原文:Semantic Segmentation with Deep Learning: A guide and code

语义分割
语义分割问题描述
深度学习和计算机视觉社区中,
图像分类理解为:让模型说出图片中存在的单个目标对象或者场景. 图像分类是很粗糙和 high-level 的.
目标检测 是定位图片中物体的位置,并给出物体的类别,即用边界框 boxes 来标注图片中的目标物体,并对边界框内的物体进行分类. 目标检测是 mid-level 的,能够获取很多有用的和更细节的信息,但仍是粗糙的,因为只是标注出物体的边界框boxes,并未给出物体真实形状.
语义分割 是更信息丰富的,其需要对图片的每个像素进行分类,给出了更细致的图片理解.
这里对语义分割的基础结果和已有成果进行概述.
基于 TensorFlow 的不同网络模型的训练和测试代码:
Github - GeorgeSeif/Semantic-Segmentation-Suite
语义分割基础结构
语义分割的基础结构是很多网络都有涉及到的,因为大部分都具有相同的 backbone 网络,模型设置,和工作流(flow),很便于不同网络模型的实现.
U-Net 是语义分割基础网络的很好的例示.
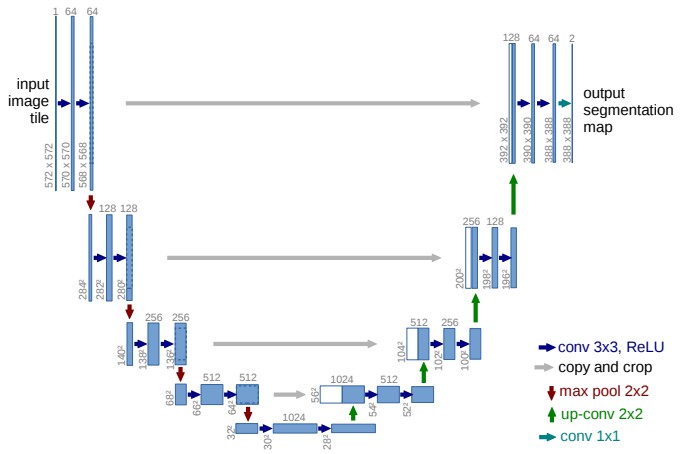
U-Net 的左半部分是任何用于训练图片分类的特征提取网络,如 VGGNet,ResNets,DenseNets,MobileNets,NASNets 等. 可以根据需要自定选取.
选取特征提取网络时最重要的是精度和速度的权衡tradeoffs,深层的 ResNet152 可以得到较高的精度,但运行效率比不过 MobileNets. 类似于图像分类中所采用网络的精度和速度的权衡.
需要强调的是,在设计/选择语义分割网络时,backbones 网络是最重要的因素.
特征提取后,再在不同尺度进行进一步的处理. 其原因主要包括两层:
- [1] - 因为模型会遇到很多不同尺寸的目标物体;在不同尺度的进一步处理特征,使得网络对于不同尺寸的目标物体的效果更鲁棒.
- [2] - 语义分割时需要考虑精度和效率的均衡. 如果需要更高的分类精度,则需要进一步应用到后面网络得到的高层(high level) 特征,因为这些特征更具判别力,且包含了更多有用的语义信息. 另一方面,如果只采用前面提取的深度特征,由于得到的特征图分辨率比较低,导致定位效果不够好.
最新的语义分割方法都遵循特征提取后接多尺度处理的网络结构. 很多都比较易于实现和 end-to-end 的训练.
具体分割方法根据应用场景的精度和速度/内存等来选择.
语义分割网络模型
1. 全分辨率残差网络 FRRN
Full-Resolution Residual Networks(FRRN) 是一种非常清晰的多尺度处理的模型,其包括两个工作流(streams):residual stream 和 pooling stream.
为了进一步处理提取的语义特征,以追求更高的分类精度,FRRN 在 pooling stream 逐步处理和下采样特征图(feature maps). 同时,在 residual stream 以全分辨率的处理特征图. 因此,pooling stream 处理高层(high-level) 语义信息,以得到较高的分类精度;residual stream 处理低层(low-level) 像素信息,以得到较高的定位精度.
