原文:Train a Mask R-CNN model on your own data
计算机擅长于数字处理,但却困于对图像中的大规模数据分析. 随着图形处理单元库的创建,不仅有助于游戏应用场景,还能够利用其成千上万个核的原力来理解图片背后的含义.
自定义定制数据
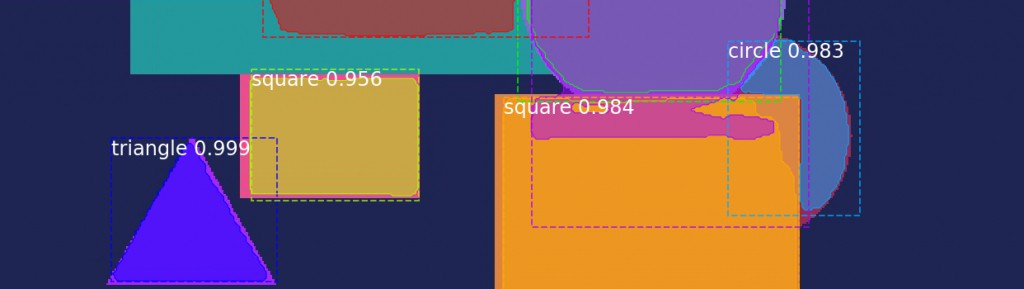
这里以 shape 数据集为例,其包含了随机颜色背景上的不同尺寸和颜色的圆形(circles),方形(squares) 和三角形(triangles) 实例. 假设已经将数据转化为 COCO-style 格式.
定制数据集转换为 COCO-style
现在关注于图像中所有形状的自动标注,像素级分割,即实例分割.
下面是 “目标识别”,“语义分割”,“目标检测” 和 “实例分割” 的例示对比.
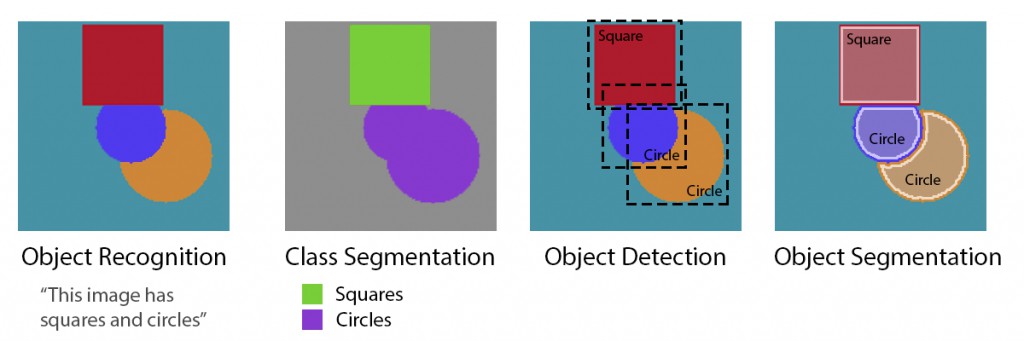
- 目标识别 - 识别图片中有什么,但不检测物体所在的位置和物体的多少.
- 语义分割 - 识别图片中的物体,并像素级的标注不同类型物体.
- 目标检测 - 识别图片中的物体,并采用边界框标注每个物体的位置.
- 实例分割 - 识别图片中的物体,并给出每个物体的像素级标注.
对于 shape 数据集,由于比较简单,采用传统机器视觉算法,如 Hough (pronounced Huff) circle and line 检测算法,或模板匹配算法,也可以得到不错的结果.
但,利用深度学习算法,不需要改变太多算法,即可扩展到同类型的任何图像数据集上. 而且,不用考虑特征提取.
MASK R-CNN 简介
神经网络由很多神经元链接,每个神经元根据输入信号和内部参数,产生对应的输出. 当训练神经网络时,调整神经元内部参数来生成目标输出.
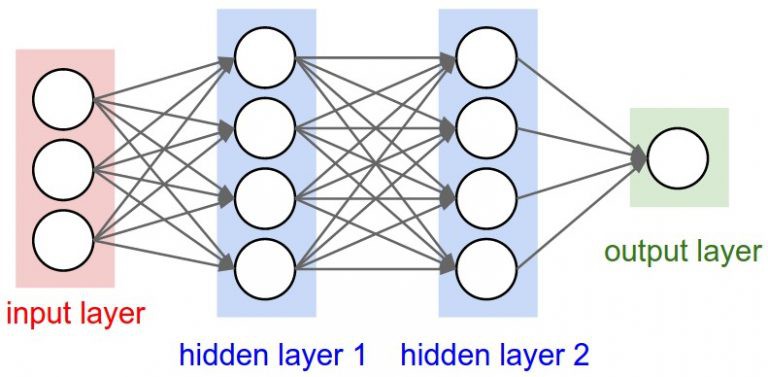
神经网络结构
MASK R-CNN 中的 "C" 是指卷积(convolutional).
CNNs 主要用于图像学习,其采用卷积核(filters)每次在图片的一小块区域进行卷积操作,而不是一次性的处理整张图片. 与一般神经网络相比,CNNs 参数和内存占用更少,更能适用于在较大图片上的计算.
