原文:电商商品同款识别图像算法研究 - 2022.07.07
出处: 大淘宝技术 - 微信公众号
淘宝官⽅⽐价平台“有好价”产品主打的就是实时更新全⽹最低价的好物,能在第⼀时间给⽤户展示低价的同款商品。
1. 业务背景
随着电商的快速发展,“货⽐三家”已经成为了⼤众的⽇常,但琳琅满⽬的商品给⽐价增添了不少负担,且每个购物平台的优惠规则也不相同。为了能够让⽤户实时发现最新低价,同款识别成为了破局的关键,并且只有完全相同的商品(sku维度相同)才有⽐价的意义。淘宝官⽅⽐价平台“有好价”产品主打的就是实时更新全⽹最低价的好物,能在第⼀时间给⽤户展示低价的同款商品。
2. 业务难点
不同于⼀般的以图搜图,只需要找出相似的图⽚即可,同款图像检索属于细粒度检索,需要找出精确同款。同款图像检索的难点如下:
- 类间混淆性问题,即如何区分相似款和同款,如图⼀,都是⿊⾊连⾐⻓裙,是通过以图搜图召回的结果,但在局部细节特征有区别,所以是⾮同款。
- 类内混淆性问题,即同款本身存在较⼤差异。如图⼆,是同⼀商品的主副图,但由于拍摄⻆度不同,加⼤了检索的难度。
如图:

3. 解决方案
3.1. 网络结构
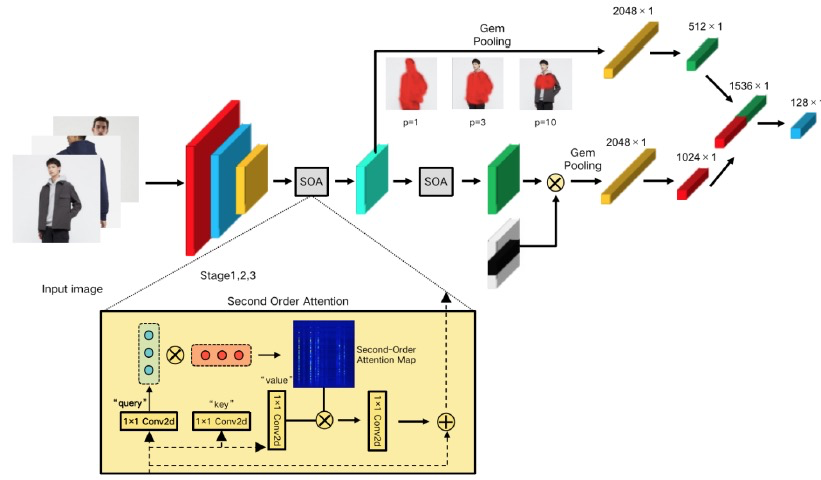
3.2. Batch Dropblock
随着淘宝商家与⽇俱增,商品展示也是“百花⻬放”,不同⻆度不同场景拍摄的商品图⽚给识别增加了难度,以及⽜⽪癣的泛滥,使得图⽚更难区分。⽽⽬前主流的CNN⽹络倾向于集中 在识别对象主体上,忽视了局部细节特征,因⽽抑制了其他可区分的部分,导致召回的商品 存在⼤量的相似款。当然,针对⽜⽪癣的问题,可以通过检测和分割来进⾏改善,但是这些⼯作在全域商品上处理明显太复杂笨重。
batch dropblock 旨在设计⼀种简单⼜适⽤性强的⽹络来解决这个问题。具体⽅案如下:
即对⼀个batch的特征图,随机遮挡住同样的⼀块区域,强迫⽹络在剩余的区域⾥去学⼀些细节的特征。通过结合全局特征和局部特征,使得CNN能提取到更鲁棒更全⾯的图像特征。
⽹络结构如图所示,使⽤ResNet50作为backbone⽹络提取特征,并将ResNet50中的第4个stage的下采样去除掉,从⽽获取更⼤的特征图。紧接着将特征分为两个分⽀,⼀个分⽀为全局分⽀学习全局特征,另⼀个分⽀为局部分⽀学习局部特征。在训练过程中,两个⽀会作为多任务同时学习。在测试过程中,会将全局特征与局部特征concat⼀起,作为图像的embedding向量。
Batch Dropblock的优点在于不会增加⽹络参数,且适⽤于所有的CNN 模型,针对不同的任务可以调节超参。
3.3. Second-Order Attention
淘宝商家经常会在图片上添加一些备注,这些备注一般都会用于描述商品,但由于卷积神经网络受限于感受野,使得备注和商品之间的联系难以获取到。对此,在卷积层之间加入 Self Attention 计算局部特征之间的相关性,具体算法如下:
$$ \mathbf{z} = softmax(\alpha \cdot \mathbf{q} ^T \mathbf{k}) $$
$$ \mathbf{f}^{so} = \mathbf{f} + \psi (\mathbf{z} \times \mathbf{v}) $$
q、k和v表示图像特征mxm经过1x1的卷积后生成的特征向量.
