原文:Building a book Recommendation System using Keras
作者:Gilbert Tanner
翻译:王逍遥、孙稚昊2、UPDATA
校对:就2
整理:菠萝妹
<Github - RecommendationSystem>
推荐系统试图依据用户旧物品评级或偏好来预测对某一物品的评级或偏好.
为了提高服务质量,几乎每个大公司都使用推荐系统.
本文将研究如何使用Embedding来创建图书推荐系统.
数据采用的是 goodbooks-10k 数据集(From Kaggle),其包含1万种不同的图书和大约100万个评级,共有三个特征: book_id、user_id 和评级(rating).

图 1: Photo by Brandi Redd on Unsplash
1. Embedding
嵌入(Embedding) 是一种映射,从离散的对象(如单词或本文的图书id) 到连续值向量的映射. 这可以用来发现离散对象之间的相似性,如果不使用嵌入层,模型就不会发现这些相似性.
嵌入向量是低维的并且在训练网络时得到更新. 下图显示了使用谷歌开源的高纬数据可视化 Tensorflows Embedding Projector 创建的嵌入示例.
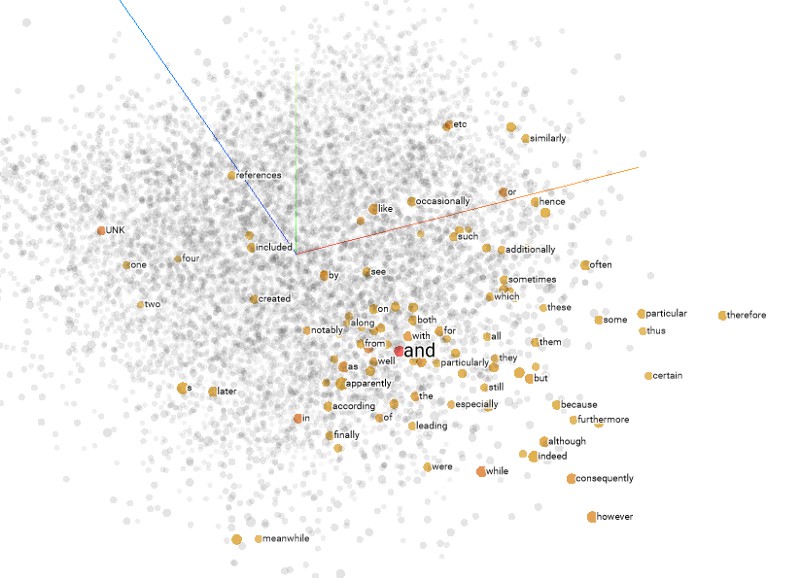
Figure 2: Projector Embeddings
2. 获取数据
下载数据后,首先使用 Pandas加载数据集. 并将数据集拆分为训练集和测试集. 将创建两个变量,分别用来存储去重后的用户id 和 书籍id (并不是用户数量).
dataset = pd.read_csv('ratings.csv')
train, test = train_test_split(dataset, test_size=0.2, random_state=42)
n_users = len(dataset.user_id.unique())
n_books = len(dataset.book_id.unique())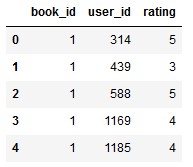
Figure 3: Rating-Dataset Head
数据集已经被清洗过,所以无需再做更多的数据清洗或者数据预处理的步骤.
3. 建立嵌入模型
使用Keras 深度学习框架,可以很容易地创建神经网络嵌入模型,以及处理多个输入和输出层.
模型包含如下结构:
[1] - 输入:包括书和用户
[2] - 嵌入层:书和用户的嵌入
[3] - 点乘:使用点乘来合并各个嵌入向量
在一个嵌入模型中,嵌入的权重要在训练中学习得到. 这些嵌入不仅能用来从数据中提取信息,它们本身也可以被提取或者可视化.
为了简单起见,不在模型最后加上全连接层,虽然加上全连接层可以提高不少准确率. 如果想要更精确的模型,可以加上试试.
下面是创建模型的代码:
from keras.layers import Input, Embedding, Flatten, Dot, Dense
from keras.models import Model
# [1] - 输入 & 嵌入层
book_input = Input(shape=[1], name="Book-Input")
book_embedding = Embedding(n_books, 5, name="Book-Embedding")(book_input)
book_vec = Flatten(name="Flatten-Books")(book_embedding)
user_input = Input(shape=[1], name="User-Input")
user_embedding = Embedding(n_users, 5, name="User-Embedding")(user_input)
user_vec = Flatten(name="Flatten-Users")(user_embedding)
# [2] - 点乘
prod = Dot(name="Dot-Product", axes=1)([book_vec, user_vec])
model = Model([user_input, book_input], prod)
model.compile('adam', 'mean_squared_error')4. 训练模型
创建好模型后,准备训练模型.
