原文:案例分享 | 知衣科技利用 TensorFlow 构建 3D 试衣 - 2020.07.02
出处:TensorFlow - 微信公众号
1. 服装设计的痛点
在服装行业中,服装设计效果确认是一个费时费力的高成本工作.
在一件服装版型确定后,需要为服装添加上图案或者底色,从而得到一个完整的服装设计效果. 一般设计好的服装设计稿为多张矢量图,想要看到实际的服装效果一般需要将设计效果图给到打版工作室或者相应的工厂, 进行服装样衣的制作. 制作完成后,设计师才可拿到真实样衣并分析服装的问题. 一般来说进行服装样衣制作成本与时间都比较高,因此无法批量尝试不同的选择. 此外,设计师拿到样衣后会对之前的颜色、图案与一些设计细节等信息进行一定修改,修改完成一般还可能需要进行二次打版. 服装设计中这个过程会不断被重复,并不断进行样衣制作,问题发现修改样衣制作的循环过程中,整个过程成本高昂,同时费时费力,大大拉长了服装的设计生产周期.
知衣科技基于 TensorFlow 开发了基于图像的 3D 智能试衣技术,帮助服装从业者缓解这个问题. 本文大致介绍系统问题定义分析、模型构建与模型训练等过程.
2. 问题定义与解决思路
2.1. 问题定义
在服装设计过程中,痛点在于光看设计图稿无法了解服装设计完成后的实际效果,所以一般都需要进行打版,拿到实际样衣并穿在模特身上才知道实际的效果. 如果可以直接从已有上身效果图中替换样衣上的颜色与图案能够帮助设计师快速验证设计结果,大幅度缩短设计生产周期.
此处以颜色与服装图案为例,来研究元素替换问题. 一般而言服装上的颜色有局部与整体,图案也有局部与整体的区别. 如何将颜色信息与图案信息添加到服装图像上,一般可以采用贴图的方案, 直接将色块 / 图案直接贴到原图中, 贴图是一个比较快捷方便的解决方案. 但是贴图会带来两个问题.
第一个问题是如何来区分服装与背景边界. 这个问题是一个相对成熟的图像分割问题,可以通过图像分割技术来进行边界判别,区分边界与服装部分. 另一个问题是贴图是平面类型的,会覆盖服装的细节信息,同时会丧失真实感,如下图所示:

图 1. 贴图 3D 试衣
从图 1 可以看出,一件衣服替换颜色信息为黑色后,虽然整件衣服是黑色,但是如果每一个像素的颜色都是一样的,那看起来会非常生硬. 针对贴图问题,主要原因在于贴图无法察觉到服装上每个像素点之间的差异,贴图时每个点做了同样的对待. 解决方法可以对图中的服装计算一下每个点的重要程度,得到一张服装权重图,然后将服装权重图与贴图做一个乘法,即可做一个良好的转换.
针对服装权重这边,比较好的做法是使用服装的深度信息做为服装本身的权重,深度信息可以反映服装图上每个点的特异信息,同时因为图像一般使用普通相机拍摄,没有自带绝对的深度信息, 所以,通过单张图做深度估计,得到单目的相对深度信息,效果如下图所示:

图 2. 服装图像单目深度信息
深度图中每个点反应是真实图像中每个点距离人眼的相对距离远近,通过深度信息使得视觉看起来更具有真实感,而不是平铺的感觉.
获取到了深度信息,在贴图与变色时,即可消除没有真实感的问题. 但是因为服装上本身一般会自带颜色与一些简单图案的关系,如果不做消除,直接贴图或者上色,原始服装上的图案颜色也会继续存在在上色的服装中,如图 3 所示.

图 3.1. 添加图案效果对比图

图 3.2. 添加颜色细节效果对比图
图 3.1 从左往右依次为原图,未去除图案叠加新图案效果图,去除图案叠加新图案效果图.
图 3.2 从左到右为原图,未去除图案上色效果图,以及去除图案上色效果图.
