1. 分布式训练的基本概念
分布式训练需要多台机器/GPU. 在模型训练期间,这些设备之间会有通信.
为了更好地理解分布式训练,有几个重要的术语需要了解清楚:
- host: 主机(host)是通信网络中的主要设备. 在初始化分布式环境时,经常需要它作为一个参数。
- port: 这里的端口(port)主要是指主机上用于通信的主端口.
- rank: 在网络中赋予设备的唯一ID.
- world size: 网络中设备的数量.
- process group: 进程组(process group)是一个通信网络,包括设备的一个子集。总是有一个默认的进程组,它包含所有的设备. 一个子集的设备可以形成一个进程组,以便它们只在组内的设备之间进行通信.
示例如图:
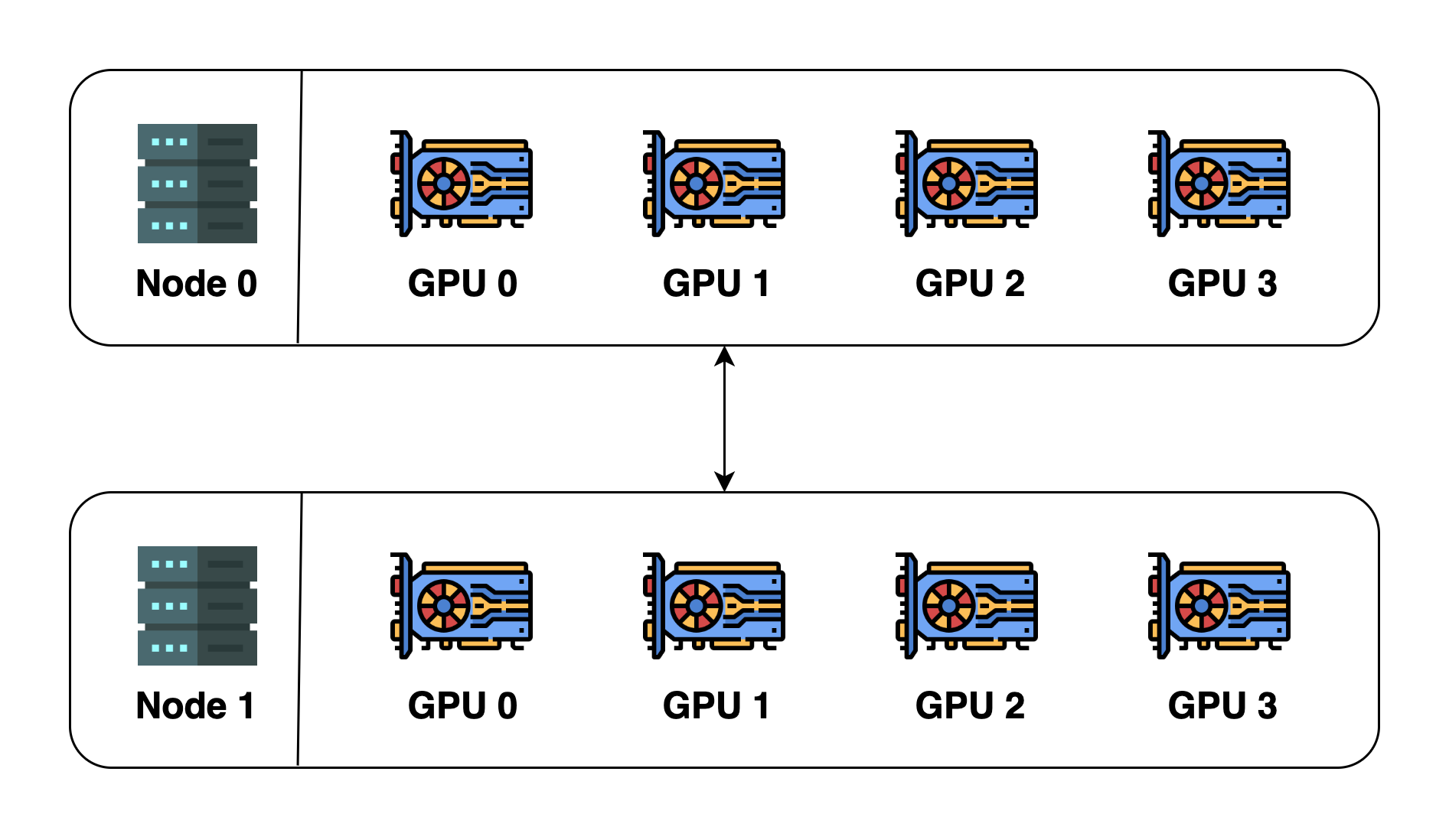
为了说明这些概念,假设有2台机器(也称为节点Node),每台机器有4个 GPU. 当在这两台机器上初始化分布式环境时,基本上启动了8个进程(每台机器上有4个进程),每个进程被绑定到一个 GPU 上.