3.4. Gem Pooling
局部特征的max pooling 和全局特征的average pooling比较极端,可选用generalized mean pooling代替(可学习参数p的pooling layer),其中p值越大,特征图响应的局部化程度越高。其中当p接近无穷大时,就是max pooling,当p=1时,就是aveage pooling。
$$ \text{GeM} (\mathbf{f}^{so}, p) = (\frac{1}{N} \sum_{i=0}^N f_i^{so^p}) ^{\frac{1}{p}} $$
3.5. Loss Function
3.5.1. Triplet Loss
同款的核心的解决思路就是让网络缩小类内距离,扩大类间的距离,这就是Metric Learning的核心思想。因此采用优化Loss function的方式解决难点二遇到的问题。众所周知,Softmax优化类间的距离比较强,但是优化类内距离比较弱。
而基于Metric Learning构造的损失函数可以使类内紧凑和类间分离,典型的如Contrastive Loss、Triplet Loss,但这些Loss对于噪声比较敏感,单独训练时模型很难收敛。对此将Softmax和Triplet loss进行叠加训练,Loss Function如下,其中xi表示锚点,xp表示与锚点互为同款的正样本,xn表示与锚点互为非同款的负样本,f(x)表示模型输出的embedding。

3.5.2. Softmax Loss
仅仅使用Triplet Loss训练网络,网络难以收敛,需要加入分类的Softmax Loss,Softmax Loss能很好的放大逻辑值的差异,将正确类目的概率逼近 1,有利于模型快速收敛。
Softmax Loss分类器学习到的特征空间是呈现扇形分布,使用余弦距离检索会优于欧式距离。但Softmax Loss也有明显的问题,边界样本距离临近类的余弦距离很可能小于该样本到同类之间的距离,容易造成检索错误。
3.5.3. Solar Loss
由于图像在输入到网络之前需要resize到224×224的大小,但商品的图像不一致会导致形变,为此采用二阶相似度(能抓取更多的结构化信息,对形变的鲁棒性高)作为正则项加入到loss function中。
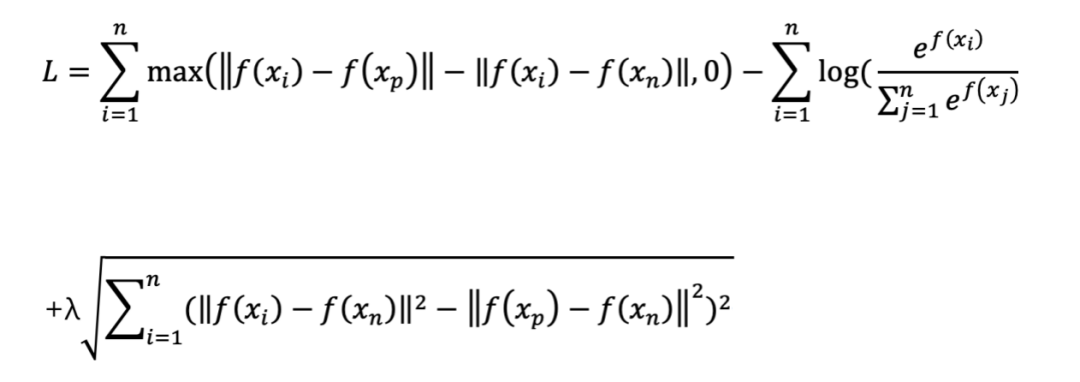
4. 实验过程
4.1. 训练集准备
在使用Triplet Loss进行训练时,需要提供图像的pair对作为训练样本,但pair对的标注成本非常大。如图所示,站内的主副图是商家对同一个商品通过拍摄不同角度生成的,所以大多数主副图都可以理解成同款。因此主副图完全可以作为Triplet Loss中的正样本对,而负样本只需要选择不用商品的主副图即可,最后分类任务的label则选择商品的叶子类目。
实验中训练集随机挑选了2230万的商品主副图,但由于主副图中存在商家展示的活动图片,这些噪声图片会使得模型无法收敛。为了处理噪声样本,我们在训练前对训练集进行清洗。首先利用ResNet50提取图像特征,再对提取出的特征利用DBSCAN聚类算法进行聚类,将噪声样本(如下图红框中的广告图)进行剔除。经过清洗后,得到1910万的图片数据。DBSCAN聚类算法需要对阈值进行调整,如果阈值太高会使得样本分布很单一化,阈值太低会使得噪声太多起不到过滤的效果。因此这里设置参数为0.8,保证加入困难的正样本提升检索模型的鲁棒性和泛化能力。

4.2. 训练过程
刚开始训练时,模型的权重是利用ImageNet数据集预训练的ResNet50模型,此时若选择一个较大的学习率,可能使得模型振荡。对此选择Warmup预热学习率的方式,在开始训练前几个epoch或者一些step内用较小的学习率。在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,可以加快模型收敛速度,使模型效果更佳。
4.2.1. 训练优化
同款图像检索模型训练过程中最重要的是难例挖掘,最近很多工作都是在改进采样或者加权方案。
目前的改进方法主要有两种思路:
