论文: Look into Person: Self-supervised Structure-sensitive Learning and A New Benchmark for Human Parsing – CVPR 2017
attention+ssl.caffemodel - Google Drive
基于提供的训练模型进行测试, 模型是基于 Attention Model - Attention to Scale: Scale-aware Semantic Image Segmentation, 并提出 Self-supervised Structure-sensitive Loss 进行训练. 【论文阅读理解 - Look into Person: Self-supervised Structure-sensitive Learning】
方法框架:
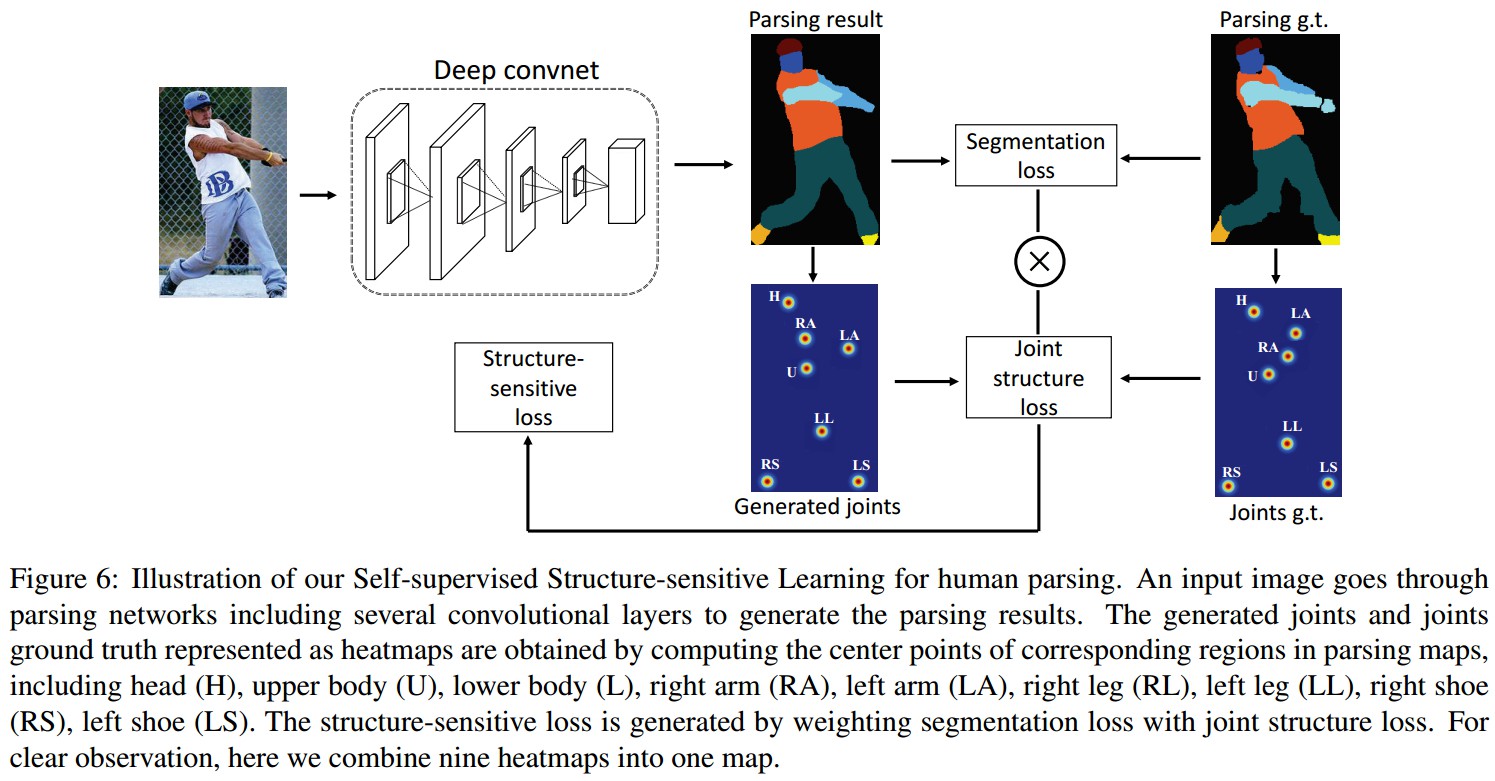
网络结构:
主体网络采用的是 Deeplabv2- Attention,训练网络:
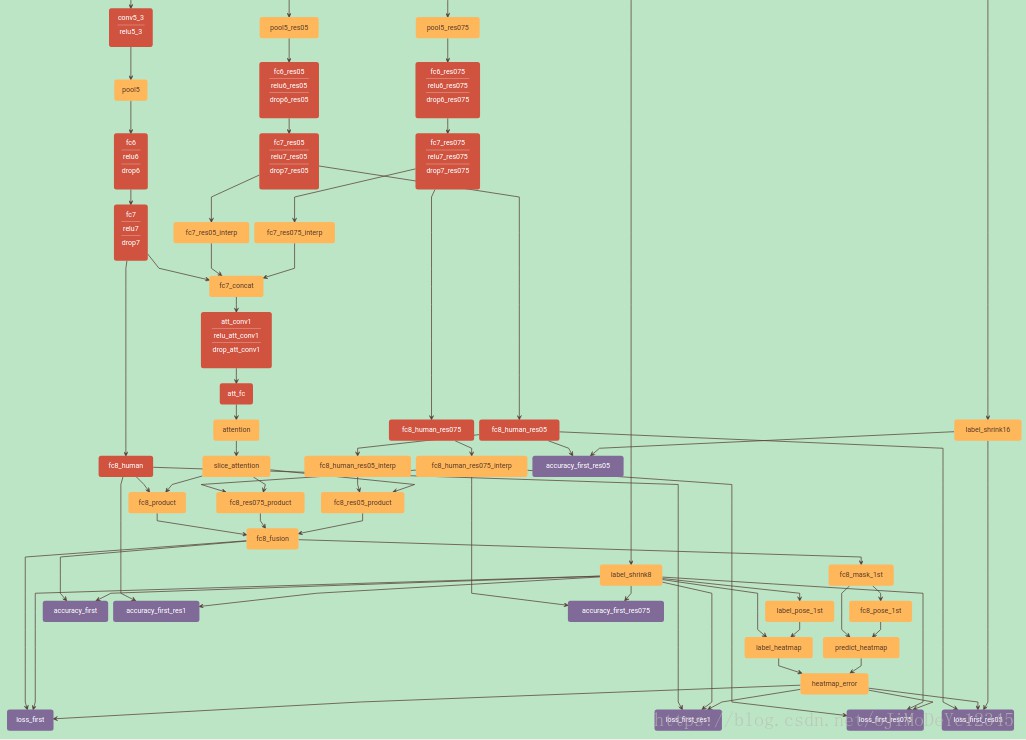
新增Caffe Layers:
- type: MaskCreate
name: fc8_mask_1st
cpp: mask_create_layer.cpp - type: PoseEvaluate
name: label_pose_1st, fc8_pose_1st
cpp: pose_evaluate_layer.cpp - type: PoseCreate
name: label_heatmap, predict_heatmap
cpp: pose_create_layer.cpp - type: HeatmapError
name: heatmap_error
cpp: heatmap_error_layer.cpp
部署网络:

简单测试示例 - demo.py
\#!/usr/bin/env python
from PIL import Image
import numpy as np
import cv2
import matplotlib.pyplot as plt
import sys
caffe_root = './caffe_ssl/'
sys.path.insert(0, caffe_root + 'python')
import caffe
caffe.set_device(0)
caffe.set_mode_gpu()
# caffe.set_mode_cpu()
##
deploy = 'model/deploy.prototxt'
weights = 'model/attention+ssl.caffemodel'
net = caffe.Net(deploy, weights, caffe.TEST)
mean = [104.008, 116.669, 122.675]
imgfile = './images/19.jpg'
# img = np.array(Image.open(imgfile), dtype=np.float32)
img = cv2.imread(imgfile, 1)
img = img.astype(np.float32)
img -= mean
img = cv2.resize(img, (513, 513), interpolation=cv2.INTER_LINEAR)
data = img.transpose((2, 0, 1))
net.blobs['data'].data[0, ...] = data
out = net.forward()
prediction = net.blobs['fc8_mask'].data[0, ...][0]
# output = net.blobs['fc8_interp'].data[0, ...]
# prediction = np.argmax(output.transpose([1, 2, 0]), axis=2)
plt.imshow(prediction)
plt.show()
print 'Done.'
Results