在初始化分布式环境之前,需要指定主机(主地址)和端口(主端口).这里,可以让主机为节点0,端口为一个数字,如29500. 所有的8个进程将寻找地址和端口并相互连接,默认的进程组将被创建. 默认进程组的 world size 为8,细节如下:
| process ID | rank | Node index | GPU index |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 1 |
| 2 | 2 | 0 | 2 |
| 3 | 3 | 0 | 3 |
| 4 | 4 | 1 | 0 |
| 5 | 5 | 1 | 1 |
| 6 | 6 | 1 | 2 |
| 7 | 7 | 1 | 3 |
还可以创建一个新的进程组. 这个新的进程组可以包含任何进程的子集. 例如,可以创建一个只包含偶数进程的组:
| process ID | rank | Node index | GPU index |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 2 | 1 | 0 | 2 |
| 4 | 2 | 1 | 0 |
| 6 | 3 | 1 | 2 |
注意,rank 是相对于进程组而言的,一个进程在不同的进程组中可以有不同的 rank. 最大的 rank 始终是 world size of the process group - 1.
在进程组中,各进程可以通过两种方式进行通信.
- point-to-point: 一个进程向另一个进程发送数据.
- collective: 一组进程一起执行分散、聚集、all-reduce、广播等操作.
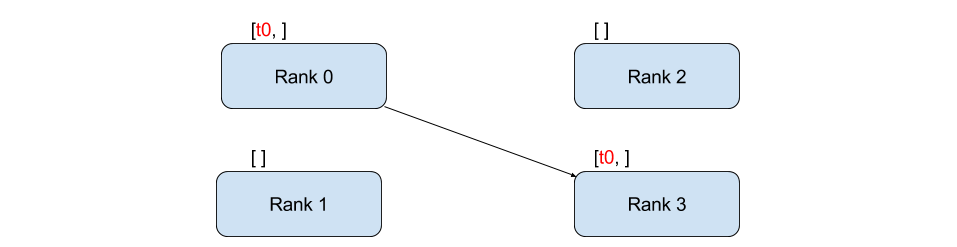
1.1. point-to-point communication
应用如,Baidu’s DeepSpeech 和 Facebook’s large-scale experiments.
1.2. Collective Communication

2. Broadcast/Scatter/Gatter/Reduce/All-reduce
Broadcast,Scatter,Gather,Reduce,All-reduce分别是什么? - 2019.09.10
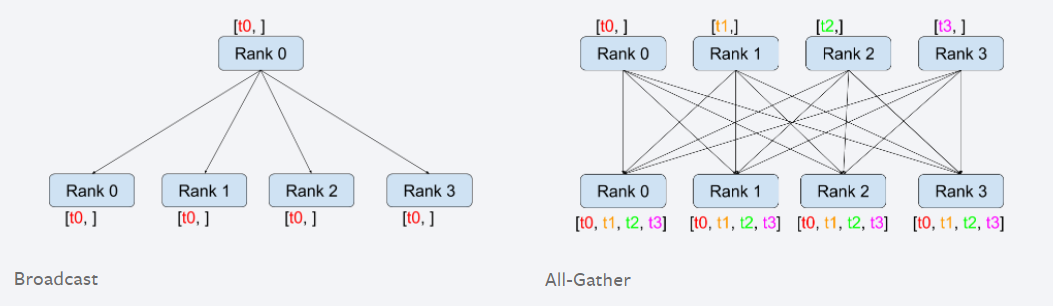
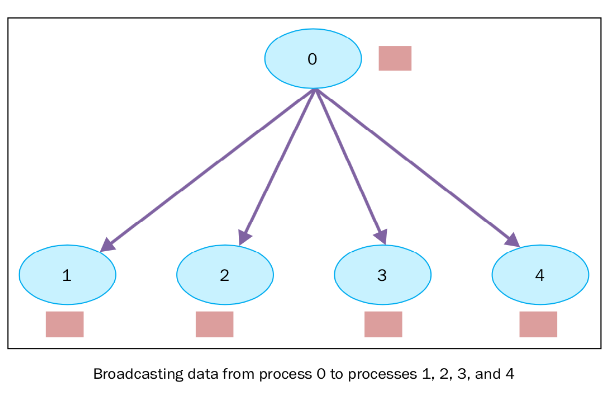
2.1. Broadcast
把同一份数据分发广播给所有人.
