原文: Why
tf.datais much better thanfeed_dictand how to build a simple data pipeline in 5 minutes.
1. feed_dict 和 tf.data 对比
Tensorflow 入门手册中一般介绍的是采用 feed_dict方法,在tf.Seession.run() 会话运行或 tf.Tensor.eval() 函数调用时,将数据加载进模型. 然而,还有另一种更加有效和更简单的方式,即,采用 tf.data API,只需几行代码即可实现高效的数据管道(pipelines).
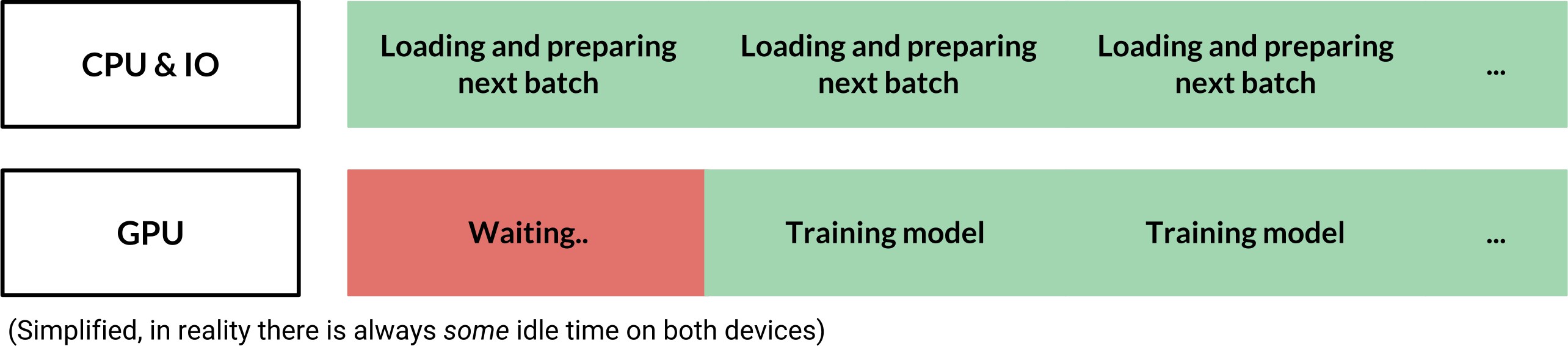
在 feed_dict 管道中,GPU 存在等待时间,需要等 CPU 提供下一个 batch 的数据. 如图:

而在 tf.data 管道中,可以异步地拉取下一个 batches 的数据,以最小化闲置时间. 而且,还可以通过并行化数据加载和预处理操作,以进一步加速数据管道.
2. 图像数据管道简单构建
数据管道构建需要两个对象:
tf.data.Dataset- 保存数据;tf.data.Iterator- 用于从数据集中逐个提取数据样本.
图像数据管道的 tf.data.Dataset 类似于:
[
[Tensor(image), Tensor(label)],
[Tensor(image), Tensor(label)],
...
]然后,采用 tf.data.Iterator 逐个检索 image-label 图像标签对. 实际应用中,多个图像标签对会进行 batch 组合在一起,以便于迭代器一次性读取整个 batch.
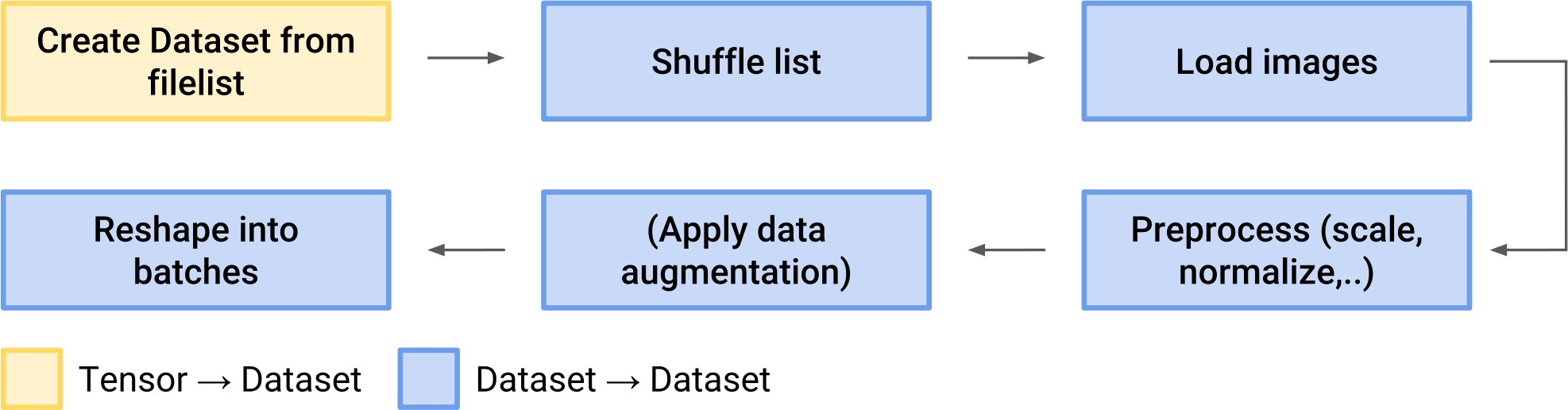
数据集的创建可以是从数据源(如,文件名列表)或对已有数据集的数据变换. 如,
Dataset(图片文件列表) →Dataset(真实图像数据)Dataset(6400 images) →Dataset(64 batches with 100 images each)Dataset(音频文件列表) →Dataset(打乱的音频文件列表)
3. 定义计算图
图像数据管道类似于:

下面的代码,用于数据集管道,其与 model,loss,optimizer,等,一起放置于计算图的定义中.
