原文:Deeplab Image Semantic Segmentation Network

DCNNs 在很多CV应用中取得了令人瞩目的成绩. 语义分割任务也不例外.
这里提供了基于 Tensorflow 的语义分割实现,基于谷歌发表的论文 - Deeplab_v3 - Rethinking Atrous Convolution for Semantic Image Segmentation.
1. 语义分割
常规图片分类 DCNNs 模型一般具有相似结构:输入为图片,输出表示图片类别的值.
通常情况下,分类 DCNNs 模型具有四个主要操作:
- 卷积 Convolutions
- 激活函数 Activation
- 池化 Pooling
- 全连接层 Full-connected layers
图片经过这些一系列操作的处理,输出表示每一个类别标签的特征向量.
这里,图片是作为整体来归类. 也就是,整张图片预测单个标签.
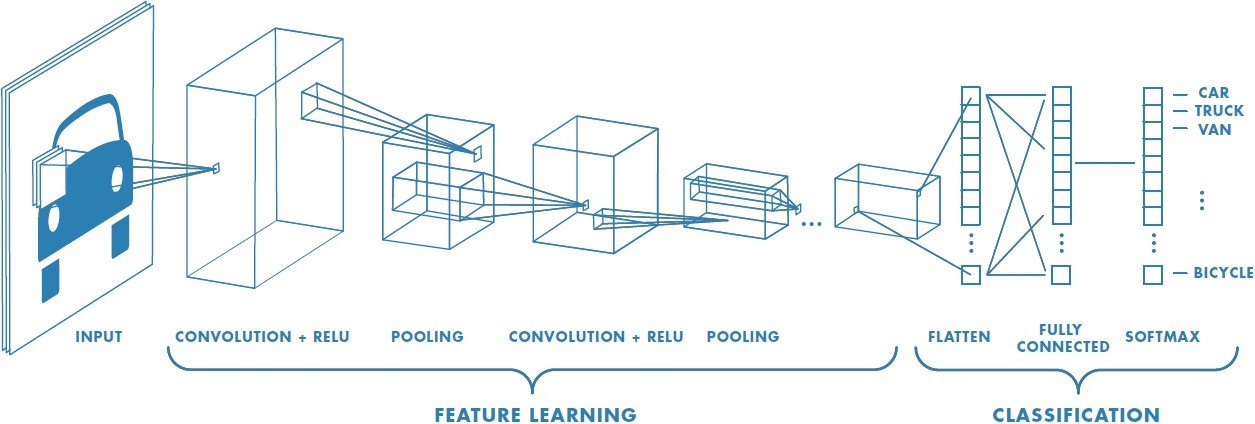
图片识别的标准深度学习模型 - From Convolutional Neural Network MathWorks
与图片分类不同的是,语义分割需要对图片的每个像素进行分类. 也就是说,语义分割时像素级的图片理解.
不过,语义分割不进行物体实例间的区分.
语义分割尝试对图片中每个像素分配独立的标签,如果是两个物体属于同一类别,则它们具有相同的类别标签.
实例分割是对属于相同类别的实例进行区分.

语义分割和实例分割的区别.(左)相同的物体和类别,(中)实例分割,(右)语义分割
常规的 DCNNs 模型,如 AlexNet和 VGG,不适合于密集预测任务.
一方面,分类模型的设计包含很多降低输入特征空间维度的处理,并得到高度抽象的特征向量,但这些特征向量缺乏清晰的细节信息.
另一方面,全连接层的计算,输出的固定长度的特征向量,丢失空间信息.