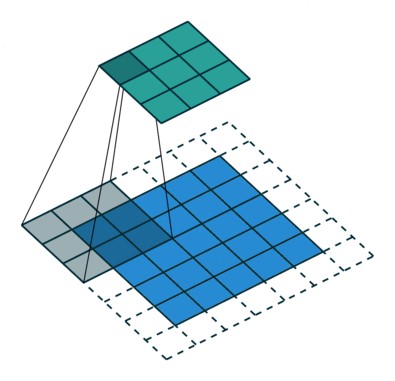
卷积操作
MASK R-CNN 中的 "R" 是指区域(region).
普通 CNNs 擅长于目标识别,但,如果是目标检测问题,则需要同时检测目标的位置. R-CNNs 会对找出的物体采用边界框进行标注. R-CNN 系列,如 Fast R-CNN,Faster R-CNN. Faster R-CNN 在 CNN 网络尾部添加了区域建议网络(Region Proposal Network),以用于建议物体区域(propose regions). 如果物体在这些区域内,则用作边界框(相当于前景目标检测).
MASK R-CNN 中的 "mask" 是添加了像素级语义分割.
MASK R-CNN 在 Faster R-CNN 网络后添加了新的分支,以生成二值 masks.
综上,对 MASK R-CNN 的不同分支进行了简介.
更多细节参考论文:
R-CNN
Fast R-CNN
Faster R-CNN
Mask R-CNN
准备
环境:Ubuntu16.04,GPU,CUDA,Docker.
采用 2GB 显存的 GeForce940M 可以训练一个小一点的网络. 但,最好是至少 11GB 的 NVIDIA 显卡.
或者采用云服务,Amazon Web Services 和 Google Cloud.
显卡驱动和 CUDA 安装:
# 显卡驱动
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt-get update
sudo apt-get install nvidia-graphics-drivers-390
# CUDA
wget https://developer.nvidia.com/compute/cuda/9.1/Prod/local_installers/cuda-repo-ubuntu1604-9-1-local_9.1.85-1_amd64
sudo dpkg -i cuda-repo-ubuntu1604-9-1-local_9.1.85-1_amd64.deb
sudo apt-key add /var/cuda-repo-<version>/7fa2af80.pub
sudo apt-get update
sudo apt-get install cuda-toolkit-9-1 cuda-libraries-dev-9-1 cuda-libraries-9-1
Docker,Docker-Compose,Nvidia-Docker2 安装:
# Docker
wget -O get_docker.sh get.docker.com
chmod +x get_docker.sh
sudo ./get_docker.sh
sudo apt-get install -y --allow-downgrades docker-ce=18.03.1~ce-0~ubuntu
sudo usermod -aG docker $USER
# Docker-Compose
sudo curl -L https://github.com/docker/compose/releases/download/1.21.0/docker-compose-$(uname -s)-$(uname -m) -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
# Nvidia-Docker2
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update
sudo apt-get install nvidia-docker2
sudo pkill -SIGHUP dockerd
MASK R-CNN 训练
下载 deep-learning-explorer.
其包含 mask-rcnn 和 data 文件夹.
data/shapes.zip 测试数据压缩包. 解压,并移动 annotations, shapes_train2018, shapes_test2018 和 shapes_validate2018 到 data/shapes 文件夹.
在 Ubuntu16.04 终端中,cd mask-rcnn/docker 进入文件夹 mask-rcnn/docker,然后运行 docker-compose up. 首次运行时,Docker 会从头开始构建系统,需要耗时几分钟. 之后,即可实时运行. 类似于:

复制上面的最后一行,即 http://0.0.0.0:8889/?token=e7f4c,粘贴到浏览器地址栏,即可进行 Jupyter Notebook. 点击进入 home/keras/mask-rcnn/notebooks,打开 mask_rcnn.ipynb.
在 mask_rcnn.ipynb 中逐步运行即可训练 MASK R-CNN 模型. 基于 Keras 和 Tennsorflow 在 GPU 上训练神经网络. 如果显存不足 11 GB,可能会遇到问题. 但即使是 2 GB 显存也可以训练网络最上面的部分.
训练模型不需耗时数天或数周,也没有大量的数据样本,但仍然能够得到相当好的结果. 这是因为这里 MASK R-CNN 的训练是在 COCO 上预训练模型权重上进行 fine-tune. 大多数图像数据集的基本特征是相似的,比如颜色和模式,因此可以用于其它图像模型的训练. 也叫作迁移学习.
在 notebook 底部,可以发现,形状预测的正确结果仅为 37%. 通过增加 STEPS_PER_EPOCH 到 750(训练样本总数),并运行 5 个或更多 epochs,可以得到更好的结果.
模型训练过程中或者训练完成后,可以利用 TensorBoard 查看图表进行可视化. 此时,需要登录刚刚已经启动的 Docker 容器,然后在浏览器访问运行 TensorBoard.
终端运行 docker ps,即可显示所有运行的容器. 采用 CONTAINER ID 可以进入模型训练的 Docker 容器内.
例如,假设 CONTAINER ID 是 d5242f7ab1e3,则可以运行 docker exec -it d5 bash 登录进入容器.
在容器内运行 tensorboard –logdir ~/data/shapes/logs –host 0.0.0.0,然后即通过 http://localhost:8877访问 TensorBoard.
如:

至此,即可训练定制数据的 MASK R-CNN 模型.
Resources
- [1] - deep-learning-explorer
- [2] - 数据转换工具 - pycococreator