Github - bnu-wangxun/Deep_Metric
Deep Metric Learning in PyTorch
Learn deep metric for image retrieval or other information retrieval.
代码学习
项目主要是关于深度度量学习.
整理思维导图如:
Xmind 文件:Deep_Metric_xmind.doc 文件名后缀去除.doc,修改为 .xmind.
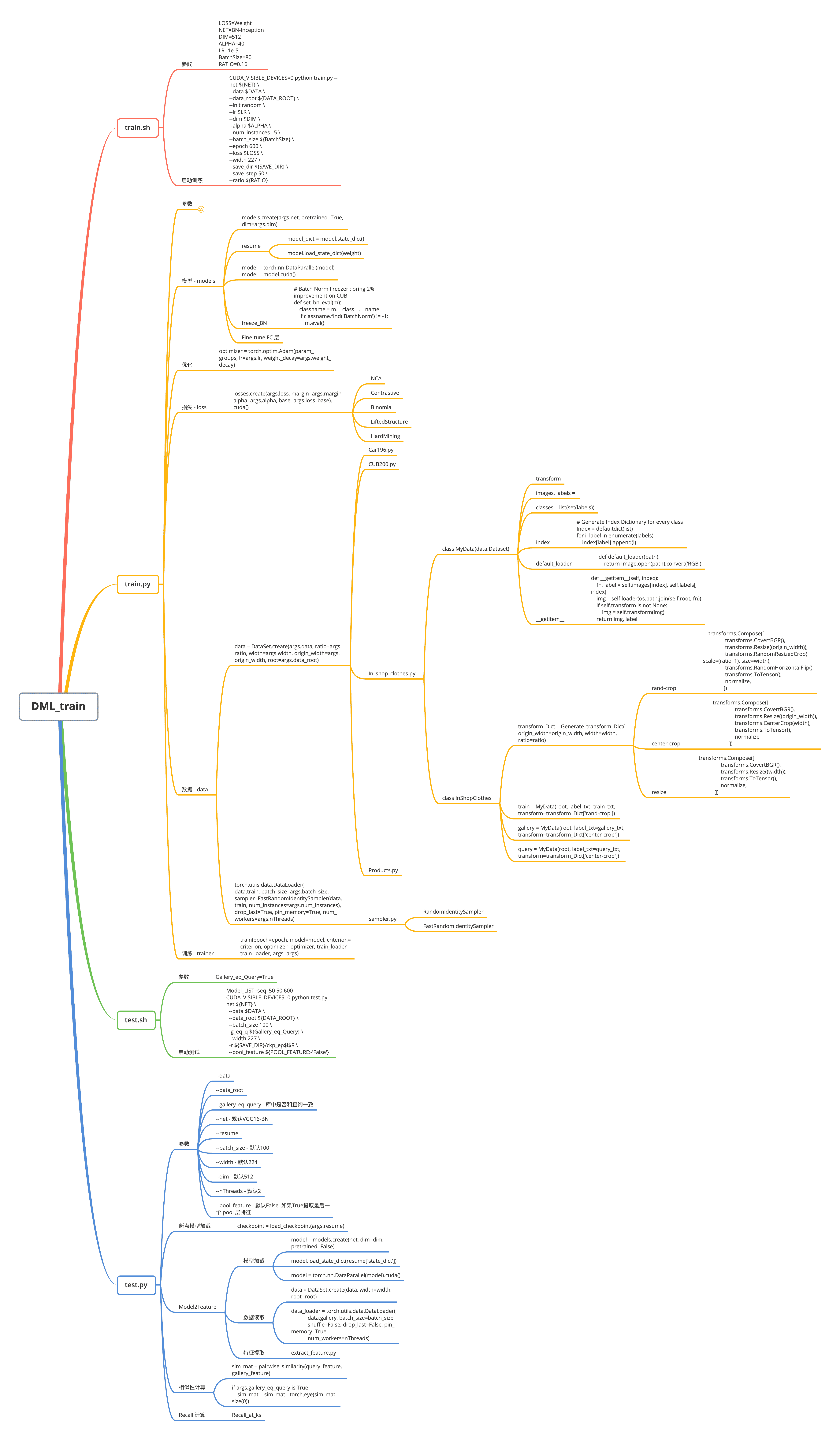
1. 训练
1.1. 数据读取
以 In-shop-clothes 数据集的读取为例:
def default_loader(path):
return Image.open(path).convert('RGB')
class MyData(data.Dataset):
def __init__(self, root=None, label_txt=None,
transform=None, loader=default_loader):
if root is None:
root = "/home/xunwang"
label_txt = os.path.join(root, 'train.txt')
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
if transform is None:
transform = transforms.Compose([
# transforms.CovertBGR(),
transforms.Resize(256),
transforms.RandomResizedCrop(scale=(0.16, 1), size=224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
])
#从 txt 文件中读取图片路径和标签
file = open(label_txt)
images_anon = file.readlines()
images = []
labels = []
for img_anon in images_anon:
img_anon = img_anon.replace(' ', '\t')
[img, label] = (img_anon.split('\t'))[:2]
images.append(img)
labels.append(int(label))
#
classes = list(set(labels))
#为每一类建立索引字典Index Dictionary
Index = defaultdict(list)
for i, label in enumerate(labels):
Index[label].append(i)
#
self.root = root
self.images = images
self.labels = labels
self.classes = classes
self.transform = transform
self.Index = Index
self.loader = loader
def __getitem__(self, index):
fn, label = self.images[index], self.labels[index]
img = self.loader(os.path.join(self.root, fn))
if self.transform is not None:
img = self.transform(img)
return img, label
def __len__(self):
return len(self.images)
#
class InShopClothes:
def __init__(self, root=None, crop=False, origin_width=256, width=224, ratio=0.16):
# Data loading
transform_Dict = Generate_transform_Dict(
origin_width=origin_width,
width=width, ratio=ratio)
if root is None:
root = 'data/In_shop_clothes'
train_txt = os.path.join(root, 'train.txt')
self.train = MyData(root, label_txt=train_txt,
transform=transform_Dict['rand-crop'])1.2. 数据采样
FastRandomIdentitySampler 采样函数:
from torch.utils.data.sampler import (
Sampler,
SequentialSampler,
RandomSampler,
SubsetRandomSampler,
WeightedRandomSampler)
class FastRandomIdentitySampler(Sampler):
def __init__(self, data_source, num_instances=1):
self.data_source = data_source
self.num_instances = num_instances
self.index_dic = defaultdict(list)
# for index, (_, pid) in enumerate(data_source):
# self.index_dic[pid].append(index)
self.index_dic = data_source.Index
self.pids = list(self.index_dic.keys())
self.num_samples = len(self.pids)
def __len__(self):
return self.num_samples * self.num_instances
def __iter__(self):
indices = torch.randperm(self.num_samples)
ret = []
for i in indices:
pid = self.pids[i]
t = self.index_dic[pid]
if len(t) >= self.num_instances:
t = np.random.choice(t, size=self.num_instances, replace=False)
else:
t = np.random.choice(t, size=self.num_instances, replace=True)
ret.extend(t)
# print('Done data sampling')
return iter(ret)1.3. 网络输出层微调
#基于预训练的分类模型
# Fine-tune the model: the learning rate for pre-trained parameter is 1/10
new_param_ids = set(map(id, model.module.classifier.parameters()))