例如,采用一系列的卷积层来处理图片,而不采用 Pooling 和 全连接层. 设置每个卷积层的步长为1,相同的 padding 处理. 这样,每个卷积层都保持了其输入的空间维度. 如:
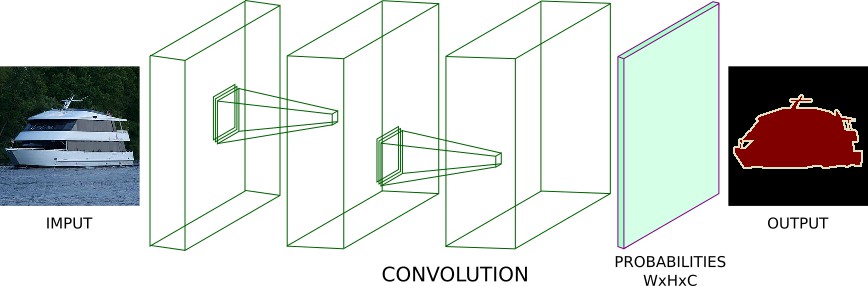
密集预测任务的全卷积网络. 没有 Pooling 和全连接层.
上图模型可以输出 [W,H,C] 大小的张量. 其中,W, H 时 Width 和 Height. C 是类别标签数目.
采用 argmax 函数对第三个轴进行处理,得到 [W, H, 1] 大小的张量. 然后,计算预测值与 Groundtruth 图片之间的交叉熵loss. 最后,求 loss 平均值,并采用 BP 算法训练网络.
不过,该模型存在一个问题:每个卷积层的步长为1,相同的 padding 处理虽然能够保持输入的维度,但会造成内存消耗和计算复杂度都很高.
为了解决该问题,语义分割网络一般包括三个主要成分:
- 卷积 Convolutions
- 下采样 Downsampling
- 上采样 Upsampling
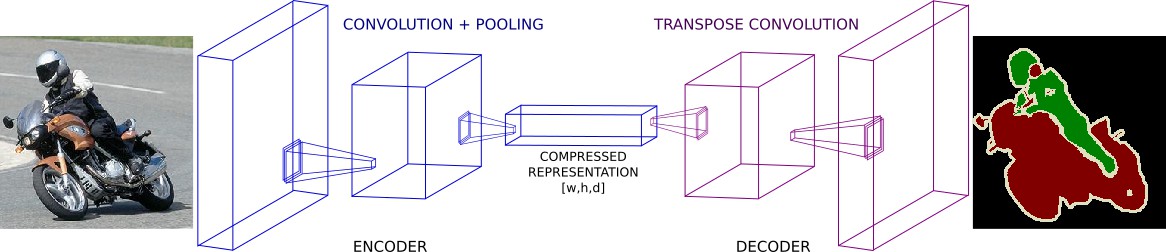
图片语义分割的 Encoder-decoder 结构
网络中下采样的方式有两种:卷积步长或者常规的Pooling操作.
一般而言,下采样的目标是:降低给 feature maps 的空间维度. 以进行更深的网络卷积,并减少内存消耗.
不过,计算过程中就会损失一些特征信息.
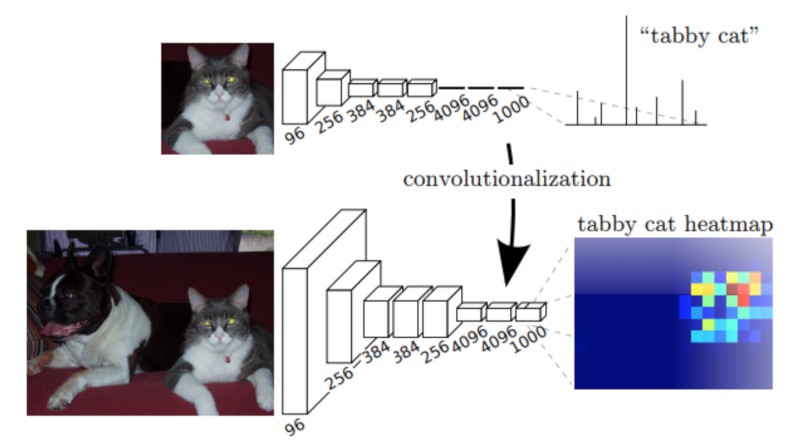
(上) VGG16 网络模型. 其后接了 3 个全连接层. (下) VGG16 模型,采用 1x1 卷积层来代替全连接层. 可以输出 一个 coarse heatmap.
