作者:lbin
PyTorch 1.0稳定版终于正式发布了!
新版本增加了JIT编译器、全新的分布式包、C++ 前端,以及Torch Hub等新功能,支持AWS、谷歌云、微软Azure等云平台.
1. DISTRIBUTED NEWS
torch.distributed 软件包和 torch.nn.parallel.DistributedDataParallel 模块由全新的、重新设计的分布式库提供支持.
新的库的主要亮点有:
- 新的
torch.distributed是性能驱动的,并且对所有后端 (Gloo,NCCL 和 MPI) 完全异步操作 - 显着的分布式数据并行性能改进,尤其适用于网络较慢的主机,如基于以太网的主机
- 为
torch.distributedpackage中的所有分布式集合操作添加异步支持 - 在Gloo后端添加以下CPU操作:send,recv,reduce,all_gather,gather,scatter
- 在NCCL后端添加barrier操作
- 为NCCL后端添加new_group支持
2. WHAT
1.0 的多机多卡的计算模型并没有采用主流的 Parameter Server 结构,而是直接用了Uber Horovod 的形式,也是百度开源的 RingAllReduce 算法.
采用PS计算模型的分布式,通常会遇到网络的问题,随着worker数量的增加,其加速比会迅速的恶化,例如 resnet50 这样的模型,目前的TF在10几台机器的时候,加速比已经开始恶化的不可接受了. 因此,经常要上RDMA、InfiniBand等技术,并且还带来了一波网卡的升级,有些大厂直接上了100GBs的网卡,有钱任性.
而 Uber 的 Horovod,采用的 RingAllReduce 的计算方案,其特点是网络通信量不随着worker(GPU)的增加而增加,是一个恒定值.
简单看下图理解下,GPU 集群被组织成一个逻辑环,每个GPU有一个左邻居、一个右邻居,每个GPU只从左邻居接受数据、并发送数据给右邻居. 即每次梯度每个 gpu 只获得部分梯度更新,等一个完整的 Ring 完成,每个GPU都获得了完整的参数.
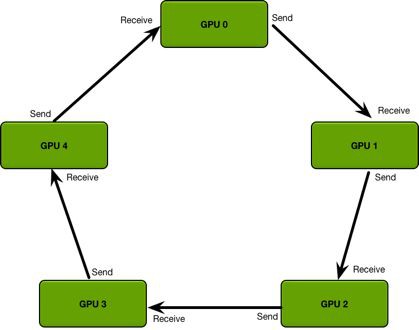
(From GPU高效通信算法-Ring Allreduce - GarvinLi)
3. HOW
torch.distributed 包提供了一个启动实用程序 torch.distributed.launch,此帮助程序可用于为每个节点启动多个进程以进行分布式训练,它在每个训练节点上产生多个分布式训练进程.
该工具既可以用来做单节点多GPU训练,也可用于多节点多GPU训练.
如果是单节点多GPU,将会在单个GPU上运行一个分布式进程,据称可以非常好地改进单节点训练性能.
如果用于多节点分布式训练,则通过在每个节点上产生多个进程来获得更好的多节点分布式训练性能.
如果有 Infiniband 接口则加速比会更高.
在单节点分布式训练或多节点分布式训练的两种情况下,该工具将为每个节点启动给定数量的进程 (--nproc_per_node).
如果用于 GPU 培训,则此数字需要小于或等于当前系统上的GPU数量 (nproc_per_node),并且每个进程将在从GPU 0到GPU (nproc_per_node - 1) 的单个GPU上运行.
3.1. Single-Node multi-process distributed training
python -m torch.distributed.launch
--nproc_per_node=NUM_GPUS_YOU_HAVE
YOUR_TRAINING_SCRIPT.py (--arg1 --arg2 --arg3 and all other
arguments of your training script)3.2. Multi-Node multi-process distributed training: (e.g. two nodes)
Node 1: (IP: 192.168.1.1, and has a free port: 1234)
python -m torch.distributed.launch
--nproc_per_node=NUM_GPUS_YOU_HAVE
--nnodes=2
--node_rank=0
--master_addr="192.168.1.1"
--master_port=1234
YOUR_TRAINING_SCRIPT.py (--arg1 --arg2 --arg3
and all other arguments of your training script)Node 2:
python -m torch.distributed.launch
--nproc_per_node=NUM_GPUS_YOU_HAVE
--nnodes=2
--node_rank=1
--master_addr="192.168.1.1"
--master_port=1234
YOUR_TRAINING_SCRIPT.py (--arg1 --arg2 --arg3
and all other arguments of your training script)需要注意的地方:
- 后端最好用
NCCL,才能获取最好的分布式性能 - 训练代码必须从命令行解析
--local_rank=LOCAL_PROCESS_RANK
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", type=int)
args = parser.parse_args()
torch.cuda.set_device(arg.local_rank)torch.distributed初始化方式
torch.distributed.init_process_group(backend='nccl',
init_method='env://')- model
model = torch.nn.parallel.DistributedDataParallel(
model,
device_ids=[arg.local_rank],
output_device=arg.local_rank)其他地方一般就不用修改了,真的顺滑了非常多.
