题目: Deep Learning of Binary Hash Codes for Fast Image Retrieval - CVPR2015
作者: Kevin Liny, Huei-Fang Yangy, Jen-Hao Hsiaoz, Chu-Song Cheny
团队: Academia Sinica, Yahoo (Taiwan)
1. 摘要
- 针对图像检索问题,提出简单有效的监督学习框架
- CNN网络结构能同时学习图像特征表示以及 hash-like 编码函数集合
- 利用深度学习以逐点(point-wise)的方式,得到二值哈希编码(binary hash codes),以快速检索图像;对比卷积 pair-wised方法,在数据大小上具好的扩展性.
- 论文思想,当数据标签可用时,可以利用隐层来学习能够表示图像类别标签的潜在语义的二值编码
2. 方法
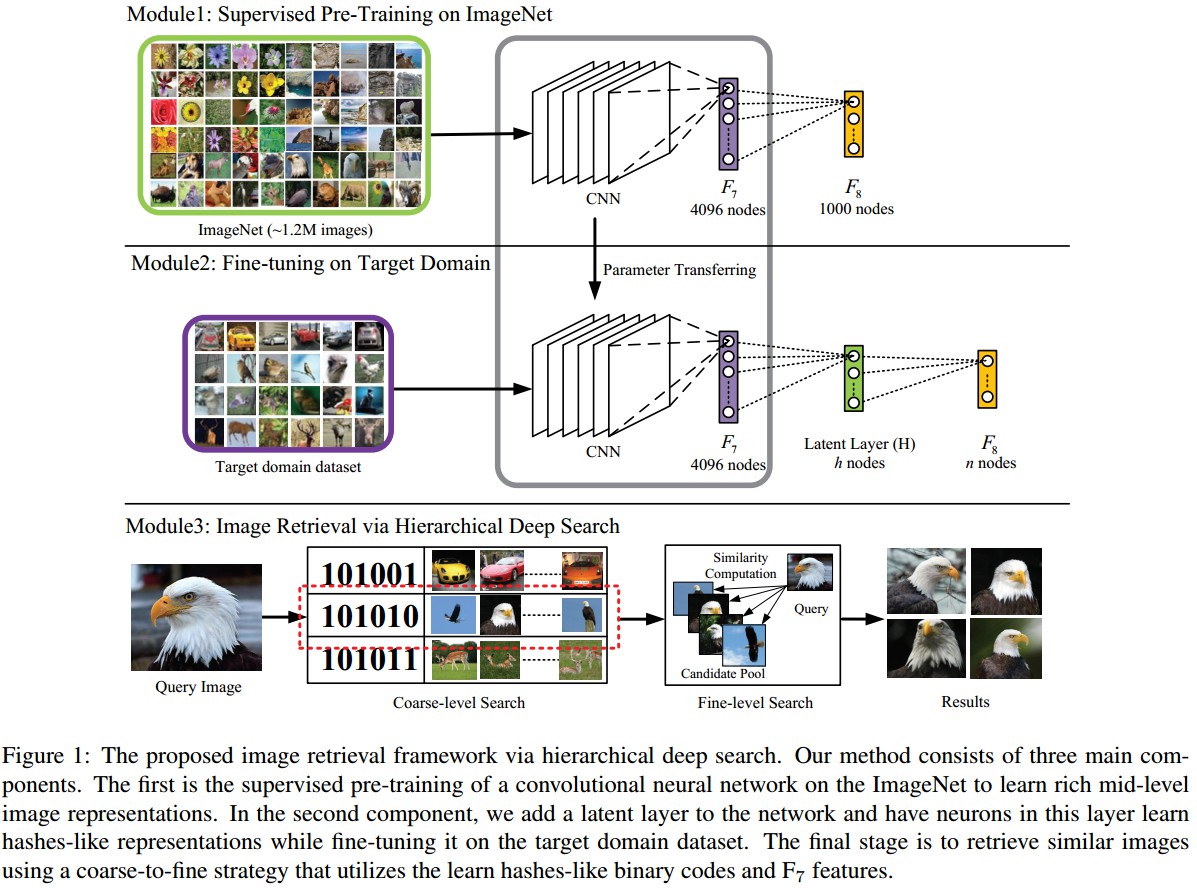
Figure 1: 基于分层深度搜索的图像检索框架.