From Fully Convolutional Networks for Semantic Segmentation
另外,语义分割网络结构的第一部分看起来像常用的经典 DCNNs 模型,除了没有加入全连接层.
第一部分网络处理后,可以得到 [w,h,d] 大小的特征向量. w, h, d 分别为 width, height, 和特征张量的 depth.
一般而言,会比原始的图片输入空间维度小,特征向量更紧凑.
此时,常规的图片分类会输出包含每个类别标签的概率向量(不包含空间信息). 而这里,我们将得到的压缩特征向量进行一系列上采样层的处理. 这些网络层用于重建网络第一部分结构的输出. 其目的是,增加输出向量的空间分辨率,以使得输出向量与输入具有相同的分辨率.
通常情况下,上采样层都是基于 strided transpose convolutions. 将网络层由深而窄deep and narrow layers转换为浅而宽wider and shallower layers. 这里采用 transpose convolutions 来提高特征向量维度到指定值.
在很多论文里,语义分割网络的这两部分结构为:编码-解码, encoder-decoder. 简单来说,首先,将图片信息编码为压缩向量,以表示原始输入图片;然后,解码该压缩向量,以将新高重构为希望的输出.
基于 encoer-decoder 结构,有很多网络实现,如 FCNs, SegNet 和 UNet. 在很多领域都可以看到成功的分割模型.
2. 网络模型
不同于 encoder-decoder 结构,DeepLab 采用了一种不同的语义分割方法.
DeepLab 提出一种网络结构,能够控制信号抽取(singal decimation),并提取多尺度的内容特征.
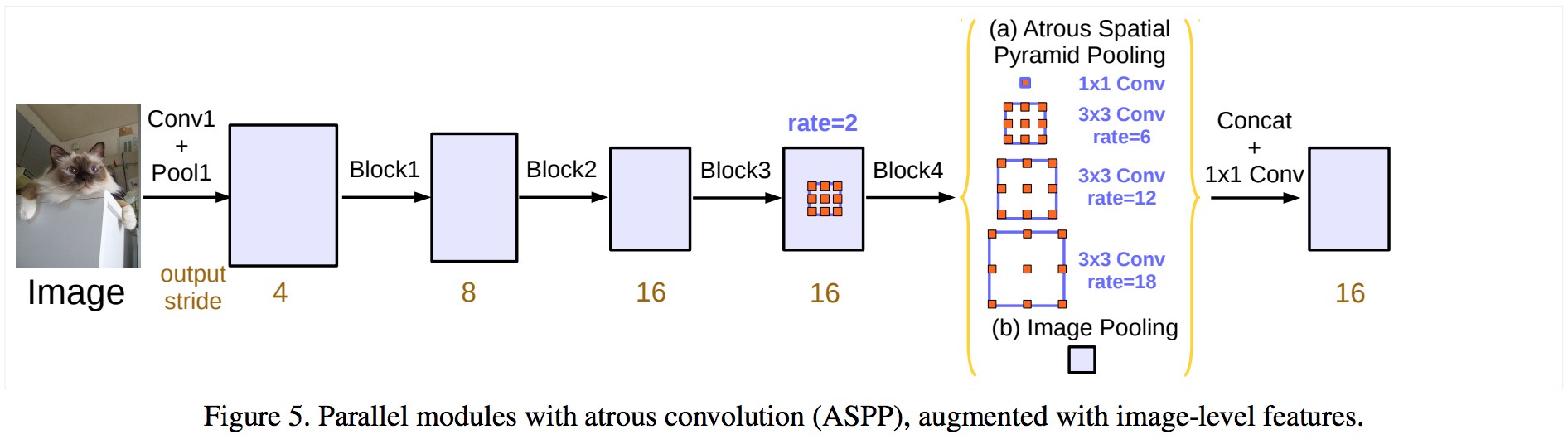
From Rethinking Atrous Convolution for Semantic Image Segmentation
DeepLab 采用在 ImageNet 上预训练的 ResNet 网络作为特征提取主干网络. 不过,其提出了新的参差模块(Residual Block) 以学习多尺度特征.