为了实现 end-to-end 的网络训练,不希望将 pooling stream 和 residual stream 完全分离. 故,在每个 max pooling 后, FRRN 将 2 个 streams 的特征图进行联合处理,以组合二者的特征信息.
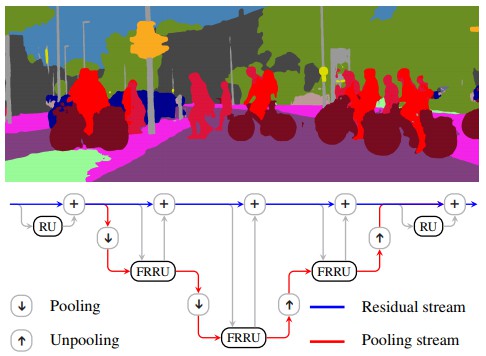
FRRN 模型结构
2. 金字塔场景解析网络(PSPNet)
FRRN 很好的实现了直接进行多尺度处理. 但是,在每个尺度的处理计算量比较大,计算密集. 而且,FRRN 会以全分辨率进行处理,其非常的慢.
Pyramid Scene Parsing Network (PSPNet) 提出一种聪明的方式来实现多尺度处理 - 采用 pooling 的多尺度(multiple scales of pooling).
PSPNet 利用了标准的特征提取网络,如 ResNet, DenseNet 等,并对提取的特征进一步处理.
为了得到多尺度信息,PSPNet 采用了 4 种不同窗口尺寸(window sizes)和步长(stride)的 max pooling操作,有效的实现了从 4 个不同尺度捕捉特征信息,而无需对每个尺寸进行大量计算.
然后,对每个尺寸采用一个小型卷积,上采样每个尺寸输出的特征图到相同分辨率,并链接,即可组合多尺度的特征图,不需要太多的卷积操作. 对于低分辨率的特征图,具有较高的计算效率.
最后,采用双线性上采样(bilinear intepolation)将输出的分割图调整到目标尺寸.
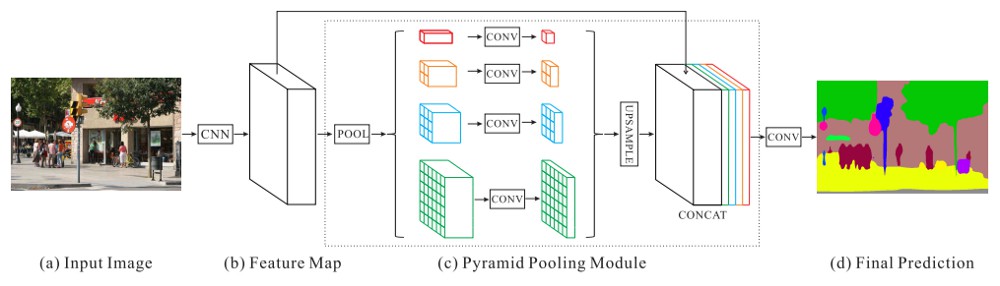
PSPNet 模型结构
3. 一百层的 Triamisu (FCDenseNet)
Hundred Layers Tiramisu FCDenseNet 采用了类似于 U-Net 结构的网络结构,其主要贡献在于,结合了类似于 DenseNet 分类模型的密集连接.
这也强调了 CV 领域的强烈趋势,特征提取前端是在任何其他任务上表现良好的主要支撑. 因此,分割精度的提升通常首先关注的是特征提取网络.
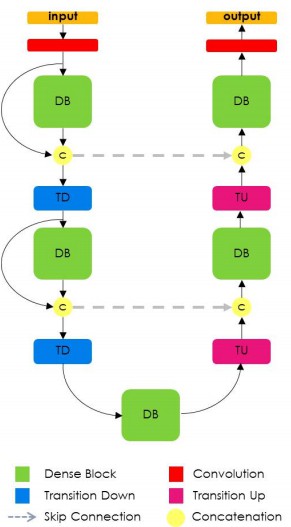
FCDenseNet 模型结构
4. DeepLabV3
DeepLabV3 采用另一种方式进行多尺度处理,但未增加网络参数.
DeepLabV3 模型非常轻型. 首先还是特征提取网络,采用第 4 个下采样层的输出特征以进行后续进一步处理.
输出的特征图分辨率非常低(输入图片的 1/16),由于较差的像素级精度,难以得到良好的定位效果.
