3),
]
branch3x3 = torch.cat(branch3x3, 1)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = [
self.branch3x3dbl_3a(branch3x3dbl),
self.branch3x3dbl_3b(branch3x3dbl),
]
branch3x3dbl = torch.cat(branch3x3dbl, 1)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch3x3, branch3x3dbl, branch_pool]
return torch.cat(outputs, 1)
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.conv0 = BasicConv2d(in_channels, 128, kernel_size=1)
self.conv1 = BasicConv2d(128, 768, kernel_size=5)
self.conv1.stddev = 0.01
self.fc = nn.Linear(768, num_classes)
self.fc.stddev = 0.001
def forward(self, x):
# 17 x 17 x 768
x = F.avg_pool2d(x, kernel_size=5, stride=3)
# 5 x 5 x 768
x = self.conv0(x)
# 5 x 5 x 128
x = self.conv1(x)
# 1 x 1 x 768
x = x.view(x.size(0), -1)
# 768
x = self.fc(x)
# 1000
return x
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return F.relu(x, inplace=True)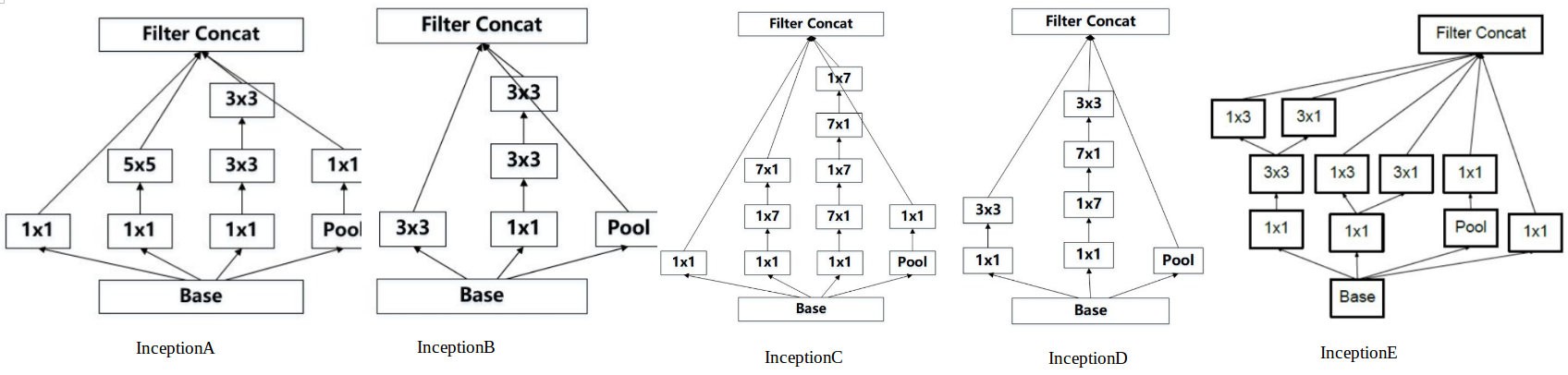
One comment
很实用,持续关注