不同于常规的卷积层,DeepLab 的最后一个 ResNet Block 采用了带孔卷积(atrous convolutions).
另外,在该 ResNet Block 内,每个卷积采用不同的 dilation rates 来捕捉不同尺度的内容信息.
此外,在该 ResNet Block 的顶部(即输出),采用 Atrous Spatial Pyramid Pooling (ASPP) 操作. ASPP 采用不同 rate 的 dilation convolutions,来作为对任意尺度的区域进行分类..
为了进一步理解 Deeplab 结构,需要关注三个部分:
- (1) ResNet 结构
- (2) Atrous Convolutions
- (3) ASPP.
2.1 ResNets
ResNet 是 ILSVRC 2015 分类任务上取得第一的 DCNN 网络.
ResNets 的一个主要贡献是简化深度模型训练的框架.
ResNets 的原始版本,包含 4 个计算模块. 每个模块包含不同的残差单元 Residual Units. 残差单元以一种特殊的方式进行一系列卷积操作. 每个模块插入 max-pooling 层来降低特征图的空间维度.
原始论文中,提出了两种类型的残差单元 - baseline blocks 和 bottleneck blocks.
baseline unit 包含两个 3x3 卷积层, BatchNormalization(BN) 和 ReLU 激活层.
bottleneck unit 包含了三个堆积操作. 采用 1x1, 3x3 和 1x1 卷积来取代了原来的设计. 两个 1x1 卷积用于维度的降低和重建. 中间的 3x3 卷积对较低密度的特征向量上进行操作. 另外,在每个卷积层后和 ReLU 非线性激活层前插入 BN 层处理.
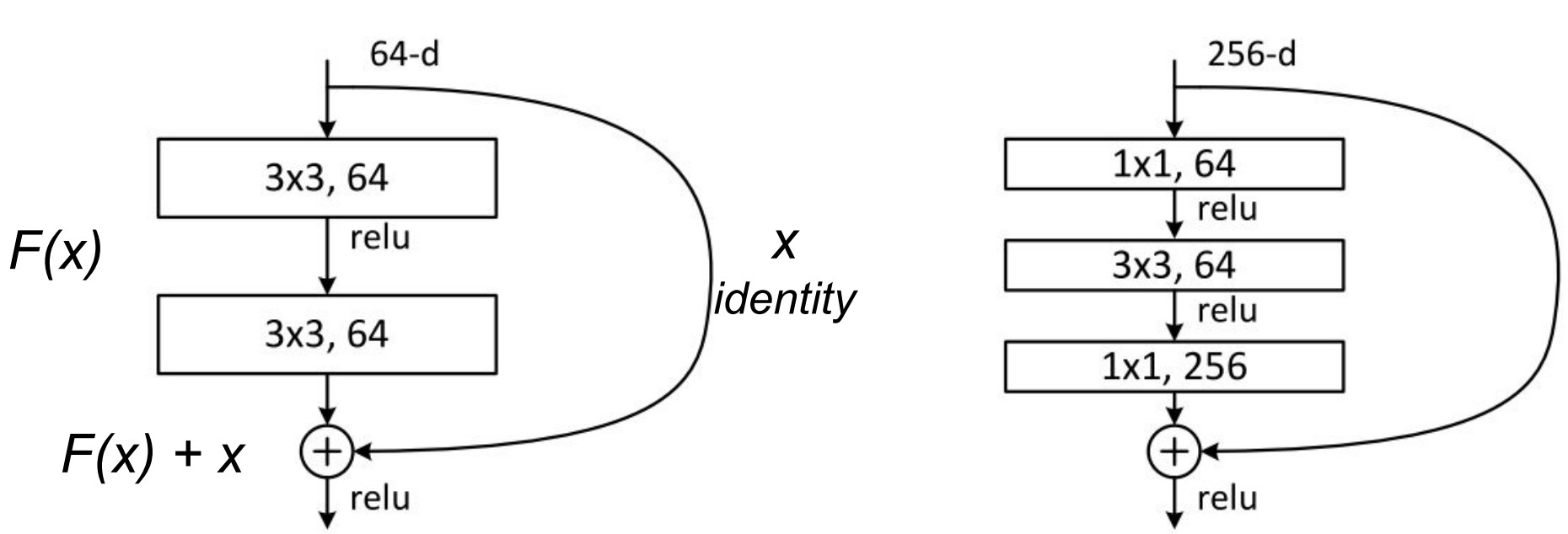
ResNet building blocks. (左) baseline unit (右) bottleneck unit
为了有助理解,记该组操作为输入 x 的函数 F.