new_params = [p for p in model.module.parameters() if
id(p) in new_param_ids]
base_params = [p for p in model.module.parameters() if
id(p) not in new_param_ids]
param_groups = [{'params': base_params, 'lr_mult': 0.0},
{'params': new_params, 'lr_mult': 1.0}]1.4. 模型训练
一个 epoch 的训练函数 train 如,trainer.py:
# coding=utf-8
from __future__ import print_function, absolute_import
import time
from utils import AverageMeter, orth_reg
import torch
from torch.autograd import Variable
from torch.backends import cudnn
cudnn.benchmark = True
def train(epoch, model, criterion, optimizer, train_loader, args):
losses = AverageMeter()
batch_time = AverageMeter()
accuracy = AverageMeter()
pos_sims = AverageMeter()
neg_sims = AverageMeter()
end = time.time()
freq = min(args.print_freq, len(train_loader))
for i, data_ in enumerate(train_loader, 0):
inputs, labels = data_
#变量封装为Variable
inputs = Variable(inputs).cuda()
labels = Variable(labels).cuda()
optimizer.zero_grad()
embed_feat = model(inputs) #特征
#损失函数计算
loss, inter_, dist_ap, dist_an = criterion(embed_feat, labels)
if args.orth_reg != 0:
loss = orth_reg(net=model, loss=loss, cof=args.orth_reg)
#BP 计算
loss.backward()
optimizer.step()
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
losses.update(loss.item())
accuracy.update(inter_)
pos_sims.update(dist_ap)
neg_sims.update(dist_an)
if (i + 1) % freq == 0 or (i+1) == len(train_loader):
print('Epoch: [{0:03d}][{1}/{2}]\t'
'Time {batch_time.avg:.3f}\t'
'Loss {loss.avg:.4f} \t'
'Accuracy {accuracy.avg:.4f} \t'
'Pos {pos.avg:.4f}\t'
'Neg {neg.avg:.4f} \t'.format
(epoch + 1, i + 1, len(train_loader), batch_time=batch_time,
loss=losses, accuracy=accuracy, pos=pos_sims, neg=neg_sims))
if epoch == 0 and i == 0:
print('-- HA-HA-HA-HA-AH-AH-AH-AH --')2. 测试
2.1. 特征提取
cnn.py - extract_cnn_feature:
def to_torch(ndarray):
if type(ndarray).__module__ == 'numpy':
return torch.from_numpy(ndarray)
elif not torch.is_tensor(ndarray):
raise ValueError("Cannot convert {} to torch tensor"
.format(type(ndarray)))
return ndarray
def extract_cnn_feature(model, inputs, pool_feature=False):
model.eval()
with torch.no_grad():
inputs = to_torch(inputs)
inputs = Variable(inputs).cuda()
if pool_feature is False:
outputs = model(inputs)
return outputs
else:
# Register forward hook for each module
outputs = {}
def func(m, i, o):
outputs['pool_feature'] = o.data.view(n, -1)
#
hook = model.module._modules.get('features').register_forward_hook(func)
model(inputs)
hook.remove()
# print(outputs['pool_feature'].shape)
return outputs['pool_feature']extract_feature.py
def extract_features(model, data_loader, print_freq=1, metric=None, pool_feature=False):
# model.eval()
batch_time = AverageMeter()
data_time = AverageMeter()
feature_cpu = torch.FloatTensor()
feature_gpu = torch.FloatTensor().cuda()
trans_inter = 1e4
labels = list()
end = time.time()
for i, (imgs, pids) in enumerate(data_loader):
imgs = imgs
outputs = extract_cnn_feature(model, imgs, pool_feature=pool_feature)
feature_gpu = torch.cat((feature_gpu, outputs.data), 0)
