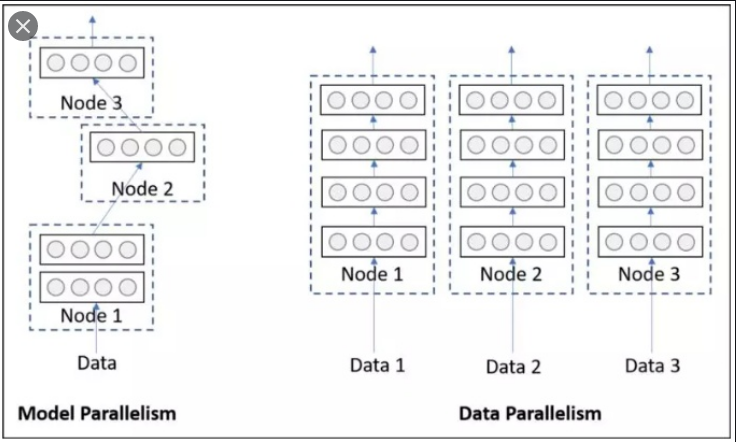
单卡多级的模型训练,即并行训练,可分为数据并行和模型并行两种.
数据并行是指,多张 GPUs 使用相同的模型副本,但采用不同 batch 的数据进行训练.
模型并行是指,多张 GPUs 使用同一 batch 的数据,分别训练模型的不同部分.
如图:
1. DataParallel 简述
pytorch 默认只用一个 GPU,但采用 DataParallel很便于使用多 GPUs 的.
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "1,2"
# 注: 多卡训练时,默认将 model 和 data 先保存到 id:0 的卡上(这里是第1块卡)
# 然后 model 的参数再复制共享到其他卡上;
# data 也会平分为 subbatch 到其他卡上.
# 故:一般第一张卡显存占用多点.
device = torch.device("cuda:0")
# 1.将模型放到 GPU 上
device_ids = [0, 1] #必须从零开始(这里0表示第1块卡,1表示第2块卡.)
model = nn.DataParallel(model, device_ids=device_ids)
model.to(device)
# 2.将id:0 卡数据平分到其他卡.
data.to(device)注:data.to(device) 返回 data 在 GPU 上的一份副本,而不是重写 data.
2. nn.DataParallel 函数
class torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0)[1] - module :待进行并行的模块.
[2] - device_ids : GPU 列表,其值可以是 torch.device 类型,也可以是 int list. 默认使用全部 GPUs.
[3] - output_device : GPUID 或 torch.device. 指定输出的 GPU,默认为第一个,即 device_ids[0].
3. DataParallel 原理
pytorch 单机多卡的基本原理如下.
假设读入一个 batch 的数据,其大小为 [30, 5, 2],假设采用三张 GPUs,其运行过程大致为:
[1] - 将模型放到主 GPU 上,一般为 cuda:0;
[2] - 把模型同步到 3 张 GPUs 上;
[3] - 将总输入 batch 的数据平分为 3 份,这里每一份大小为 [10, 5, 2];
[4] - 依次分别作为每个副本模型的输入;
[5] - 每个副本模型分别独立进行前向计算,假设为 [4, 5, 2];
[6] - 从 3 个 GPUs 中收集分别计算后的结果,并按照次序拼接,即 [12, 5, 2],计算 loss;
[7] - 更新梯度,后向计算.
模型同步 - 数据分发 - 分别前向计算 - loss 计算 - 梯度反传.
4. 官方示例
https://pytorch.org/tutorials/beginner/blitz/data_parallel_tutorial.html
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
# Parameters and DataLoaders
input_size = 5
output_size = 2
batch_size = 30
data_size = 100
# Device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Dummy Dataset
class RandomDataset(Dataset):
def __init__(self, size, length):
self.len = length
self.data = torch.randn(length, size)
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return self.len
# dataloader
rand_loader = DataLoader(dataset=RandomDataset(input_size, data_size),
batch_size=batch_size, shuffle=True)
# demo model - linear operation
class Model(nn.Module):
def __init__(self, input_size, output_size):
super(Model, self).__init__()
self.fc = nn.Linear(input_size, output_size)
def forward(self, input):
output = self.fc(input)
print("\tIn Model: input size", input.size(),
"output size", output.size())
return output
# 单机多卡
# 1. 采用 nn.DataParallel 封装模型;
# 2. 采用 mode.to(device) 将模型放于多块 GPUs 上.
model = Model(input_size, output_size)
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
# dim = 0 [30, xxx] -> [10, ...], [10, ...], [10, ...] on 3 GPUs
model = nn.DataParallel(model)
model.to(device)
# 模型运行
# 查看 input tensors 和 output tensors 的sizes.
for data in rand_loader:
input = data.to(device)
output = model(input)
print("Outside: input size", input.size(),
"output_size", output.size())[1] - 对于没有 GPU 或者只有一个 GPU时,当batchsize 为 30 个 inputs 和 30 个 outputs 时,模型也会得到 30 个 inputs 和 30 个 outputs.