经过 F(x) 内的非线性变换操作, 该残差单元组合 F(x) 的输出和原始的输入 x,即 F(x) + x.
将原始输入 x 和 非线性函数 F(x) 相加的好处是,可以前面网络层能够访问后面网络层的梯度信息. 换句话说,F(x) 的跳跃操作可以使得前面的网络层可以访问更强的梯度信号. 这种连接被证明可以简化深度网络的训练.
Non-bottleneck units 也表明随着模型容量的增加,精度也会有提升.
bottleneck residual units 具有一些实用的好处:第一,在参数量几乎相同的情况下,进行的计算量更多. 第二,与 Non-bottlenck 的计算复杂度相近.
实际上,bottleneck untis 更适用于训练深度模型,因为其训练时间和所需要的计算资源更少.
这里的实现采用的是,full pre-activation Residual Unit. 与标准的 bottleneck unit 不同的是,BN层和 ReLU 激活层所放置的顺序不同.
在 full pre-activation Residual Unit 中,BN 和 ReLu 层放置在卷积层前.

不同的 ResNet 模块构建结构. (a) 原始的 ResNet 模块. (d) full pre-activation Residual Unit 版本.
From Identity Mappings in Deep Residual Networks
Identity Mappings in Deep Residual Networks 论文里说明了,full pre-activation Residual Unit 版本 ResNet 的表现最好.
这些 ResNet 构建网络设计的区别仅仅时,在卷积块中 BN 和 ReLU 的次序不同.
2.2 Atrous Convolutions
Atrous Convolutions, 也叫作 dilated convolution,采用一个因子来控制卷积层操作,以增加卷积的接受野.
以 3x3 卷积 filter 为例.
当 dilation rate = 1 时,即为标准的卷积层.
如果 dilattion rate = 2,则可以达到增大卷积核的效果.
理论上, 首先,根据 dilation rate 来增加卷积核. 然后,采用零来填充空白空间,创建类似于稀疏的核filter. 最后,采用 dilated filter 来进行常规卷积操作.