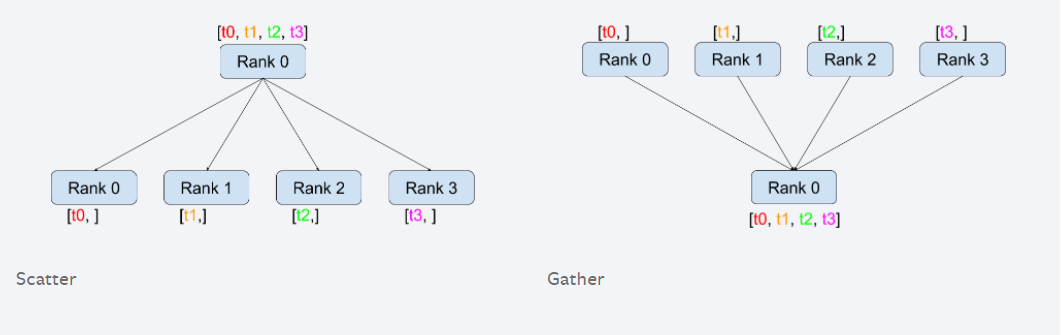
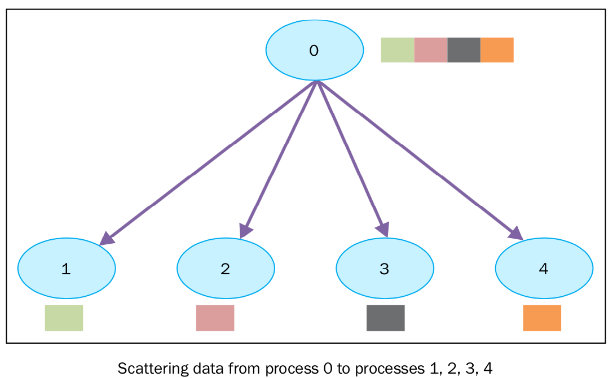
2.2. Scatter
不同于Broadcast, scatter可以将不同数据分发给不同的进程.
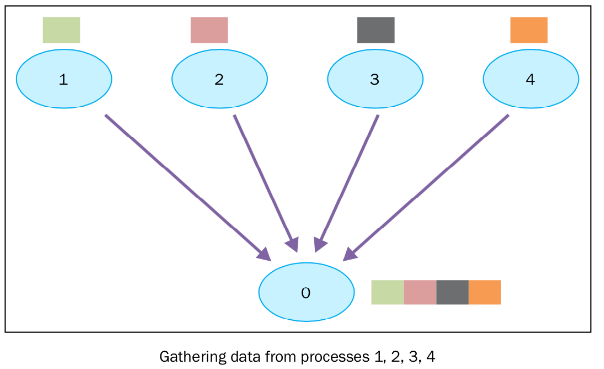
2.3. Gather
把多个进程的数据拼凑在一起.
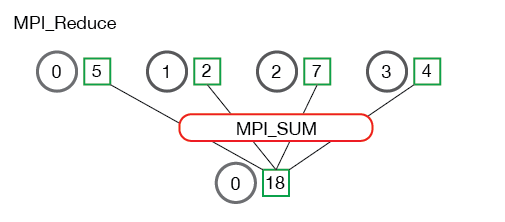
2.4. Reduce
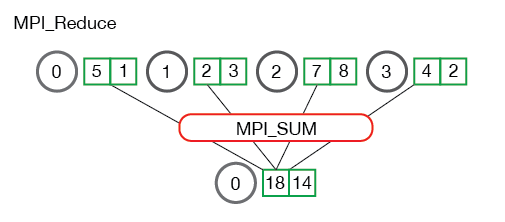
将多个进程中的数据按照指定的映射函数进行运算得到最后的结果存在一个进程中,例如下面两个图中的归约(Reduce)操作都是求和,将4个不同进程的数据归约求和后存在了第一个进程.
2.5. All-reduce
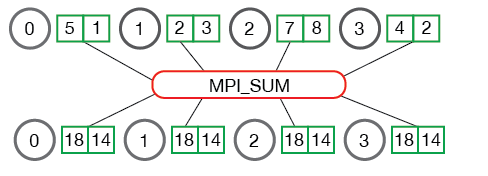
All-reduce与Reduce的区别就在于后者最后的结果是只保存在一个进程中,而All-reduce需要每个进程都有同样的结果. 所以All-reduce 一般包含 scatter操作,所以有时候也会看到 reduce-scatter 这种说法,其实reduce-scatter可以看成是all reduce的一种实现方式.
3. torch.distributed
PyTorch v1.6.0 中 torch.distributed 包含三种:
[1] - Distributed Data-Parallel Training (DDP)
DDP 是被普遍采用的单程序多数据训练范式( single-program multiple-data training paradigm).
采用 DDP 时,模型被复制到每个进程(process),然后每个模型副本被输入不同的输入数据样本.
DDP 负责梯度通信(gradient communication),以保持模型副本的同步,并将其与梯度计算重叠,以加快训练速度.
[2] - RPC-Based Distributed Training (RPC)
RPC 支持无法适应数据并行训练的通用训练结构,例如分布式管道并行(distributed pipeline parallelism)、参数服务器范式(parameter server paradigm)、以及 DDP与其他训练范式的组合.
RPC 有助于管理远程对象的生命周期,并将自动梯度引擎(autograd engine)扩展到机器边界之外.
[3] - Collective Communication (c10d)
c10d 库支持跨进程以组(group)的形式发送 tensor. 其同时提供了 collective communication APIs (e.g., all_reduce 与 all_gather) 和 P2P communication APIs (e.g., send 与 isend).
DDP 和 RPC 都是建立在 c10d 之上,DDP 采用了 collective communication;RPC 采用了 P2P communication.