DeepLabV3 的主要贡献是,Atrous 卷积的使用. 标准卷积只能处理非常局部的信息,例如,标准的 3x3 卷积,两个权重之间的距离仅是单个像素/像素(a single step / pixel).
基于 Atrous 卷积,可以直接增加不同卷积权重间的空间(距离),而且不会增加权重参数量.
仍是采用 3x3 的卷积,9 个参数,只需要乘以权重,即可扩大权重间的距离.
权重间的距离记为 dilation rate. 如 DeepLabV3 模型结构图中所示.
当 dilation rate 较小时,将处理非常局部、小尺度的特征信息.
当 dilation rate 较大时,则可处理更全局、大尺度的特征信息.
故,DeepLabV3 模型基于不同 dilation rates 的 atrous 卷积,来学习多尺度特征信息.

DeepLabV3 模型结构
5. 多路精细化分割网络(RefineNet)
FRRN 直接结合多种不同分辨率的特征信息,取得了很好的效果. 但其缺点是,高分辨率尺度特征图的处理,计算量比较大,而且仍要不得不处理和结合低分辨率的特征信息.
Multi-Path Refinement Networks (RefineNet) 模型则不需要如此.
当输入图片经过特征提取网络处理后,自然就可以在每一次下采样后得到多种尺度的特征信息.
RefineNet 然后采用 bottom-up 的方式处理得到的多种分辨率的特征图,以组合多尺度特征信息.
首先,分别处理每个特征图;然后将组合的低分辨率特征图处理到高分辨率的特征图,再对低分辨率特征图和高分辨率特征图一起处理. 这样,就可以对多尺度特征图分别独立处理和一起处理. 如图.
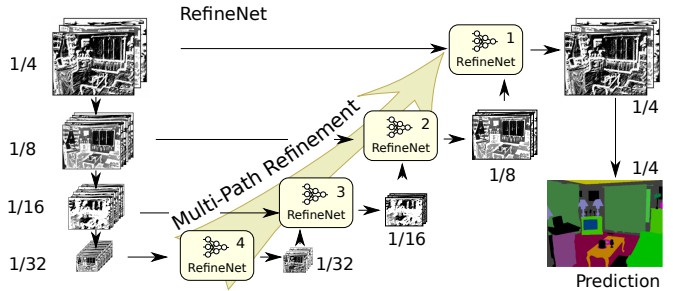
RefineNet 模型结构
6. Large Kernel Matters(GCN)
DeepLabV3 采用的是不同 dilation rates 的 atrous 卷积来学习多尺度信息,其只能一次处理一个尺度的特征,然后再组合多尺度的特征信息.
例如,dilation rate=16 的 atrous 卷积 对于局部信息的学习不够好,需要再组合一个更小的 dilation rate 的 atrous 卷积的特征信息,以取得更有的语义分割效果.
对此,在以前的语义分割方法中,多尺度处理一般是先分别单尺度处理,然后再组合各尺度处理后的结果. 如果能一次(one shot) 学习到多尺度信息,则更有意义.
Global Convolutional Network (GCN) 提出采用大的一维卷积核(large one-dimensional kernels),而不是方形卷积核.
基于方形卷积核,如3x3, 7x7 等,如果没有大规模的速度和内存消耗,难以变得太大.
而,一维卷积核(one dimensional kernels) 具有更高的效率,而且可以扩大卷积核而不减慢网络运行速度. 论文里甚至做到了 15.
最重要的是,水平卷积和垂直卷积的平衡. 论文里还使用了 low filter 的小的 3x3 卷积,以有效的精细化一维卷积可能导致的丢失信息.
GCN 也采用对特征提取网络的每个尺度的特征信息进行处理的方式.
基于一维卷积的高效率,GCN 对所有尺度进行处理,都是全分辨率的,而不是采用低分辨率,再转化到高分辨率的方式.
这样就可以按比例放大时,不断的精细化分割结果,而不用担心由于低分辨率而可能出现的 bottle-necking 问题.