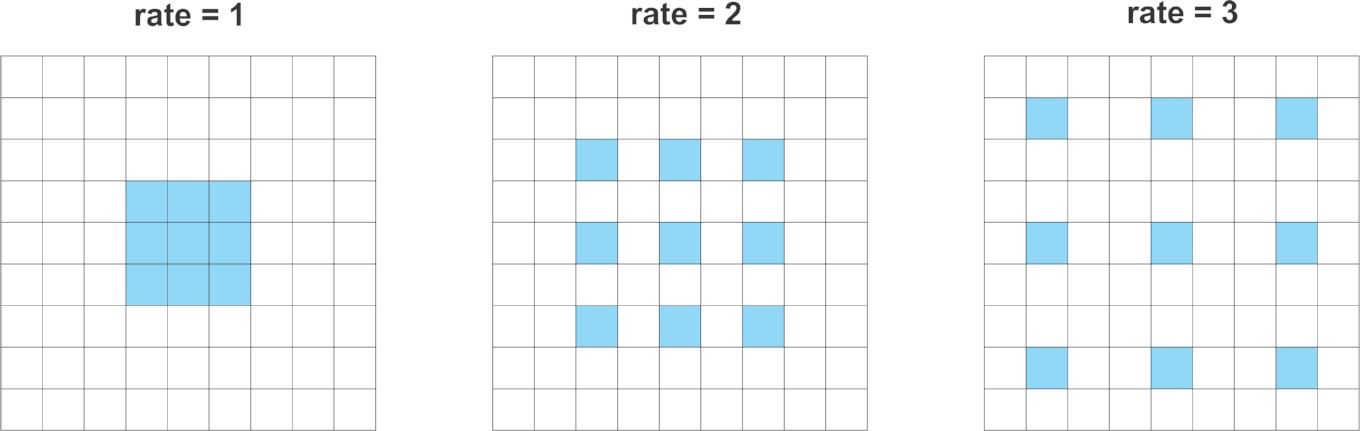
不同 rates 的 Atrous Conv.
因此,dilate rate=2,3x3 核的卷积,可以覆盖的面积是 5x5. 因为其像一个稀疏的卷积核,只有原来的 3x3 单元进行计算,并输出结果. 这里说 “像” 是因为大部分框架未采用稀疏核的 atrous 卷积,内存角度考虑.
类似地,对 3x3 核的卷积设置 atrous 因子为 3,则能够从 7x7 的对应区域获得信号.
这就可以控制计算特征响应的分辨率. 而且,atrous 卷积在不增加参数量和计算量的情况下,可以学习更大视野的内容信息.
DeepLab 还表明,dilation rate 必须根据 feature maps 的尺寸进行调整. 其尝试了在小 feature maps 上采用大的 dilation rates 的影响.

对于小 feature maps 采用大 dilation rates 的副作用.
对于 14x14 的输入图片, 3x3 卷积核,dilation rate=15, 会使 atrous 卷积的作用像常规的 1x1 卷积.
当 dilation rate 很接近于 feature map 的尺寸时,会使 atrous 卷积的作用像常规的 1x1 卷积.
换种方式,atrous 卷积的作用取决于 dilation rate 的合适选择. 因此,十分有必要了解网络 输出步长 output stride 的概念.
输出步长表示输入图片尺寸和输出特征图尺寸的比率. 定义了输入向量在网络传递过程中经受的信号抽取(singal decimation)情况.
对于输出步长等于 16 时,则 224x224x3 的图片输出 16x 的特征向量,即 14x14.
另外,DeepLab还讨论了分割模型不同输出步长的效果,得出的结论时,过度的信号抽取对于密集预测任务时不利的. 简单来说,较小输出步长的模型,较少的信号抽取,往往输出更精细的分割结果. 但是,小输出步长的网络模型的训练需要更久的时间.
DeepLab 给出了两种输出步长的配置 - 8 和 16. 输出步长为8 能够得到稍微更好的结果. 这里,考虑到实际应用,采用输出步长为 16.
另外,由于 atrous 模块不用进行下采样,ASPP 也对相同分辨率的特征响应进行操作. 即可以采用相对大的 dilation rates 来从多尺度内容中学习特征信息.
新的 Atrous Residual Block 包含三个残差单元. 总的来说,3 个单元包含 3 个 3x3 卷积.
受到多重网格(multigrid)方法的启发,DeepLab 提出对不同的卷积采用不同的 dilation rates.
多重网格定义了三个卷积层中每个卷积层的 dilation rates.