从图中很明显看出,没有去除图案时无论是添加图案还是上色,在原图中均保留了原始图像的痕迹,导致效果变差. 所以一般也需要将原始服装上的颜色给抹除,变成灰度或者白色的服装,以方便调整原始服装的纹理和颜色.
2.2. 解决思路
综合上述分析, 需要解决的问题有 3 个:
- 需要对原始图像做服装分割操作
- 需要对服装数据做相对的单目深度估计
- 需要对服装数据做颜色图案信息擦除
上述 3 个问题都可以看成是 Img2Img 任务.
a 任务可以使用分割模型进行解决,b 任务和 c 任务可以自行构建类似 FCN、UNet 等结构进行解决.
常规思路需要训练 3 个模型来解决这 3 个问题. 先由分割模型将原始图像中的服装分割出来,然后将分割得到的服装分别送入 b 任务模型和 c 任务模型中,最后合并 b 任务和 c 任务的输出,得到最终的结果. 这个思路最简单也比较方便,多个任务可以并行处理,也能单独对每一个模型进行调整.
但是训练 3 个模型对标注数据量和模型训练参数调优等要求较高. 此外可能会因为使用数据之间不同分布的问题,造成模型之间并不能良好的协调. 所以,考虑将任务进行一个合理的合并. 首先针对 b 任务和 c 任务,一个是对颜色和图案信息进行擦除,一个是深度估计任务,输入均是服装部分. 可以对 b,c 任务进行合并,构建一个输入为 wxhx3,输出为 wxhx4 的模型,其中多出来的一个维度刻画了每一个像素的深度信息. 该模型同时完成深度估计和服装信息擦除任务. 合并后的任务称为 d 任务. 任务 a 是一个分割任务,它是从原始图像中切割出服装. 该任务的本质是去除背景的工作. a 任务与 d 任务从表面看差异较大,较难合并,但是从另一个角度来看,2 个任务均是需要保留服装部分,任务之间有一定的相似性. 同时 a 任务的输出是 d 任务的输入,所以,可以对任务继续进行合并. 合并后的模型结构如下图所示:
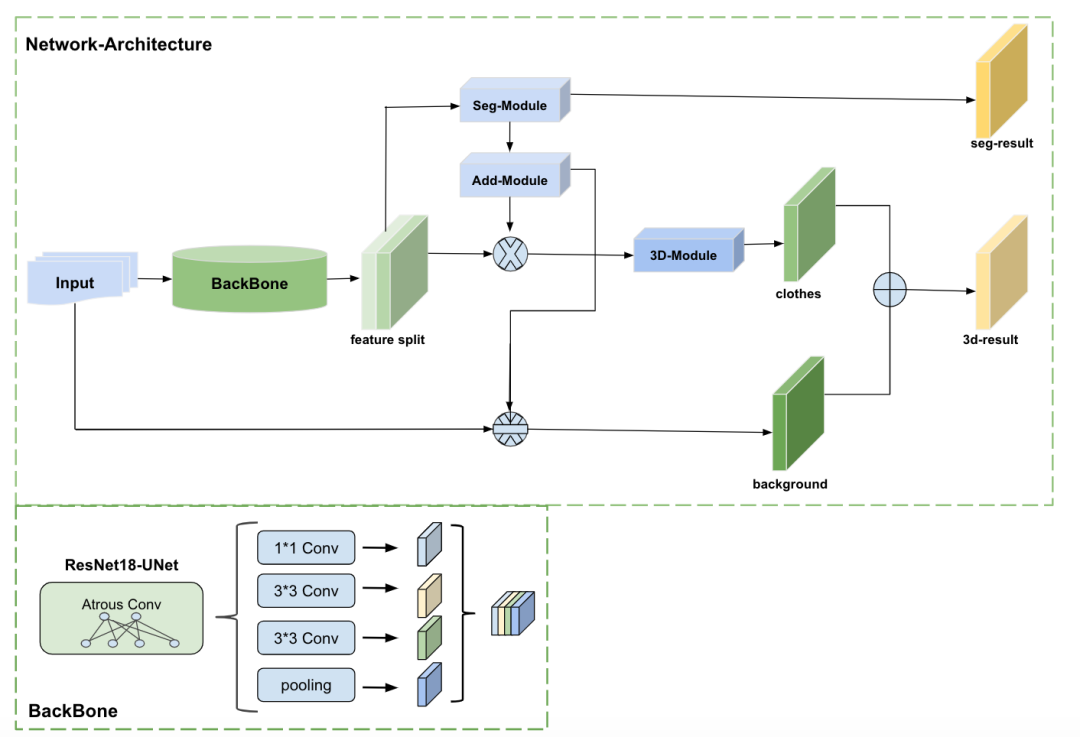
图 4. 3D 试衣模型结构
如图 4 所示,模型的 BackBone 使用 ResNet18 的结构. 该模型使用空洞卷积进行构建,参考 TensorFlow 中 deeplabv3+UNet 结构的方式进行构建. 该结构结合高层和底层特征,同时使用 assp 结构加强对不同尺度特征的特征提取能力. Backbone 输出的特征进行等分切分,得到 2 个通道数相同的特征图. 一个通道图用于送给 Seg-Module 进行服装分割操作得到 seg-result. 同时对于分割得到的特征图,使用 Add-Module 对分割特征图进行累加, 得到服装激活图. 