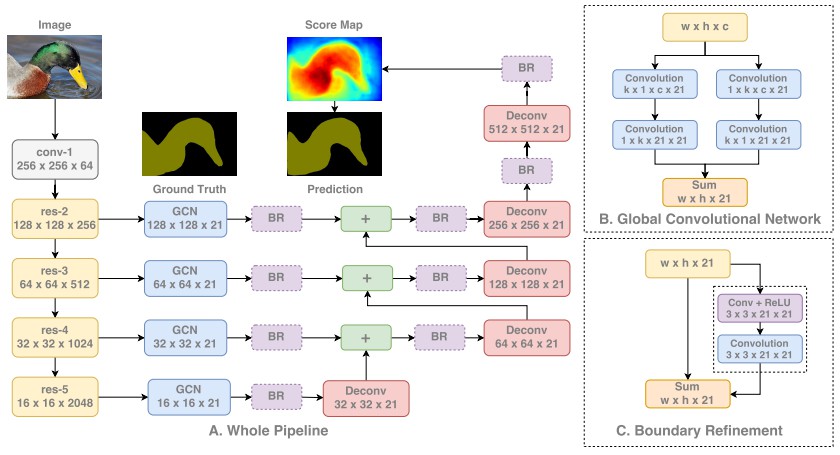
GCN 模型结构
7. DeepLabV3+
DeepLabV3+ 模型正如其名字,是DeepLabV3 的一个扩展,其借鉴了其它模型的思想.
从上面可知,如果只是简单的在网络尾部采用双线性上采样(bilinear interpolation),来得到分割输出,则存在潜在的瓶颈. 比如,原始的 DeepLabV3 模型实际上就是 x16 倍.
DeepLabV3+ 提出在 DeepLabV3 网络输出端添加一个解码模块. 在 DeepLabV3 处理后,对其输出的特征进行 x4 的上采样. 然后,将上采样后的特征与特征提取网络输出的特征相结合,进行进一步的处理,最后再进行 x4 的上采样.
这样就减轻了网络尾部的负载,并提供了从特征提取端到网络近端的 shortcut 连接.
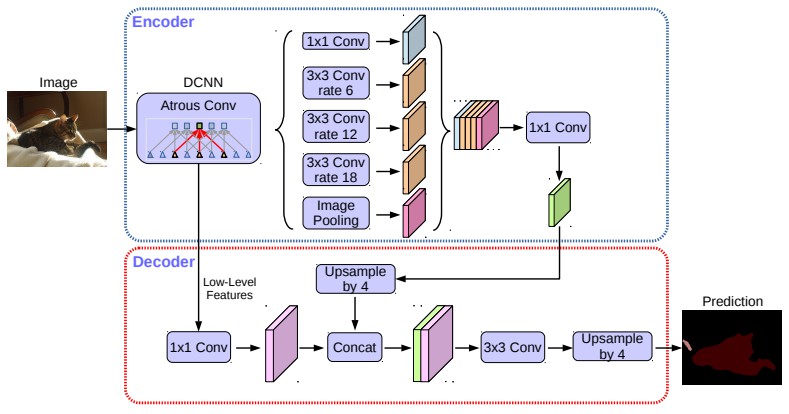
DeepLabV3+ 网络结构
CVPR 和 ECCV2018
- Image Cascade Network (ICNet) - 采用深度监督(deep suoervision),对输入图片在不同尺度进行处理,每个尺度都有各自的子网络,并逐步组合各尺度的输出结果.
