题目:Deep Image Matting - CVPR2017
作者:Ning Xu, Brian Price, Scott Cohen, Thomas Huang
团队:Beckman Institute for Advanced Science and Technology
团队:University of Illinois at Urbana-Champaign
团队:Adobe Research
图像抠图,image matting,有很多应用场景,如图像编辑,电影工业,等等. 图像抠图问题的数学描述为:
$$I_i = \alpha_i F_i + (1-\alpha_i)B_i, \alpha \in [0, 1] $$
该数学问题对于每个像素有 7 个未知量,但只有 3 个已知量.
[1] - 对于每个像素 i 的 RGB 颜色,$I_i$ 是已知的.
[2] - 前景颜色 $F_i$,背景颜色 $B_i$ 和 matte 估计 $\alpha_i$ 是未知的.
可以看出,抠图的数学问题是两种颜色的线性组合.
早期抠图算法对于前景和背景颜色相近或者纹理复杂时,效果不好,其原因主要有:
[1] - 只采用了低层特征,low-level features
[2] - 缺乏高层上下文信息,high-level context Deep Image Matting 提出采用深度学习的方法来解决以上问题.
该模型主要包括两部分:
[1] - 深度卷积解码编码网络(encoder-decoder),采用 image 和对应的 trimap 作为输入,输出图片的 alpha 透明图(alpha matte).
[2] - 小型卷积网络,精炼第一个网络输出的 alpha matte 预测结果,以得到更精确的 alpha 值和更锐利的边缘. Image Matting 数据集 - 49300 training images 和 1000 testing images.

1. Matting 数据集
数据集的创建,将真实环境图片中的物体组合到新的背景上.
[1] - 首先,寻找简单背景的图片,如 Fig. 2a;
[2] - 接着,采用 Photoshop 仔细的手工创建其对应的 alpha matte,如 Fig. 2b,和干净的前景颜色,如 Fig. 2c;
[3] - 然后,将其作为 ground truth.
[4] - 最后,对于每个 alpha matte 和前景图片,随机从 COCO 数据集和 Pascal VOC 数据集中选取 N 张背景图片,并组合物体到背景图片中.