- 第一种思路是在mini-batch内下功夫,对于mini-batch内的样本对,从各种角度去衡量他们的难度, 然后对于难样本对,给予更高的权重,比如N-pair Loss、Lifted Struture Loss、MS Loss就是这种做法;
- 第二种思路是在mini-batch的生成做文章,比如HTL、divide and conquer,他们的做法虽然看上去各有不同,甚至复杂精妙,但其实大差不差。不严谨地说,大致思路都是对整个数据集进行聚类,每次生成mini-batch不是从整个数据集去采样,而是从一个子集,或者说一个聚类小簇中去采样。这样的做法,由于采样范围本身更加集中,生成的mini-batch中难例的比例自然也会很高。
但以上的所有思路都是仅在对当前mini-batch里的样本对两两比较,形成样本对。跨越时空进行难例挖掘(Cross Batch Memory,XBM)就是突破这个局限,把过去的mini-batch的样本提取的特征也拿过来作比较,形成样本对,这样只需要占用少量的显存就能用于挖掘海量的难例样本。


XBM是极其简单的,需要先对网络用原来的方式训练,等待特征偏移变小,再加入XBM。一个特征队列去记忆过去mini-batch的特征,每次迭代,都会把当前mini-batch提取出来的最新特征加入队列,并把最老的特征踢出队列,从而保证XBM里的特征尽量是最新的。每次去构建样本的时候。将当前mini-batch和XBM里的所有特征都进行配对比较。从而形成了海量的样本对,如果XBM存储了过去100个mini-batch的特征,那么其所产生的样本对就是基于mini-batch方法的100倍。

由于XBM能起作用的假设前提是特征偏移小,但实际应用过程中很难确定在什么时刻模型特征偏移小可开始启动XBM,且偏移但相对大小受限于数据集和模型。因此提出了一种新的训练方式——Incremental XBM,具体操作如下:初始选择小的历史特征库,随着训练的进行,不断加大历史特征库的数量,效果优于一开始就指定大的特征库的数量。
5. 实验结果
选择天猫淘宝站内500w的商品作为商品底池,并选取其中30000个匹配对给外包标注,以下实验结果均为Top1000的召回率。
5.1. 模型优化实验
backbone选用ResNet50,对比实验分别为ResNet50+Self Attention,ResNet50+GEM Pooling,ResNet50+BDB,由于网络结构不同,收敛时间不同,将验证集上的召回率变化低于0.05%作为收敛条件。Loss Function仅使用Softmax Loss,实验结果如下:
| 算法方案 | 召回率 |
|---|---|
| ResNet50 | 57.75% |
| ResNet50+Self Attention | 58.03% |
| ResNet50+GEM Pooling | 59.27% |
| ResNet50+BDB | 63.64% |
从实验结果上可以看出BDB能明显提高模型的召回率。
5.2. Loss Function优化实验
backbone还是选用ResNet50,由于单独使用Triplet Loss,模型难以收敛,所以没有用于单独对比。实验分别为Softmax Loss,Softmax Loss+Triplet Loss,Softmax Loss+Solar Loss。实验结果如下:
| 算法方案 | 召回率 |
|---|---|
| Softmax Loss | 57.75% |
| Softmax Loss+Triplet Loss | 65.32% |
| Softmax Loss+Solar Loss | 58.27% |
5.3. 训练优化实验
backbone还是选用ResNet50,由于Cross Batch Memory主要是用于难例挖掘,Loss Function需要加入Triplet Loss。实验分别为ResNet50+Triplet loss,ResNet50+Triplet Loss+XBM,ResNet50+Triplet Loss+Incremental XBM。实验结果如下:
| 算法方案 | 召回率 |
|---|---|
| ResNet50+Triplet loss | 65.32% |
| ResNet50+Triplet loss+XBM | 67.54% |
