原文:如何用深度学习框架PaddlePaddle实现智能春联 - 2019.01.30
作者:PaddlePaddle
1. 引言
不知不觉春节假期马上到来,在今年的春节话题中,不难发现,除了七大姑八大姨亲切问候这些常规话题,人工智能的踪迹也是随处可见. AI在以全新的面貌向我们展示值得期待的未来,比如,可以用PaddlePaddle来尝试写副智能春联.
过年贴春联已经成为一个传统习俗,而商场里可选的内容不多,很多人想亲自出马,可惜又不大懂平仄对仗. 能不能用人工智能帮我们写春联呢?今年春节,百度、网易和央视网推出了“智能春联H5”,只要给出2-4个汉字,它就能据此“写”出一副非常具有观赏性的藏头春联.
是什么让机器拥有对春联这项技能?
通过智能春联H5,“刷脸”对春联只需几秒就能实现,而这背后是一系列“不可描述”的高深技术. 视觉方面,主要应用了人脸检测、属性分析、人脸融合等技术,可对图片中的人脸进行检测,分析人脸对应的年龄、性别、颜值、微笑指数、是否佩戴眼镜等信息,并通过一个词语概括人脸的特性;进而将图片中的人脸,与指定模板图中的人脸进行融合,得到新的图片. 这些技术的难度在于,需要对各种角度的人脸进行检测,并且能够提取人脸的五官特征,以便能够生成与原始人脸相似,但也和模板人脸神似,且毫无违和感的新图片.
其次是自然语言处理(NLP)方面,基于百度深度学习框架PaddlePaddle先进的神经网络机器翻译技术,可以将春联创作转化为“翻译”的过程,所不同的是,翻译是在两种语言之间建立联系,而春联是在同一种语言中建立联系. 当然,有些人可能会中招“彩蛋”,这些不是AI写的春联. 比如你刷脸得出“戏精”这个关键词,就会获得一副“流量体质天生有戏,主角光环盖不住你”,横批“过足戏瘾”的春联,这么霸气十足可是由人工专门为你埋的梗哦!这样的春联出现在朋友圈里,毫无疑问,点赞人数会疯狂UpUpUp……
PaddlePaddle作为深度学习框架,不仅支持深度学习算法的开发和调研,而且官方发布的模型库(https://github.com/PaddlePaddle/models)里面汇集了各种领先的图像分类、自然语言处理算法. 通过这些算法,我们可以很方便地实现各种好玩有趣的功能,比如:智能春联.
智能春联有各种玩法,可以根据用户输入的关键词,生成一副对联,实现定制化的专属春联,比如:输入“好运”,百度的人工智能春联生成程序就会创作出上下联为“一年好运满园锦绣,万众同心遍地辉煌”、横批为“春光满园”的春联;用户输入自己的名字,智能春联生成程序可以把自己的名字藏在生成的春联中,形成个性化非常强的春联,用来发送给自己的朋友;甚至用户不需要输入关键词,只需要拍一张照片,然后就可以根据这张照片生成图文并茂的春联. 那这些功能都是怎么做到的呢?这里介绍一下如何用PaddlePaddle开发一套专属的智能春联生成系统.
2. 图像内容理解
智能春联生成系统需要先做到能理解图像的内容,比如:用户输入的到底是什么?
这是一个典型图像分类的问题,图像分类是根据图像的语义信息对不同类别图像进行区分,是计算机视觉中重要的基础问题,是物体检测、图像分割、物体跟踪、行为分析、人脸识别等其他高层视觉任务的基础,在许多领域都有着广泛的应用.
在深度学习时代,图像分类的准确率大幅度提升,PaddlePaddle在经典的数据集ImageNet上,开放了常用的模型,包括AlexNet、VGG、GoogLeNet、ResNet、Inception-v4、MobileNet、DPN(Dual Path Network)、SE-ResNeXt模型,同时也开源了训练的模型方便用户下载使用.
基于这些图像分类算法,可以知道用户输入的类别,用类似的技术,还可以知道一些更具体的属性,比如:对于一张人脸的照片,可以知道性别、年龄这些属性.
有了图片的这些特征和属性之后,就可以进行关键词扩展. 比如:对于年轻的女性可以联想出一些关键词“风华绝代”、“秀丽”、“端庄”等等,对于小孩可以联想出关键词“活泼可爱”、“机智”、“勇敢”等等.
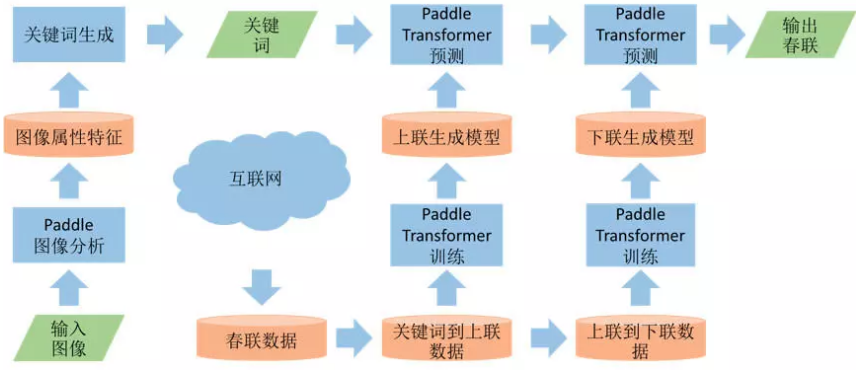
3. 关键词转换
拿到这些关键词之后,接下来的任务是什么?