由于模型包含两个输入层(一个是书籍输入,一个是用户输入),需要将训练集组合成一个数组作为 x 输入.
本文对模型训练了 10 epochs,如果想得到更好的结果,可以训练更长的时间.
训练代码如下:
history = model.fit([train.user_id, train.book_id],
train.rating,
epochs=10,
verbose=1)
model.save('regression_model.h5')5. 可视化嵌入
嵌入可以被用来可视化一些概念,比如不同书之间的关系.
为了可视化这些概念,需要降低向量维度. 可以采用一些降维算法,如 主成分分析(PCA),或, t-SNE
从 10000 维开始(每一维是一本书),通过嵌入模型,降低到 5 维,再通过 PCA 或 t-SNE 降维到 2 维.
首先,用 get_layer 函数来提取嵌入:
# Extract embeddings
book_em = model.get_layer('Book-Embedding')
book_em_weights = book_em.get_weights()[0]然后,采用PCA来把嵌入转化为2维向量,并用Seaborn把结果可视化为散点图:
from sklearn.decomposition import PCA
import seaborn as sns
pca = PCA(n_components=2)
pca_result = pca.fit_transform(book_em_weights)
sns.scatterplot(x=pca_result[:,0], y=pca_result[:,1])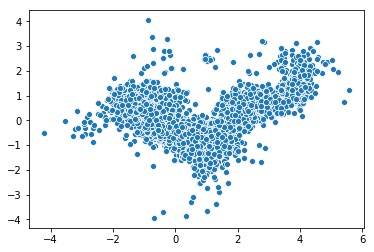
Figure4: 用PCA来可视化嵌入
也可以用 t-SNE 方法.
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, verbose=1, perplexity=40, n_iter=300)
tnse_results = tsne.fit_transform(book_em_weights)
sns.scatterplot(x=tnse_results[:,0], y=tnse_results[:,1])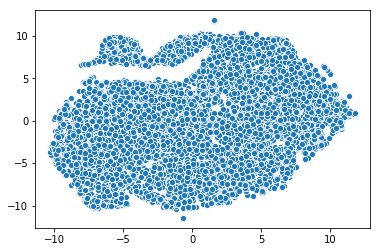
Figure 5: 用t-SNE可视化嵌入
6. 进行推荐
采用训练模型进行推荐很简单. 只需要输入一个用户和所有图书,然后选择对该特定用户具有最高预测评级的图书.
对特定用户进行预测的实现代码如下:
# Creating dataset for making recommendations for the first user
book_data = np.array(list(set(dataset.book_id)))
user = np.array([1 for i in range(len(book_data))])
predictions = model.predict([user, book_data])
predictions = np.array([a[0] for a in predictions])
recommended_book_ids = (-predictions).argsort()[:5]
print(recommended_book_ids)
print(predictions[recommended_book_ids])代码输出如下:
array([4942, 7638, 8853, 9079, 9841], dtype=int64)
array([5.341809 , 5.159592 , 4.9970446, 4.9722786, 4.903894 ], dtype=float32)导入图书 csv ,得到更多的信息
books = pd.read_csv(‘books.csv’)
books.head()
print(books[books[‘id’].isin(recommended_book_ids)])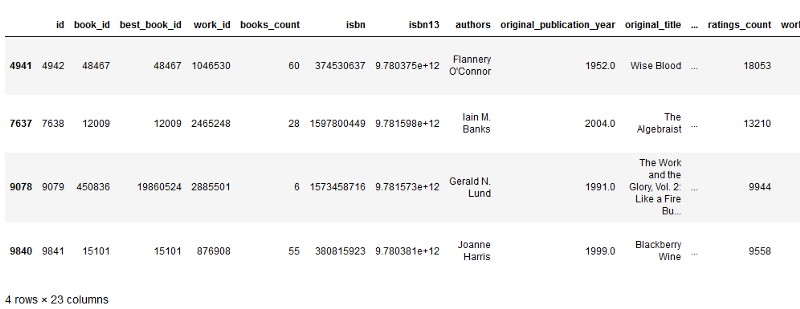
7. 总结
嵌入是一种把离散的物体,比如单词,转化为连续值向量的方法.
嵌入对寻找物体相似度,可视化等目标很有帮助,并且可以用来做另一个机器学习模型的输入.
这个例子肯定不是完美的,有很多方法可以被尝试来提高准确率. 但对于高级的问题,用嵌入来学习输入是一个好的出发点.
下面的方法可以得到更好的结果:
- 在点乘后加入全连接层
- 训练更多轮
- 对评分列做归一化
- 等等......