实际中,对于新增的 block4,当输出步长为output stride = 16, 多重网格MultiGrid = (1,2,4), 三个卷积层的 dilation rates 分别为 rates = 2 · (1, 2, 4) = (2, 4, 8).
2.3 Atrous Spatial Pyramid Pooling
ASPP 的思想是为模型提供多尺度信息.
因此,ASPP 增加了一系列不同 dilation rates 的 atrous 卷积.
这些 dilation rates 用于捕捉更长范围的内容.
另外,为了增加全局内容信息, ASPP 采用 Global Average Pooling(GAP) 来整合图像层的特征.
该版本的 ASPP 包含 4 个并行操作 - 一个 1x1 卷积和 3 个 dilation rates=(6, 12, 18) 的 3x3 卷积. 此时,feature maps 的 nominal stride(标称步长?) 为 16.
基于原始实现,训练和测试时均采用裁剪尺寸为 513x513. 因此,输出步长为 16,意味着 ASPP 接受的输入特征向量为 32x32.
另外,为了增加全局内容信息, ASPP 整合了图像级的特征. 首先,采用 GAP 来输出最后一个 atrous block 的特征;然后,对输出的特征采用 256 fliters 的 1x1 卷积来处理. 最后,采用双线性插值,以上采样到原来正确的维度.
@slim.add_arg_scope
def atrous_spatial_pyramid_pooling(net, scope, depth=256):
"""
ASPP consists of (a) one 1×1 convolution and three 3×3 convolutions with rates = (6, 12, 18) when output stride = 16
(all with 256 filters and batch normalization), and (b) the image-level features as described in https://arxiv.org/abs/1706.05587
:param net: tensor of shape [BATCH_SIZE, WIDTH, HEIGHT, DEPTH]
:param scope: scope name of the aspp layer
:return: network layer with aspp applyed to it.
"""
with tf.variable_scope(scope):
feature_map_size = tf.shape(net)
# apply global average pooling
image_level_features = tf.reduce_mean(net, [1, 2], name='image_level_global_pool', keep_dims=True)
image_level_features = slim.conv2d(image_level_features, depth, [1, 1],
scope="image_level_conv_1x1", activation_fn=None)
image_level_features = tf.image.resize_bilinear(image_level_features,
(feature_map_size[1], feature_map_size[2]))
at_pool1x1 = slim.conv2d(net, depth, [1, 1], scope="conv_1x1_0", activation_fn=None)
at_pool3x3_1 = slim.conv2d(net, depth, [3, 3], scope="conv_3x3_1", rate=6, activation_fn=None)
at_pool3x3_2 = slim.conv2d(net, depth, [3, 3], scope="conv_3x3_2", rate=12, activation_fn=None)
at_pool3x3_3 = slim.conv2d(net, depth, [3, 3], scope="conv_3x3_3", rate=18, activation_fn=None)
net = tf.concat((image_level_features, at_pool1x1, at_pool3x3_1, at_pool3x3_2, at_pool3x3_3), axis=3,
name="concat")
net = slim.conv2d(net, depth, [1, 1], scope="conv_1x1_output", activation_fn=None)
return net
最后,所有分支的特征连接一起,组成单个特征向量, 并将输出再接 1x1 卷积 - 采用 BN 和 256 个 filters.
ASPP 处理后,将其输出送入另一个 1x1 卷积,以得到最终的分割结果.
3. 实现细节
采用 ResNet50 作为特征提取器,这里 DeepLabV3 的实现采用了一下配置:
- 输出步长 output stride = 16
- 新增的 Atrous Residual Block(block4)中,多重网络的 atrous conv rates 固定为 (1, 2,4).
- 最后一个 Atrous Residual Block 后的 ASPP 采用的 rates 为 (6, 12, 18)
设置输出步长为16,是为了快速训练. 与输出步长为 8 相比,输出步长16使得 Atrous Residual Block 要处理的 feature maps 减少了 4 倍.