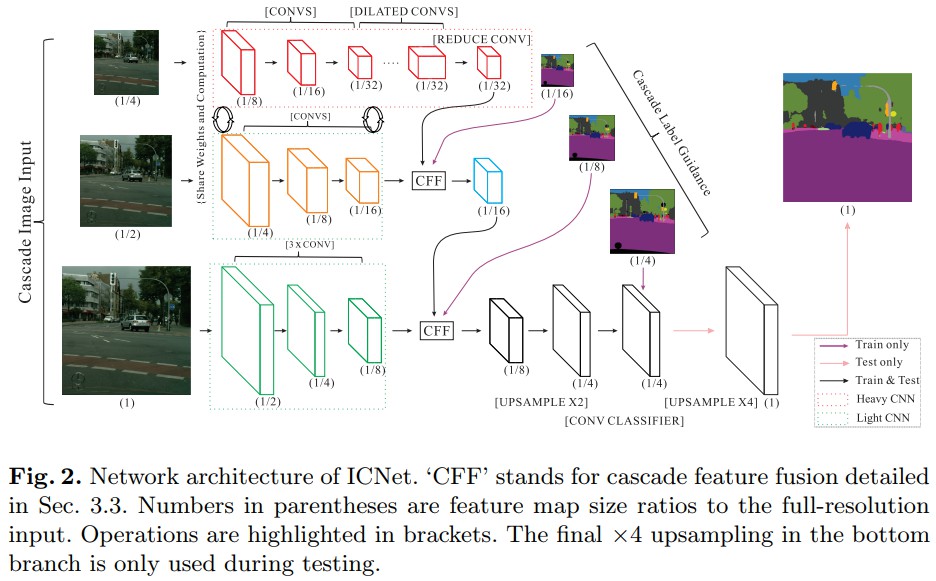
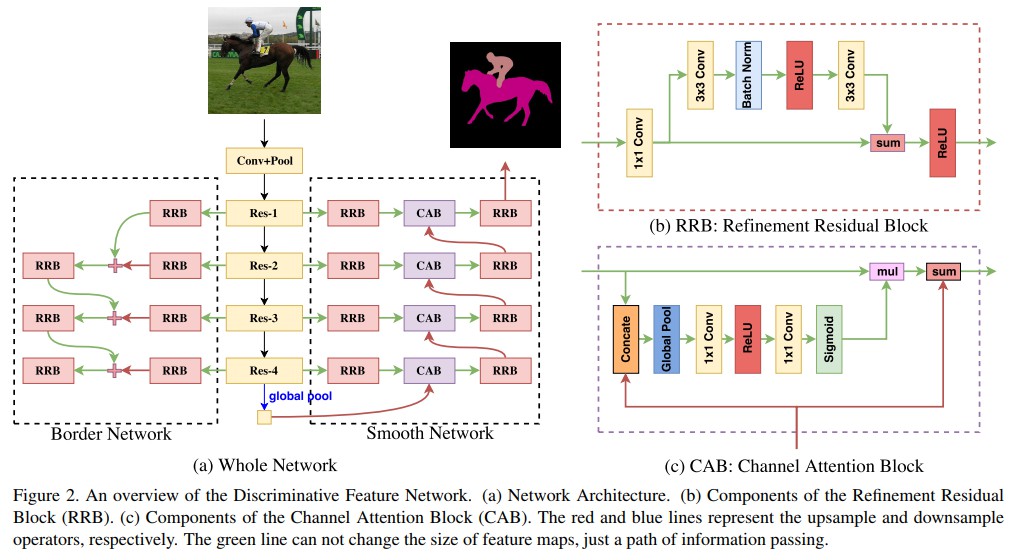
- Discriminative Feature Network (DFN) - 采用深度监督,尝试分别处理分割的平滑和边缘部分.
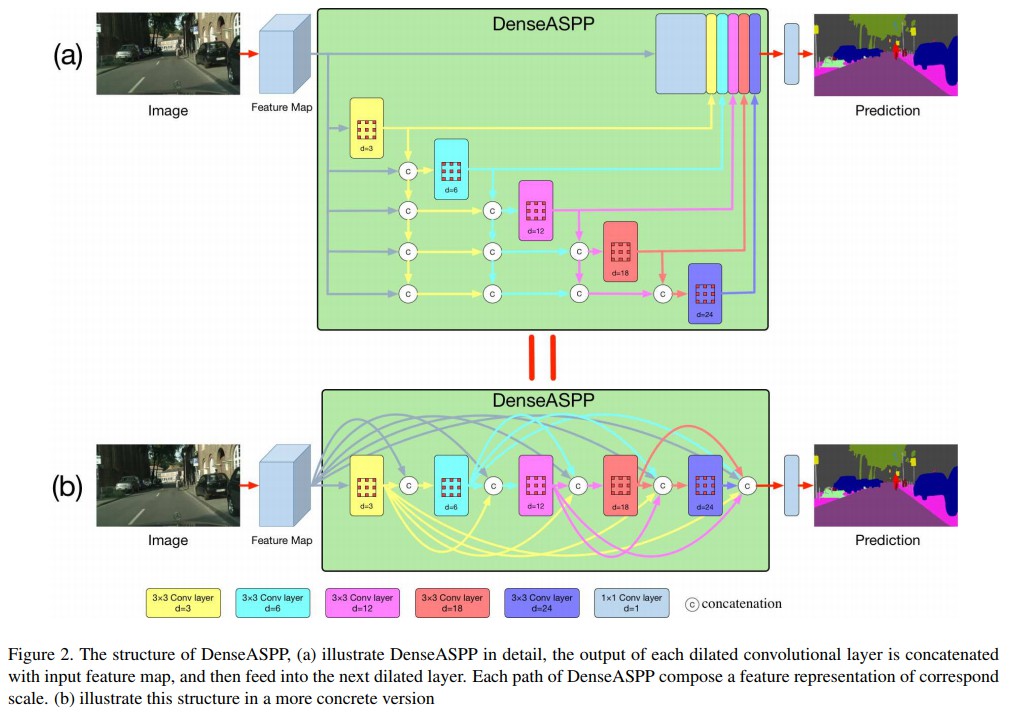
- DenseASPP - 结合密集连接(dense connection) 和 atrous 卷积.