另一个通道图与得到的服装激活图相乘,只保留服装信息,去除背景信息. 然后通过 3D-Module 进行图案色彩信息抹除,并估计出深度信息,得到 clothes 部分. 最后将服装激活图与原始 Input 做异或操作计算得到无服装的 background,将 clothes 与 background 进行叠加操作,得到最后的 3d-result,这里结合 input 的优势是 background 部分是不需要做任何改变的,直接从 input 中获取即可.
该模型的优势之处是将 seg-Module 与 3D-Module 合并在一个结构之中,同时将 seg-Moudle 的输出作为 3D-Module 中可用的信息,加强了信息的流转,分割分支分割的准确率越高对于 3D 分支越有效,同时 3D 分支分割不准确,惩罚也会回传给分割分支,加强分割分支的分割能力,2 个模块相关制约也相互提升.
模型部分使用 TensorFlow 进行构建,ResNet 结构部分直接复用 TensorFlow models 中的结构,assp 结构部分也直接复用了 TensorFlow models 的 deeplab 模型,对于特征分割与特征之间的相乘异或操作也是直接使用 TensorFlow 的内置函数即可完成. 特征分割可以通过 tensorflow.split 函数完成. 随着 TensorFlow 的发展完善,搭建新模型时很多结构可以从 TensorFlow 的官方复现中直接提取使用,当成固定的模块,加速了模型构建速度.
3. 实现
3.1. 数据准备
模型结构为双分支双任务结构,需要的数据为分割数据与 3D 试衣数据,数据形式如下图所示:

图 5. 数据完整标注. 从左往右分别为原图,服装分割标注图,3D 试衣标注图, 3D 试衣标注图的深度通道信息图.
通常来说,对于多分支任务结构一般需要对一张数据进行多种任务属性的标注,但是这样对标注人员的要求过高, 很容易造成标注效率低下与标注精度下降的问题(原因在于标注时需要不断进行切换,切换时会造成不连续问题). 为了加快标注效率与精度,将分割任务与 3D 标注任务进行分离,也就是说单张图可以只有一种标注信息,可以只有分割信息, 也可以只有 3D 试衣信息,这样的好处是不同的标注人员可以专注在一个任务上, 标注精度和标注速度可以大大加快. 因为分割模块的输出嵌入在了 3D 分支之中,所以从整个模型来说,分支模块的性能决定了最终整个系统的上限,所以,对分割分支模块的需求会更高一些,所以在除了使用自己的标注数据之外,还添加了一部分开源的分割数据做为补充.