方法主要包括三部分:
- Module1 - 在ImageNet上有监督地预训练CNN网络,以学习得到丰富的mid-level图像表示特征;
- Module2 - 添加隐层(latent) 网络层,通过在目标图像数据集finetuning网络,该隐层可以学习得到图像的 hashes-like 编码表示;
- Module3 - 利用 hashes-like 二值编码和 F7 层特征,采用 coarse-to-fine 策略检索相似图片.
2.1 Hash-like 二值编码学习
假设网络的最终输出分类层 F8 依赖于 h 个hidden attributes,各属性是 0 或 1(0表示不存在,1表示存在). 如果图像的二值激活编码相似,其应该具有相同标签.
如Figure 1所示,这里在 F7 和 F8 层间嵌入一个隐层 H.
- 该隐层 H 是一个全连接层,其神经元激活情况由后面的 F8 层来控制,F8 层编码了图像语义并用于最终分类.
- 该隐层 H 不仅提供了 F7 层丰富特征的抽象表示,还联系着 mid-level 特征和 high-level 语义.
- 该隐层 H 采用的是Sigmoid 函数,以使激活值在 {0, 1} 之间.
为了适应数据集,在目标数据集 fine-tune CNN网络.
- 初始权重设为ImageNet数据集预训练的CNN权重;
- 隐层$H$和最终分类层 F8 的权重采用随机初始化.
无需对深度CNN模型修改太多,即可同时学习得到图像的视觉特征描述子,和 hashing-like 函数,以进行有效的图像检索.
2.2 基于分层深度搜索的图像检索
采用 coarse-to-fine 搜索策略进行快速精确的图像检索.
- 首先,检索得到相似 high-level 语义特征的候选图片集,即,具有隐层得到隐含二值激活值想死;
- 然后,进一步过滤具有相似外表的图片,主要是基于最深的 mid-level 图像特征表示进行相似性排名.
2.2.1 Coarse-level 搜索
给定图像 ${ I }$, 首先提取隐层输出作为图像特征,记为 ${ Out(H) }$. 通过设定阈值,即可以得到其二值编码. 即,对于二值激活的每一个字节${ j=1,2,...,h }$ ( h 为隐层的节点数), H的输出二值编码:
${if \ Out^j(H)\geq 0.5, H^j = 1 }$
${if \ Out^j(H) < 0.5, H^j = 0}$
记 ${ \Gamma = {I_1, I_2,...,I_n} }$ 表示用于检索的 ${ n }$张图片组成数据集,其每张图片对应的二值编码记为${ \Gamma _H = {H_1, H_2,...,H_n} }$ , 其中 ${ H_i \in {0,1}^h }$.
给定待查询图片 ${ I_q }$ 及其二值编码 ${ H_q }$, 如果 ${ H_q }$ 和 ${ H_i \in \Gamma_H }$ 的Hamming 距离小于阈值,得到一个有 m 张候选图片的图片池,${ P = { I_1^c, I_2^c,...,I_m^c } }$.
2.2.2 Fine-level 检索
给定待查询图片 ${ I_q }$ 及候选图片池 ${ P = { I_1^c, I_2^c,...,I_m^c } }$,采用 F7 层提取的图片特征来从候选图片池 ${ P }$ 中确认前 ${ k }$ 张图片.
记 ${ V_q }$ 和 ${ V_i^P }$ 分别表示待查询图片 ${ q }$ 和图片池中候选图片 ${ I_i^c }$ 的特征向量,则其欧氏距离相似性计算为:
${ s_i = || V_q- V_i^P|| }$
如果欧氏距离越大,则两张图片的相似性越强. 通过对候选图片进行排序,即可得到最终的检索图片.
3. 实验结果
3.1 数据集
- MNIST Dataset - 10类手写数字,0~9,共 60000张训练图片,10000测试图片,每张数字图片都归一化为 28×28 的灰度图片.
- CIFAR-10 Dataset - 10类物体,每一类有 6000 张图片,一种60000张图片,其中50000张作训练,10000张作测试.
- Yahoo-1M Dataset - 一共1124087张商品图片,116类服装类别,如 TOP,Dress,Skirt等. 如Figure2.

3.2 检索结果