4. PERFERMENCE
简单测了下MaskRCNN-R50FPN,32GPU用时3hours15mins,加速接近4倍.
5. Ring Allreduce 算法
From: 百度引入Ring Allreduce算法,大规模提升模型训练速度 - 雷锋网
作者: 亚萌
英文News:Baidu's 'Ring Allreduce' Library Increases Machine Learning Efficiency Across Many GPU Nodes
百度硅谷人工智能实验室(SVAIL)宣布将Ring Allreduce算法引进深度学习领域,这让基于GPU训练的神经网络模型的训练速度显著提高.
Ring Allreduce 是高性能计算(HPC)领域内一个众所周知的算法,但在深度学习领域内的应用相对较少.
5.1. 高效并行训练的需求
随着神经网络参数越来越庞大,从几亿个参数与到数十亿参数,所需的GPU运算节点也在增加. 然而,节点数量越多,整个系统的效率就会降低.
深度学习在多个GPU上训练神经网络通常比较困难,因为大家普遍采用的方法是,让多个GPU 把数据发送给一个reducer GPU上,这会造成一种通信瓶颈,整个训练速度会因此拖慢. 而且要训练的数据越多,则带宽瓶颈问题就显得越严重.
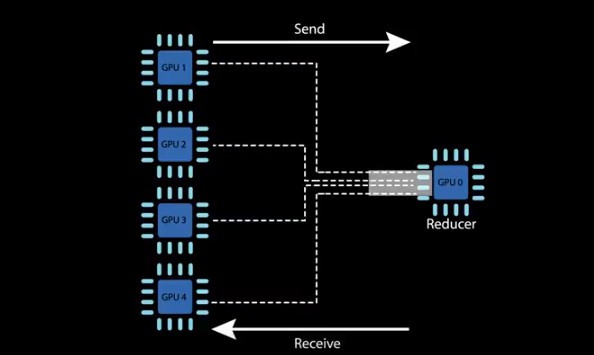
而 ring allreduce 算法移除了这种瓶颈,减少GPU发送数据花费的时间,而把时间更多用在处理有用工作上.
SVAIL发布的博文中这样说道:
ring allreduce 是这样一种算法——其通信成本是恒定的,与系统中的 GPU 的数量无关,并且仅由系统中的 GPU 之间的最慢连接来确定. 事实上,如果在通信成本上只考虑带宽这一因素(并忽略延迟),那么 ring allreduce 就是一个最佳的通信算法.
算法的进行分两步:第一步,scatter-reduce;第二步,allgather. 在第一步中,GPU 将交换数据,使得每个 GPU 最终都有一个最终结果的数据块. 在第二步中,GPU 将交换那些块,使得所有 GPU 最终得到完整的最后结果.
Ring Allreduce 中的 GPU 被布置在一个逻辑环路(logical ring)之中. 每个 GPU 左右两个各有一个 GPU,并且只从左边的 GPU 接收数据,再把数据发送至右边的 GPU.
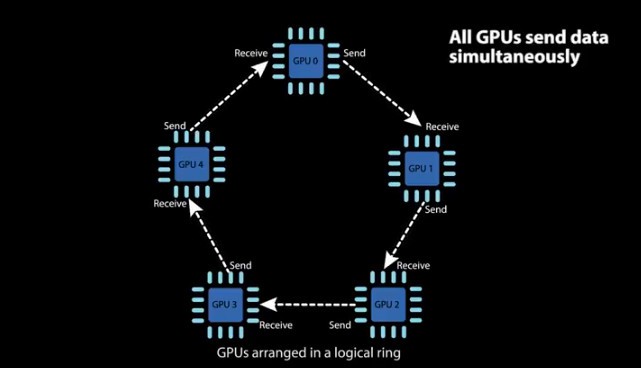
Ring Allreduce在接受采访时说道:
Ring allreduce 可以让我们在多设备和多节点的情况下,更加有效地平均梯度. 在训练中使用这个带宽优化的算法,可以显著减少通信开销,并由此扩展到更多的设备上,同时仍然保留同步随机梯度下降的确定性和可预测的收敛性.
百度已经用这个算法来训练其语音识别模型. 实验证明,与使用一个单独的reducer GPU相比,ring allreduce 可以将一个神经网络在40个GPU上的训练速度提升31倍.
6. Related
[1] - ring allreduce和tree allreduce的具体区别是什么?- 知乎
[2] - ring-allreduce简介
[3] - baidu-research/baidu-allreduce
One comment
[...]参考文献:https://eng.uber.com/horovod/https://www.aiuai.cn/aifarm740.htmlhttps://zhuanlan.zhihu.com/p/40578792https://ggaaooppeenngg.github.io/zh-CN/2019/08/30/horovod-实现分析/https://blog.csdn.net/zwqjoy/ar[...]