数据准备完成后,可以使用 TensorFlow 支持的 TFRecords 格式进行数据转换,由于任务是 Img2Img 的任务,每次直接从磁盘进行读取大批次数据消耗时间较长,转换为 TFRecords 后可以大大的加快数据读取的时间. TFRecords 在于其使用二进制存储方式,将数据存储在一个内存块中,相比其他文件格式快很多,数据读取加快降低减少了 IO 时间,GPU 等待数据的时间减短,训练速度提升非常明显.
3.2. 模型训练
标注的数据大部分只有单个标签,同时模型是双分支输出,通常来说,比较普遍的做法是使用轮询的方法进行每个分支的单独训练,类似下图所示:
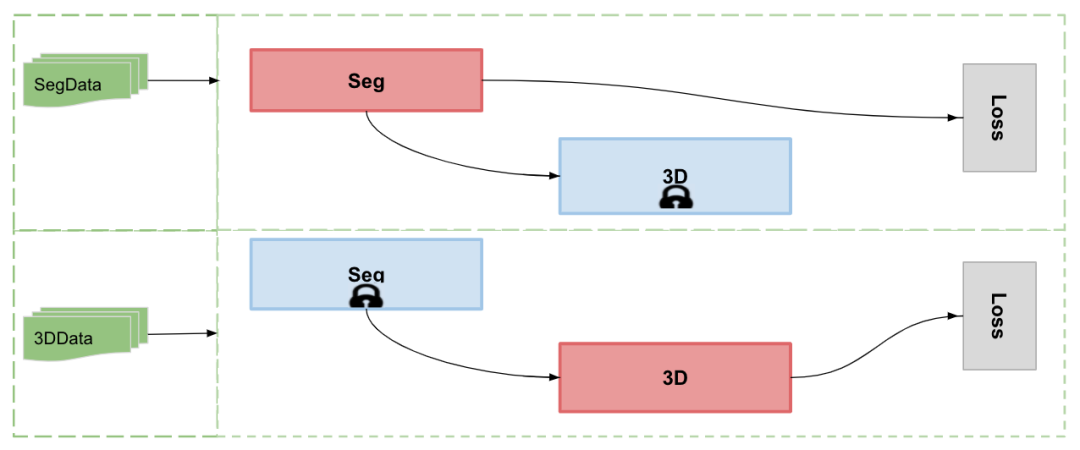
图6. 轮询训练方法
轮询训练方法比较简单,每个批次只需要训练一个分支任务,数据加载与训练结构也很方便,也有不少教程推荐该种方案. 但是这种方案也有一个较大的问题,模型训练过程中 2 个分支单独优化,轮询更新导致 BackBone 参数更新不同步问题,loss 会周期性震荡. 模型最终会慢慢收敛,但是持续的震荡可能会导致模型始终无法训练到最优. 这次对 3D 分支训练时也可以开放 Seg 进行同步训练,相当于 Seg 每次都被训练.