训练数据集有 493 个唯一的前景物体,有 49300 张图片; 测试数据集有 50 个唯一的前景物体,有 1000 张图片. (N=20)
2. Deep Image Matting 方法
如图:
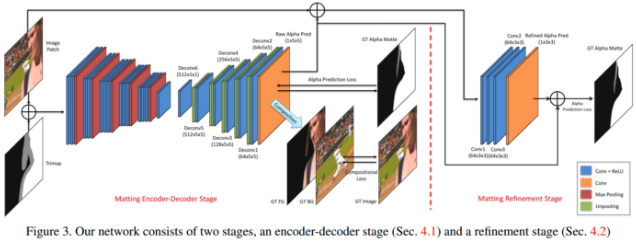
2.1. Matting Encoder-Decoder
网络结构中,第一阶段是深度编码-解码网络,类似于图片语义分割,边界预测(boundary prediction), hole filling 等.
2.1.1. 网络结构
网络的输入包括:图片image和对应的 trimap,根据起 channel dimension 链接,得到 4-channel input 输入.
网络包括编码网络和解码网络:
[1] - 编码网络根据 conv 和 max pooling 网络层,将 input 转化为降采样后的 feature maps;
[2] - 解码网络采用反操作,将 feature maps 上采样到特定输出,即 alpha matte.
详细来说,这里的 encoder 网络有 14 个卷积层和 5 个 max-pooling 层. decoder 网络是比 encoder 网络轻量网络,具有 6 个卷积层和 5 个 unpooling 层,以及最终的 alpha prediction 输出层,其参数更少,加速网络训练.
2.1.2. Losses
网络有两个 loss - alpha-prediction loss 和 compositional loss.
[1] - alpha-prediction loss 每个像素的 groundtruth alpha 值和预测的 alpha 值见的绝对值之差. 但由于绝对值的不可微,因此采用以下逼近 loss 函数:
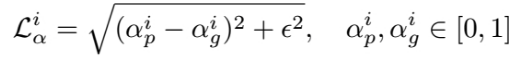
其中,
$\alpha_p^i $ - 像素 i 的预测层输出,其值区间为 [0, 1].
$\alpha_g^i $ - 像素 i 的 groundtruth alpha 值.
$\epsilon $ - 很小的值,10-6.
对应的梯度计算为:
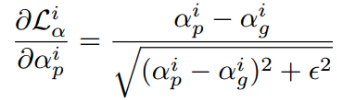
[2] - compositional loss groundtruth RGB 颜色和对应的预测 RGB 颜色间的绝对值之差. 其中,RGB 颜色由 groundtruth 前景,groundtruth 背景和预测的 alpha mattes 组成. 类似的,采用逼近形式:
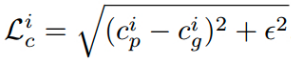
其中,
$c$ - RGB channel $p$ - 由预测 alpha 组成的图片
$g$ - 由 groundtruth alpha 组成的图片
compositional loss 确保网络能够学习更精确的 alpha 预测.
网络总的 loss 计算为:
$$\mathcal{L}_{overall} = w_l \cdot \mathcal{L} + (1- w_l) \cdot \mathcal{L}$$
其中,$w_l = 0.5$.
另外,由于只有 trimaps 未知区域的 alpha 值需要进行腿短,因此,根据像素位置设置两种类型 losses 的权重,有助于网络更关注重要区域. 这里,如果像素 i 位于 trimap 的未知区域,则 $w_i = 1$;否则,$w_i = 0$.
2.1.3. 具体实现
因为 49300 张图片中只有 493 个物体,为了避免过拟合,更有效的进行训练训练,采用了几种训练策略:
[1] - 以未知区域的像素为中心,随机裁剪 320x320 的 (image, trimap) 对,以增加采样空间.
[2] - 裁剪训练对(image, trimap)为不同的大小,如 480x480, 640x640, 并 resize 到 320x320,以使模型对不同尺寸更鲁棒,有助于网络更好的学习上下文和语义等高层信息.
[3] - 对每个训练对(image, trimap) 随机镜像处理.
[4] - 对 trimaps 从其 groundtruth alpha mattes 进行随机膨胀(dilated),以使得模型对 trimap 位置更加鲁棒.
[5] - 在每个训练 epoch 后,重新随机打乱训练输入. 训练阶段,encoder 网络采用 VGG16 的前 14 卷积层参数初始化. 由于网络输入是 4-channel,对第一个卷积层的新增 channel 用全零的卷积 filters 初始化. 所有的 decoder 网络参数采用 Xavier 随机变量初始化. 测试阶段,image 和对应的 trimap 链接组合为网络输入. 网络前向计算输出 alpha matte 预测. 对于大图片,GPU 显存不足时,可以采用 CPU 测试.
2.2 Matting refinement
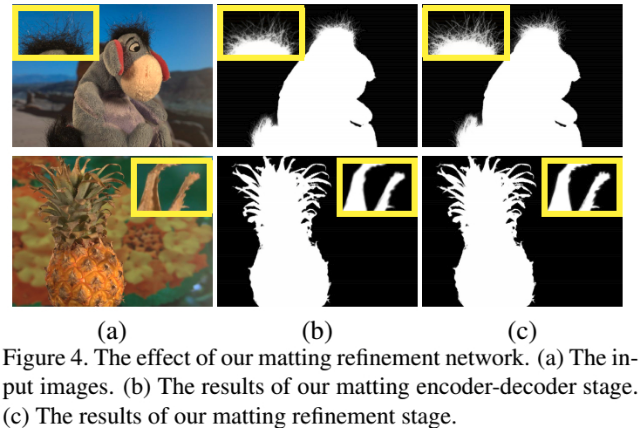
虽然采用 encoder-decoder 结构的第一阶段网络的 alpha 预测已经取得了很好的结果,但可能会出现过度平滑. 因此,采用第二阶段的网络精细化 alpha 预测结果.
2.2.1. 网络结构
第二阶段网络的输入是 image 和第一阶段的 alpha 预测结果(缩放到 [0, 255])的组合,即 4-channel 输入. 网络的输出是对应的 groundtruth alpha matte. 网络是全卷积网络,包含 4 个卷积层. 前 3 个卷积层的后面均接非线性 ReLU 层,没有下采样层. 另外,采用跳跃结构(skip-model),输入数据的第 4 channel 首先缩放到 [0, 1],然后添加到网络的输出. 如 Fig.3.
Matting refinement 的处理效果如 Fig.4. 其不会对 alpha matte 改变很大,而是对 alpha 值精细化和锐利化.
2.2.2. 具体实现
[1] - 训练阶段,首先更新不包含 refinement 部分的 encoder-decoder 网络部分; 当 encoder-decoder 子网络收敛后,固定其参数,再更新 refinement 子网络部分. 且只采用了 alpha-prediction loss. 并采用了 encoder-decoder 所采用的训练策略. 当 refinement 子网络也收敛后,最终 fine-tune 整个网络.
[2] - 测试阶段,给定 image 和 trimap,模型首先采用 encoder-decoder 网络,以得到初始化的 alpha matte 预测; 然后,image 和 alpha 预测一起作为 refinement 网络的输入,得到之中的 alpha matte 预测结果.
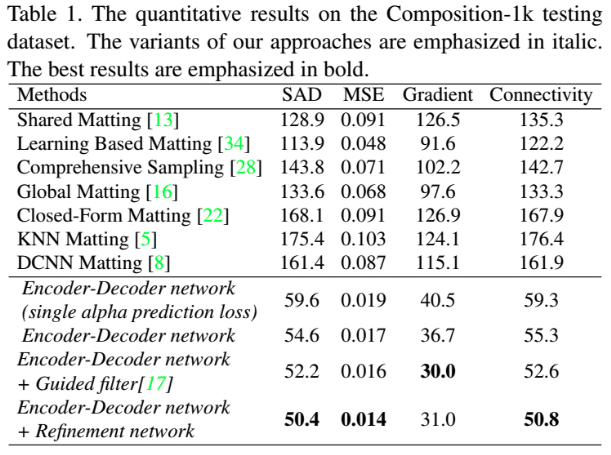
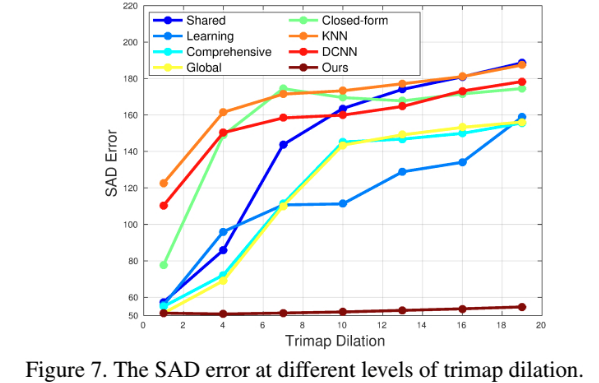
3. Results



4. Related
[1] - Deep Image Matting复现过程总结