对于 Atrous Residual Block 内的 3 个卷积,采用的多重网格 multi-grid dilation rates 为 (1, 2,4).
ASPP 的 3 个并行的 3x3 卷积采用的 dilation rate 分别为 (6,12,18).
在计算交叉熵loss 前,将输出的分割结果调整为输入的尺寸. 正如论文所说,调整分割结果比调整 groundtruth 标签能保留更多分辨率细节.
基于原始的训练流程,将图片采用随机缩放因子 0.5~2.0 处理. 还对缩放图片进行了随机左右翻转.
最终,裁剪得到训练和测试的图片尺寸 - 513x513.
def deeplab_v3(inputs, args, is_training, reuse):
# mean subtraction normalization
inputs = inputs - [_R_MEAN, _G_MEAN, _B_MEAN]
# inputs has shape [batch, 513, 513, 3]
with slim.arg_scope(resnet_utils.resnet_arg_scope(args.l2_regularizer, is_training,
args.batch_norm_decay,
args.batch_norm_epsilon)):
resnet = getattr(resnet_v2, args.resnet_model) # get one of the resnet models: resnet_v2_50, resnet_v2_101 ...
_, end_points = resnet(inputs,
args.number_of_classes,
is_training=is_training,
global_pool=False,
spatial_squeeze=False,
output_stride=args.output_stride,
reuse=reuse)
with tf.variable_scope("DeepLab_v3", reuse=reuse):
# get block 4 feature outputs
net = end_points[args.resnet_model + '/block4']
net = atrous_spatial_pyramid_pooling(net, "ASPP_layer", depth=256, reuse=reuse)
net = slim.conv2d(net, args.number_of_classes, [1, 1], activation_fn=None,
normalizer_fn=None, scope='logits')
size = tf.shape(inputs)[1:3]
# resize the output logits to match the labels dimensions
#net = tf.image.resize_nearest_neighbor(net, size)
net = tf.image.resize_bilinear(net, size)
return net
为了实现 ResNet 中 block4 的多重网格 multi-grid 的 atrous convolutions,仅在 resnet_utils.py 文件中的部分内容:
...
with tf.variable_scope('unit_%d' % (i + 1), values=[net]):
# If we have reached the target output_stride, then we need to employ
# atrous convolution with stride=1 and multiply the atrous rate by the
# current unit's stride for use in subsequent layers.
if output_stride is not None and current_stride == output_stride:
# Only uses atrous convolutions with multi-graid rates in the last (block4) block
if block.scope == "block4":
net = block.unit_fn(net, rate=rate * multi_grid[i], **dict(unit, stride=1))
else:
net = block.unit_fn(net, rate=rate, **dict(unit, stride=1))
rate *= unit.get('stride', 1)
...
4. 训练
采用的数据集为 - augmented Pascal VOC dataset.
训练图片共 8252 张, 5623张来自 train set,2299 张来自 validation set.
这里从 2299 张 validation set 中移除 558 张图片,以在原始的 VOC2012 val 数据集上测试模型. 这 558 张图片仍在官方的 VOC validation set 中.
另外,新增 330 张 VOC 2012 train set 图片,其即不在 5623 张图片中,也不在 2299 张图片中.
最后,8252 张图片中的 10%, 约 825 张图片用于 validation. 其它的均用于训练.
不同于原始论文的是,该实现未在 COCO 数据集上预训练.
论文描述的训练和验证的一些技巧也没有采用.
5. Results
PASCAL VOC validation set:
- 像素准确率Pixel accuracy: ~91%
- 平均准确率Mean Accuracy: ~82%
- 平均 IoU, Mean Intersection over Union (mIoU): ~74%
- Frequency weighed Intersection over Union: ~86%.
可视化的分割结果:


6. 总结
语义分割领域无疑是计算机视觉的一个热门方向.
DeepLab 给出了经典编码-解码方法外的方案. 其利用了 atrous convlutions 进行不同范围内容的特征学习.