根据一个关键词,自动生成一副相关的春联.
春联的生成过程可以分成2个步骤,第一个步骤是从关键词生成一副上联. 然后再根据上联生成一副下联.
那么如何实现这2个生成步骤呢?我们发现这个任务跟机器翻译很相似,可以用类似的技术来实现. 机器翻译(Machine Translation, MT)是用计算机来实现不同语言之间翻译的技术. 被翻译的语言通常称为源语言(Source Language),翻译成的结果语言称为目标语言(Target Language). 机器翻译即实现从源语言到目标语言转换的过程,是自然语言处理的重要研究领域之一.
PaddlePaddle的模型库(PaddlePaddle/models)里面,提供了两个机器翻译算法的实现,一个是经典的基于LSTM的Seq2Seq模型,另一个是最新的基于Attention的Transformer模型.
类比于机器翻译任务,可以把智能春联输入的关键词看作是机器翻译里的源语言句子,然后把根据关键词生成的上联,看作是机器翻译里的目标语言译文. 相较于此前 Seq2Seq 模型中广泛使用的循环神经网络(Recurrent Neural Network, RNN),使用(Self)Attention 进行输入序列到输出序列的变换主要具有以下优势:计算复杂度更小、计算并发度更高、更容易学到长距离的依赖关系.
推荐使用翻译效果更好的Transformer模型,通常Transfomer可以得到比Seq2Seq更好的翻译效果.
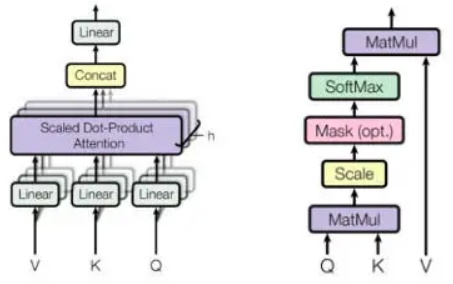
图. Transformer模型核心组件Multi-Head Attention
Scaled Dot-Product Attention的PaddlePaddle代码实现:
def scaled_dot_product_attention(q, k, v, attn_bias, d_key, dropout_rate):
"""
Scaled Dot-Product Attention
"""
scaled_q = layers.scale(x=q, scale=d_key**-0.5)
product = layers.matmul(x=scaled_q, y=k, transpose_y=True)
if attn_bias:
product += attn_bias
weights = layers.softmax(product)
if dropout_rate:
weights = layers.dropout(
weights,
dropout_prob=dropout_rate,
seed=ModelHyperParams.dropout_seed,
is_test=False)
out = layers.matmul(weights, v)
return out4. 春联生成
选定了使用的生成算法之后,如何让机器能够学会写春联呢?
接下来就需要给系统准备训练数据了,所谓“熟读唐诗三百首”,对于机器来说,需要见到大量的春联,才能够学会春联里用词和用字的规律. 可以去互联网上找到大量的春联数据,比如:“爆竹传吉语”“腊梅报新春”等等,然后把它们作为训练数据,通常需要几万条.
有了这些数据后,从上联里抽取出关键词,“爆竹”-> “爆竹传吉语”,训练一个从关键词到上联的生成模型;然后再用“爆竹传吉语”“腊梅报新春”训练一个从上联到下联的生成模型.
准备好训练数据后,就可以启动Transformer模型的训练了,可以参考PaddlePaddle/models/neural_machine_translation/transformer 里的命令. 这个是英德翻译的例子,在做关键词到上联的生成时,需要把训练数据替换成“关键词”到对应“春联上联”的数据;在做上联到下联生成时,需要把训练数据替换成“春联上联”到对应“春联下联”的数据.
python -u train.py \
--src_vocab_fpath gen_data/wmt16_ende_data_bpe/vocab_all.bpe.32000 \
--trg_vocab_fpath gen_data/wmt16_ende_data_bpe/vocab_all.bpe.32000 \
--special_token '<s>''<e>''<unk>' \
--train_file_pattern gen_data/wmt16_ende_data_bpe/train.tok.clean.bpe.32000.en-de \
--token_delimiter ' ' \
--use_token_batch True \
--batch_size 4096 \
--sort_type pool \
--pool_size 200000练完成后就可以得到一个关键词到上联的生成模型,还有一个从上联到下联的生成模型. 注意生成过程,需要执行2次Transformer的预测过程,先输入一个关键词,生成上联;然后输入生成的上联,再生成一个下联. 具体生成参考以下命令.
python -u infer.py \
--src_vocab_fpath gen_data/wmt16_ende_data_bpe/vocab_all.bpe.32000 \
--trg_vocab_fpath gen_data/wmt16_ende_data_bpe/vocab_all.bpe.32000 \
--special_token '<s>''<e>''<unk>' \
--test_file_pattern gen_data/wmt16_ende_data_bpe/newstest2016.tok.bpe.32000.en-de \
--token_delimiter ' ' \
--batch_size 32 \
model_path trained_models/iter_100000.infer.model \
beam_size 4 \
max_out_len 255根据以上PaddlePaddle官方模型库提供的一些技术,就可以实现一个好玩的智能春联系统了. 当然还可以做很多有意思的扩展,比如,可以增加一些古诗词作为训练语料,使得生成的春联内容更为丰富;藏头春联,把关键词按字分开,通过Grid Beam Search的技术,保证生成的关键词会在春联特定的位置出现.
收集好春联训练语料,便可实现一个好玩的智能春联系统.