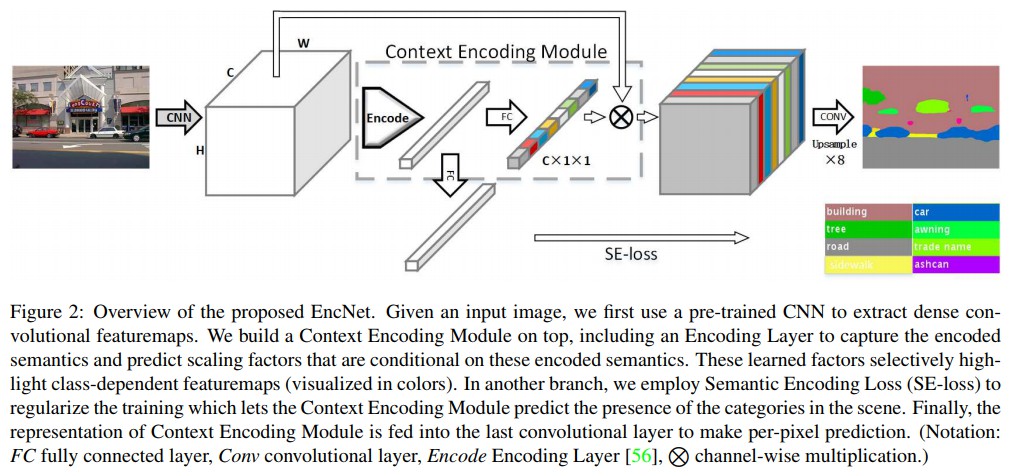
- Context Encoding - 新增一个 channel attention 模块,基于新设计的 loss 函数对特定的特征图触发 attention.
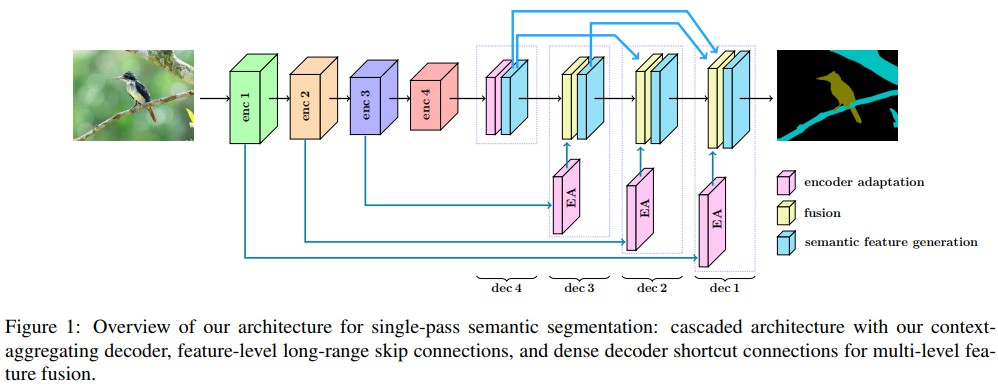
- Dense Decoder Shortcut Connections - 在解码decoding 阶段使用 dense connections,以得到更高的精度.(其它方法只是在特征提取/编码阶段使用)
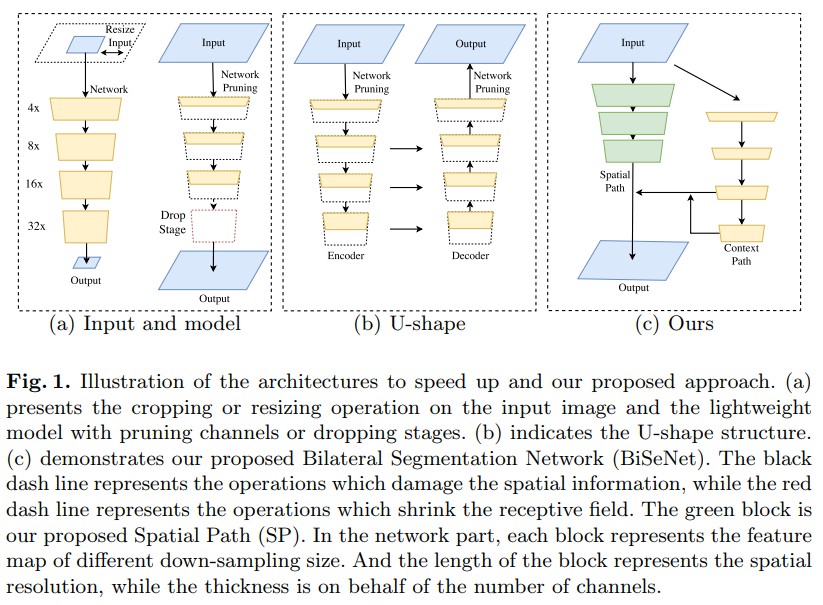
- Bilateral Segmentation Network (BiSeNet) - 网络有两个分支:一个用于学习语义信息,另一个用于对输入图片做非常少的处理 low-level 的像素信息.