在这里,采用另一种同步训练的方法进行模型的训练,同时对 2 个分支进行训练,训练方法如下图所示:
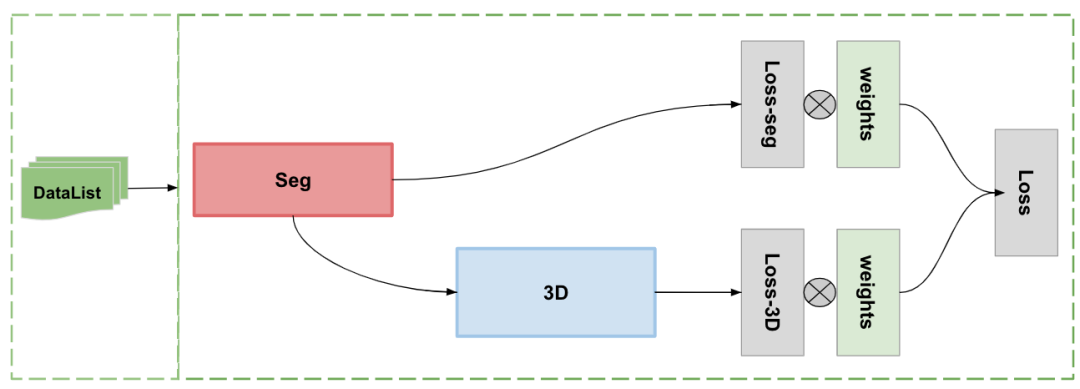
图 7. 同步训练方法
训练过程中每个批次的训练数据从 seg 和 3D 数据随机挑选,比如对于缺失部分,直接构建全 0 向量进行填充,计算loss,根据数据的情况计算 weigths,然后使用 weights 与计算得到的 loss 计算乘积,最后累加 2 个模型的 loss. weights 的统计如下图所示:
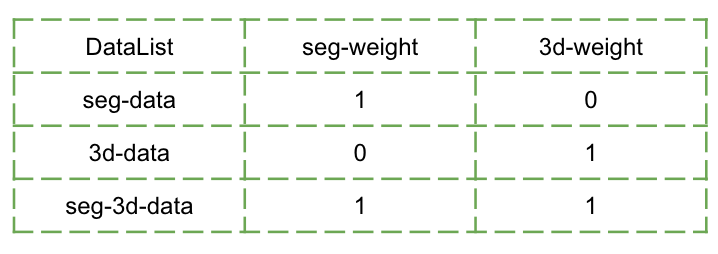
图 8. weights 统计
weights 的统计主要和使用的数据相关,计算分支 loss 时,该分支使用了数据置为1,未使用置为 0.
使用同步训练的方法好处是训练时参数可以同步更新,同步训练 2 个分支参数,此外不同来源的数据可以同时被送入同一个模型,数据分布之间差异造成的模型精度问题可以有一定程度的缓解,这种方法也可以推广到其他多分支结构训练中,根据实验各类任务均可以有较大的性能提升. 除了可以参数同步更新外,同步训练方法可以通过设计不同的采样随机数来控制不同数据出现频率,来优化模型训练.
在模型训练过程中,使用 TensorFlow summary 进行各项训练参数收集,并使用 TensorBoard 进行展示. 使用 tensorflow.summary.image 进行图片的可视化,可以辅助判断模型的实际训练情况与测试情况. 特别是在 img2img 任务中,损失函数与肉眼感官还是存在一定差距.
3.3. 使用GAN进行优化训练