| ResNet50+Triplet loss+Incremental XBM | 69.13% |
5.4. 最终实验结果
通过以上的实验效果,将所有的优化方案都汇总在一起,实验结果如下:
| 算法方案 | 召回率 |
|---|---|
| ResNet50+BDB+Triplet loss+Incremental XBM+GEM Pooling+Solar Loss+Self Attention | 77.65% |
总结
同款识别图像算法的优化:
第一,本文提出了通过随机遮挡住同样的一块区域,强迫网络在剩余的区域里去学局部特征,并结合局部特征和全局特征同时训练,在不新增参数的情况下,提升图像对于局部特征的关注;
第二,本文还通过加入self attention获取局部特征之间联系,增加了文本备注和商品的连接;
第三,本文采用多任务学习的方式,将Softmax Loss和Triplet Loss同时联合训练,并加入二阶Loss作为正则,不仅可以加快模型的收敛,还能大幅提高模型的鲁棒性;
第四,在训练过程中加入Cross Batch Memory,只需要增加少量内存的消耗,就能大幅度提高难例挖掘的效率。
在未来的工作汇总,会重点在以下几个方向进行优化:
- 利用Vision Transformer代替ResNet网络,Vision Transformer保留了更多的空间信息
- 目前只是针对item维度的同款识别,需要将图像同款识别的能力推广到sku维度上
参考文献
[1] Dai, Zuozhuo, et al. "Batch dropblock network for person re-identification and beyond." *Proceedings of the IEEE/CVF international conference on computer vision*. 2019.
[2] Vaswani, Ashish, et al. "Attention is all you need." *Advances in neural information processing systems* 30 (2017).
[3] Wang, Xun, et al. "Cross-batch memory for embedding learning." *Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition*. 2020.
[4] Ng, Tony, et al. "SOLAR: second-order loss and attention for image retrieval." *European Conference on Computer Vision*. Springer, Cham, 2020.
[5] Radenović, Filip, Giorgos Tolias, and Ondřej Chum. "Fine-tuning CNN image retrieval with no human annotation." *IEEE transactions on pattern analysis and machine intelligence* 41.7 (2018): 1655-1668.
[6] Dong, Xingping, and Jianbing Shen. "Triplet loss in siamese network for object tracking." *Proceedings of the European conference on computer vision (ECCV)*. 2018.
[7] Targ, Sasha, Diogo Almeida, and Kevin Lyman. "Resnet in resnet: Generalizing residual architectures." *arXiv preprint arXiv:1603.08029* (2016).
One comment
你好博主,请问有相关代码能看到吗,我这边最近也在研究同款商品的判断,对这篇文章很感兴趣