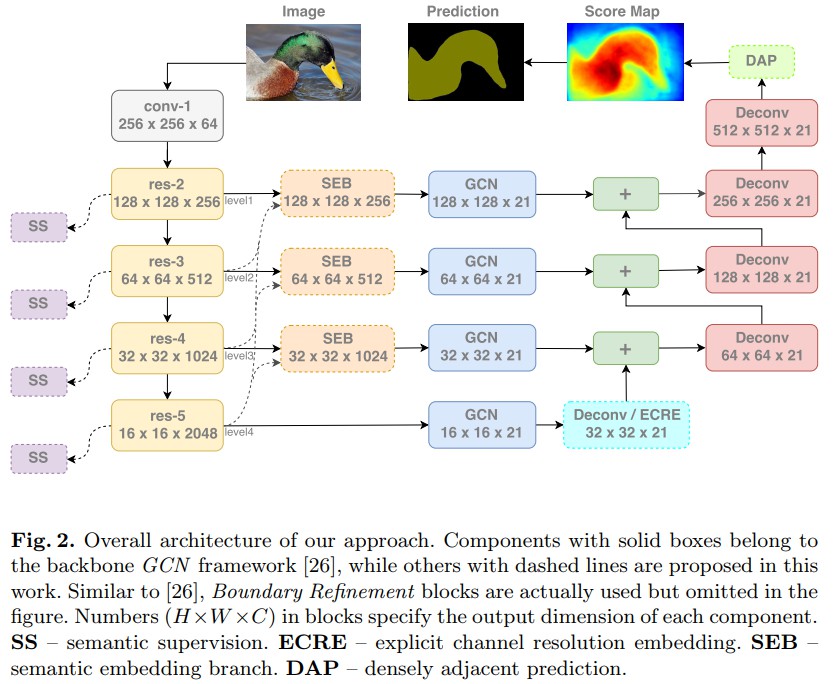
- ExFuse - 采用深度监督,组合特征提取网络输出的多尺度特征,确保在所有层次(levels) 都能够仪器处理多尺度信息.
如何做语义分割
- 熟练掌握分类网络. 因为分类网络是用于处理特征的主要驱动,特征信息主要源于此.
- 在多尺度处理,并组合多尺度信息.
- 多尺度的 pooling,atrous conv,large one-dimensional convs 有助于语义分割.
- 不需要在高分辨率做太多处理. 在低分辨率的处理速度较快,然后再转化到目标尺寸,以及必要的后处理.
- 深度监督有助于提升一点精度,但训练设置技巧性比较棘手.