labels.extend(pids)
count = feature_gpu.size(0)
if count > trans_inter or i == len(data_loader)-1:
# print(feature_gpu.size())
data_time.update(time.time() - end)
end = time.time()
feature_cpu = torch.cat((feature_cpu, feature_gpu.cpu()), 0)
feature_gpu = torch.FloatTensor().cuda()
batch_time.update(time.time() - end)
print('Extract Features: [{}/{}]\t'
'Time {:.3f} ({:.3f})\t'
'Data {:.3f} ({:.3f})\t'
.format(i + 1, len(data_loader),
batch_time.val, batch_time.avg,
data_time.val, data_time.avg))
end = time.time()
del outputs
return feature_cpu, labels2.2. 相似性计算
sim_mat = pairwise_similarity(query_feature, gallery_feature)pairwise_similarity 函数:
def normalize(x):
norm = x.norm(dim=1, p=2, keepdim=True)
x = x.div(norm.expand_as(x))
return x
def pairwise_similarity(x, y=None):
if y is None:
y = x
# normalization
y = normalize(y)
x = normalize(x)
# similarity
similarity = torch.mm(x, y.t())
return similarity
#
def pairwise_distance(features, metric=None):
n = features.size(0)
# normalize feature
x = normalize(features)
if metric is not None:
x = metric.transform(x)
dist = torch.pow(x, 2).sum(dim=1, keepdim=True)
# print(dist.size())
dist = dist.expand(n, n)
dist = dist + dist.t()
dist = dist - 2 * torch.mm(x, x.t())
dist = torch.sqrt(dist)
return dist2.3. Recall 计算
Recall_at_ks 函数:
def to_numpy(tensor):
if torch.is_tensor(tensor):
return tensor.cpu().numpy()
elif type(tensor).__module__ != 'numpy':
raise ValueError("Cannot convert {} to numpy array"
.format(type(tensor)))
return tensor
def Recall_at_ks(sim_mat, data='product', query_ids=None, gallery_ids=None):
"""
:param sim_mat:
:param query_ids
:param gallery_ids
:param data
Compute [R@1, R@10, R@100, R@1000]
"""
ks_dict = dict()
ks_dict['product'] = [1, 10, 100, 1000]
ks_dict['shop'] = [1, 10, 20, 30, 40, 50]
if data is None:
data = 'product'
k_s = ks_dict[data]
sim_mat = to_numpy(sim_mat)
m, n = sim_mat.shape
gallery_ids = np.asarray(gallery_ids)
if query_ids is None:
query_ids = gallery_ids
else:
query_ids = np.asarray(query_ids)
num_max = int(1e6)
if m > num_max:
samples = list(range(m))
random.shuffle(samples)
samples = samples[:num_max]
sim_mat = sim_mat[samples, :]
query_ids = [query_ids[k] for k in samples]
m = num_max
# Hope to be much faster yes!!
num_valid = np.zeros(len(k_s))
neg_nums = np.zeros(m)
for i in range(m):
x = sim_mat[i]
pos_max = np.max(x[gallery_ids == query_ids[i]])
neg_num = np.sum(x > pos_max)
neg_nums[i] = neg_num
for i, k in enumerate(k_s):
if i == 0:
temp = np.sum(neg_nums < k)
num_valid[i:] += temp
else:
temp = np.sum(neg_nums < k)
num_valid[i:] += temp - num_valid[i-1]
return num_valid / float(m)2.4. topK 计算
Compute_top_k 函数:
import heapq
def Compute_top_k(sim_mat, k=10):
"""
:param sim_mat:
Compute
top-k in gallery for each query
"""
sim_mat = to_numpy(sim_mat)
m, n = sim_mat.shape
print('query number is %d' % m)
print('gallery number is %d' % n)
top_k = np.zeros([m, k])
for i in range(m):
sim_i = sim_mat[i]
idx = heapq.nlargest(k, range(len(sim_i)), sim_i.take)
top_k[i] = idx
return top_k
2 comments
不知道能不能加一下博主练习方式!!我也是在运行这个项目!!有些细节想问问!!
QQ: 2258922522,互相学习