[2] - 两块 GPUs 的输出如:
# on 2 GPUs
Let's use 2 GPUs!
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([5, 5]) output size torch.Size([5, 2])
In Model: input size torch.Size([5, 5]) output size torch.Size([5, 2])
Outside: input size torch.Size([10, 5]) output_size torch.Size([10, 2])[3] - 三块 GPUs 的输出如:
Let's use 3 GPUs!
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
Outside: input size torch.Size([10, 5]) output_size torch.Size([10, 2])[4] - 8 块 GPUs 的输出如:
Let's use 8 GPUs!
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
Outside: input size torch.Size([10, 5]) output_size torch.Size([10, 2])5. DistributedDataPrallel
pytorch官网建议使用DistributedDataParallel来代替DataParallel, 据说是因为DistributedDataParallel比DataParallel运行的更快, 然后显存分屏的更加均衡. 而且DistributedDataParallel功能更加强悍, 例如分布式的模型(一个模型太大, 以至于无法放到一个GPU上运行, 需要分开到多个GPU上面执行). 只有DistributedDataParallel支持分布式的模型像单机模型那样可以进行多机多卡的运算.
分布式训练与单机多卡的区别:
[1] - DataLoader部分需要使用Sampler,保证不同GPU卡处理独立的子集.
[2] - 模型部分使用DistributedDataParallel.
主要代码如:
from torch.utils.data import Dataset, DataLoader
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel
RANK = int(os.environ['SLURM_PROCID']) # 进程序号,用于进程间通信
LOCAL_RANK = int(os.environ['SLURM_LOCALID']) # 本地设备序号,用于设备分配.
GPU_NUM = int(os.environ['SLURM_NTASKS']) # 使用的 GPU 总数.
IP = os.environ['SLURM_STEP_NODELIST'] #进程节点 IP 信息.
BATCH_SIZE = 16 # 单张 GPU 的大小.
def dist_init(host_addr, rank, local_rank, world_size, port=23456):
host_addr_full = 'tcp://' + host_addr + ':' + str(port)
torch.distributed.init_process_group("nccl", init_method=host_addr_full,
rank=rank, world_size=world_size)
torch.cuda.set_device(local_rank)
assert torch.distributed.is_initialized()
if __name__ == '__main__':
dist_init(IP, RANK, LOCAL_RANK, GPU_NUM)
# DataSet
datasampler = DistributedSampler(dataset, num_replicas=GPU_NUM, rank=RANK)
dataloader = DataLoader(dataset, batch_size=BATCH_SIZE, sampler=datasampler)
# model
model = DistributedDataPrallel(model,
device_ids=[LOCAL_RANK],
output_device=LOCAL_RANK)6. Github - 不同加速库使用示例(单机多卡)
出处:https://github.com/tczhangzhi/pytorch-distributed/blob/master/README.md
使用 PyTorch 编写了不同加速库在 ImageNet 上的使用示例(单机多卡).
[1] - nn.DataParallel 简单方便的 nn.DataParallel
[2] - torch.distributed 使用 torch.distributed 加速并行训练
[3] - torch.multiprocessing 使用 torch.multiprocessing 取代启动器
[4] - apex 使用 apex 再加速
[5] - horovod horovod 的优雅实现
这里记录了使用 4 块 Tesla V100-PICE 在 ImageNet 进行了运行时间的测试,测试结果发现 Apex 的加速效果最好,但与 Horovod/Distributed 差别不大,平时可以直接使用内置的 Distributed. Dataparallel 较慢,不推荐使用.

7. 参考资料
[1] - Pytorch 单机并行训练 - 知乎
[2] - Github - tczhangzhi/pytorch-distributed
[3] - pytorch多gpu并行训练 - 知乎
[4] - Pytorch多机多卡分布式训练 - 知乎
[5] - Pytorch多机多卡 - Aitical