# 定义文件列表
files = ['a.png', 'b.png', 'c.png', 'd.png']
# 从文件名创建数据集
dataset = tf.data.Dataset.from_tensor_slices(files)
# 定义从路径加载图像的函数(作为张量).
# 并采用 tf.data.Dataset.map() 函数,用于数据集中的所有文件(文件路径).
# 还可以采用 map() 的 num_parallel_calls=n 参数,以并行化函数调用.
def load_image(path):
image_string = tf.read_file(path)
# Don't use tf.image.decode_image, or the output shape will be undefined
image = tf.image.decode_jpeg(image_string, channels=3)
# This will convert to float values in [0, 1]
image = tf.image.convert_image_dtype(image, tf.float32)
image = tf.image.resize_images(image, [image_size, image_size])
return image
# Apply the function load_image to each filename in the dataset
dataset = dataset.map(load_image, num_parallel_calls=8)
# 采用 tf.data.Dataset.batch() 创建 batches 数据.
# Create batches of 64 images each
dataset = dataset.batch(64)此外,还可以在数据管道的后面添加:
tf.data.Dataset.prefetch(buffer_size)该代码可以保证下一个 batch 的数据对于 GPU 可以立即可用,减少 GPU 的数据等待时间. 其中,buffer_size 是预先被拉取数据的 batches 数. 一般情况下,buffer_size=1. 如果处理每个 batch 的耗时不同时,可以增加其值.
dataset = dataset.prefetch(buffer_size=1)最后,创建迭代器(iterator),以迭代的读取数据集. 迭代器有不同的类型,一般情况下,推荐采用初始化的迭代器:
iterator = dataset.make_initializable_iterator()此后,即可调用 tf.data.Iterator.get_netx() 函数创建占位符张量(placeholder-tensor),每次 eval 时,TensorFlow 都会填充下一个 batch 的图像数据.
batch_of_images = iterator.get_next()如果转换为 feed_dict数据管道,则 batch_of_image 会取代原先的占位符变量.
4. 运行会话
创建好数据管道后,即可运行模型. 但,需要确保在每个 epoch 前检查 iteror.initializer op,并在每个 epoch 后捕捉 tf.error.OutOfRangeError 异常.
with tf.Session() as session:
for i in range(epochs):
session.run(iterator.initializer)
try:
# Go through the entire dataset
while True:
image_batch = session.run(batch_of_images)
except tf.errors.OutOfRangeError:
print('End of Epoch.')
nvidia-smi命令用于监视 GPU 的利用率使用情况,有助于理解数据管道的瓶颈. 平均 GPU 利用率应该多大于 70-80%.
5. 数据管道构建的复杂版本
5.1 Shuffle
采用 tf.data.Dataset.shuffle() 打乱文件名. 参数指定了一次性被打乱的样本数. 通常情况,推荐一次性打乱整个文件名列表.
参考:Meaning of buffer_size in Dataset.map , Dataset.prefetch and Dataset.shuffle - Stackoverflow
dataset = tf.data.Dataset.from_tensor_slices(files)
dataset = dataset.shuffle(len(files))5.2 Data Augmentation
采用 tf.image.random_flip_left_right(), tf.image.random_brightness(), tf.image.random_saturation() 等,对图像进行简单的数据增强.
def train_preprocess(image):
image = tf.image.random_flip_left_right(image)
image = tf.image.random_brightness(image, max_delta=32.0 / 255.0)
image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
# Make sure the image is still in [0, 1]
image = tf.clip_by_value(image, 0.0, 1.0)
return image5.3 Labels
为了在加载图像数据集时,同时加载 labels (或其它元数据metadata),只需在创建初始数据集时,包含在内:
# files is a python list of image filenames
# labels is a numpy array with label data for each image
dataset = tf.data.Dataset.from_tensor_slices((files, labels))确保应用于数据集的所有 .map() 函数,都允许 label 数据的传递:
def load_image(path, label):
# load image
return image, label
dataset = dataset.map(load_image)6. Related
[1] - Google Slides presentation by one of the developers of tf.data
[2] - Stanford CS230 - Article about tf.data
[3] - tensorflow.org - Importing Data