在 3.2 中,已经可以训练得到一个不错的多任务模型,同时可以完成分割任务和 3D 试衣任务,但是从数据的角度来看,数据之间始终是分开进行训练,没有良好的进行协作,如何将数据联合起来一起进行训练,这边比较好的一个思路即是使用 GAN 的方法来进行一个监督训练,训练方法如下图所示: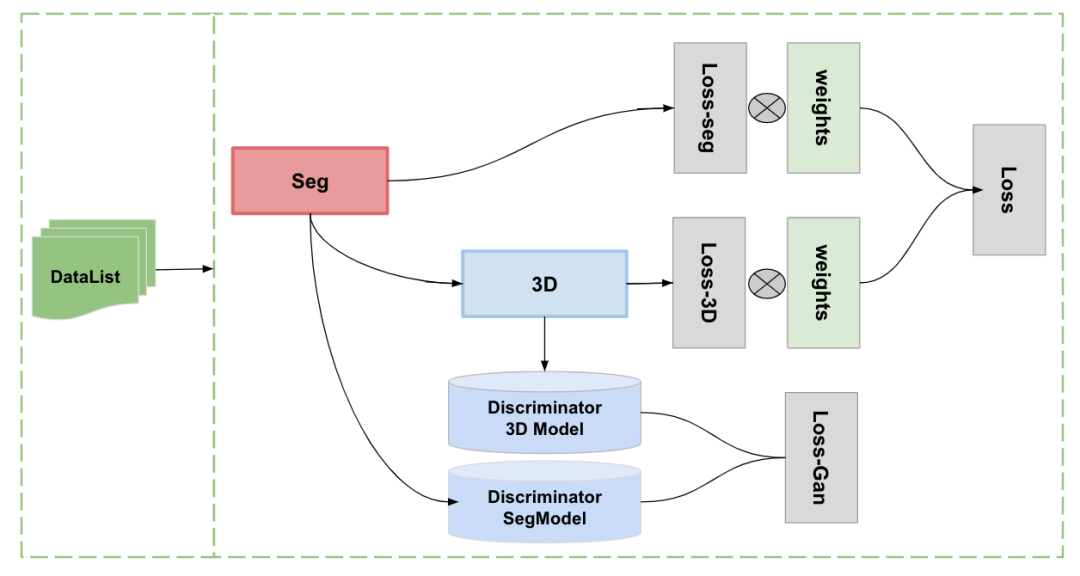
图 9. 判别监督进行训练
如上图所示,除了基础的训练 loss 外,同时 GAN-Loss 作为监督来进行训练,这边主要是增加 2 个判别模型,3D 试衣判别模型和服装分割判别模型,判别模型工作原理如下图所示:
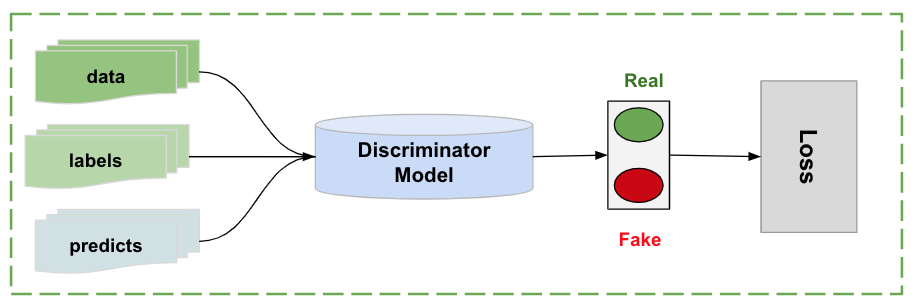
图 10. 判别模型工作原理
判别模型这边可以使用任意结构作为 backbone,主要工作是对 data-labels、data-predicts 进行真假判别,然后将真假 loss 回传,训练过程中,判别器与 3D 试衣模型交替训练,相互进行模型的不断强化,最终达到平衡状态. 使用对抗学习作为一个监督模块训练的好处是可以将数据联合使用起来,提高整个模型的性能,坏处是对抗学习需要的工程能力与模型训练参数调整能力要求较高,这里一般建议先将 3D 试衣模型训练到一个较好的状态了再添加判别器模块微调.
此处进行 GAN 的 BackBone 模型使用 TensorFlow models中实现的 VGG16 结构,并重载了 VGG16 的参数,同时使用服装数据进行了预训练,预训练目的是加强判别模型对服装特征的提取能力. 此外除了进行 real/fake 的 loss 训练外,还可以将 VGG16 中的特征进行抽取,计算 real/fake 之间的特征图的差异,并作为 loss 进行回传.
4. 效果展示
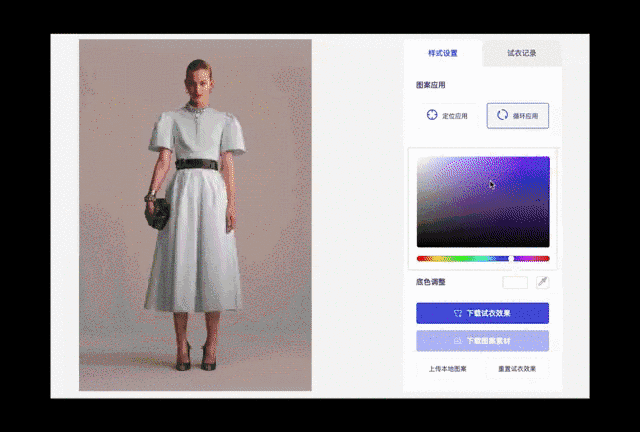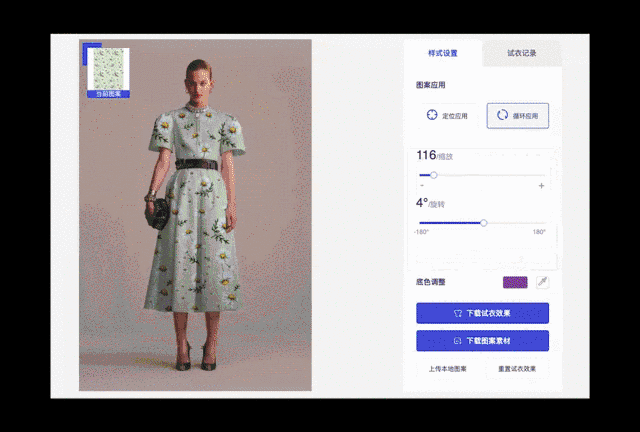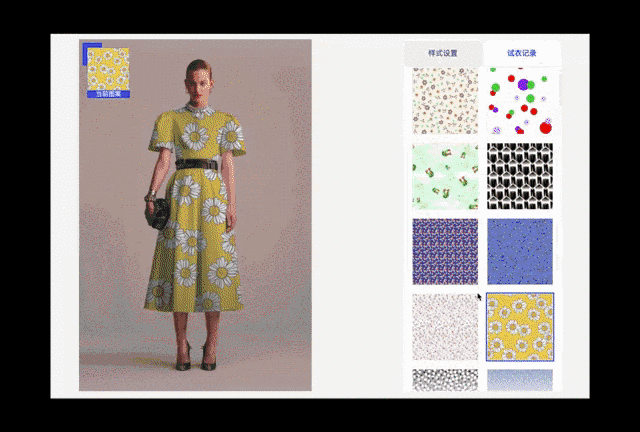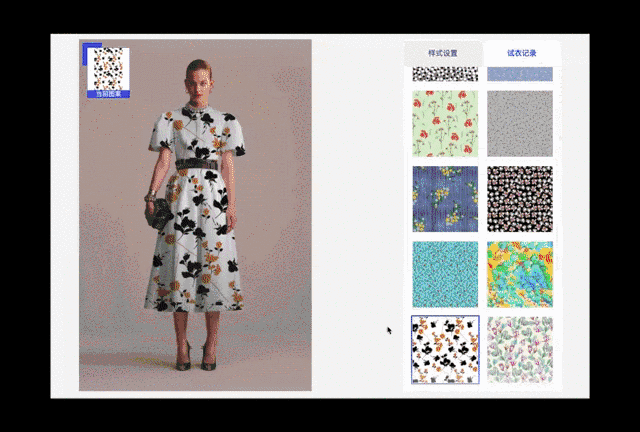
图11. 裙装颜色更换与图案更换
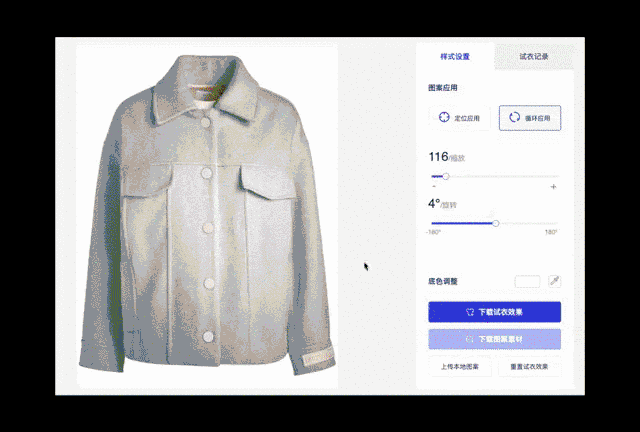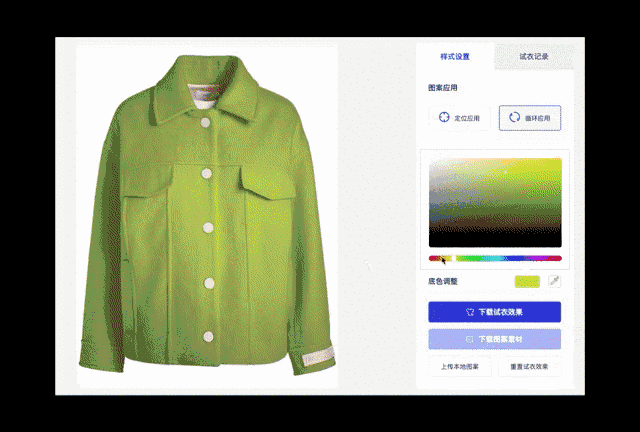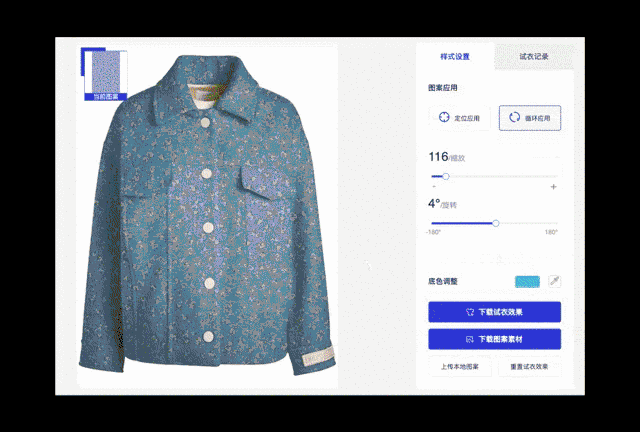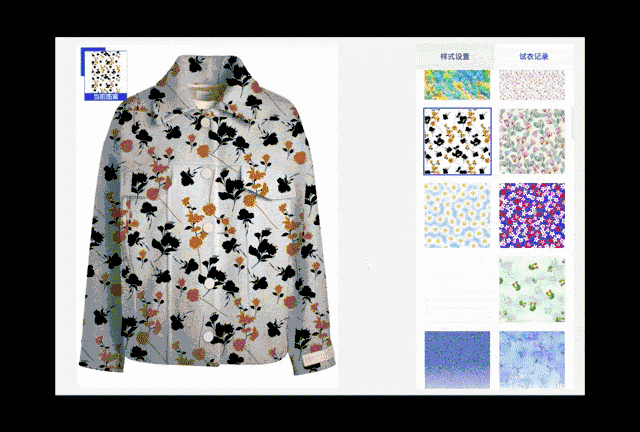
图 12. 夹克颜色与图案更换

图 13. 上下装颜色单独切换

图 14. 替换裙装中的原始图案
5. 总结
本文从服装行业中的设计问题出发,分析了服装设计中的痛点,并逐步进行问题分解,方案提出,采用技术的手段进行问题的解决. 在技术实现中,进行了多角度的问题查找定位与方案解决,目前的方案中已经帮助解决了了核心痛点,后续还会继续帮助收集 3D 试衣系统中的更多问题,并逐步解决. 在模型构建中越发成熟的 TensorFlow 提供了较多帮助,越来越多的官方实现提供了大量的基础模块用于使用,大大加快了基础模型构建速度与业务落地速度,TensorFlow Summary 对实验过程中间结果的可视化也提供了很多训练帮助,也希望后期 TensorFlow 提供更多更好用的基础模块.
本文提出了模型解决与训练策略均在实际中落地并取得了不凡的效果,也希望这些方法能给大家带来更多的启发,后续也会带来更多关于智能设计的技术分享.
知衣科技是一家致力于应用图像技术、时序分析、个性化推荐等人工智能技术为服装行业客户提供最新最前沿数据分析服务的公司,人工智能技术是知衣科技的基因,知衣科技希望通过不断的技术创新,为服装行业客户带来更好的智能服务.