英文原文 - Semantic Segmentation using Fully Convolutional Networks over the years
图像的语义分割是将输入图像中的每个像素分配一个语义类别,以得到像素化的密集分类.
虽然自 2007 年以来,语义分割/场景解析一直是计算机视觉社区的一部分,但与计算机视觉中的其他领域很相似,自2014 年 Long 等人首次使用全卷积神经网络对自然图像进行端到端分割,语义分割才有了重大突破.

图1:输入图像(左),FCN-8s 网络生成的语义分割图(右)(使用 pytorch-semseg 训练)
FCN-8s 架构在 Pascal VOC 2012 数据集上的性能相比以前的方法提升了 20%,达到了 62.2% 的 mIOU. 这种架构是语义分割的基础,此后一些新的和更好的体系结构都基于此.
全卷积网络(FCNs)可以用于自然图像的语义分割、多模态医学图像分析和多光谱卫星图像分割. 与 AlexNet、VGG、ResNet 等深度分类网络类似,FCNs 也有大量进行语义分割的深层架构.
本文作者总结了 FCN、SegNet、U-Net、FC-Densenet E-Net 和 Link-Net、RefineNet、PSPNet、Mask-RCNN 以及一些半监督方法,如 DecoupledNet 和 GAN-SS,并为其中的一些网络提供了 PyTorch 实现. 在文章的最后一部分,作者总结了一些流行的数据集,并展示了一些网络训练的结果.
网络结构
一般的语义分割架构可以被认为是一个编码器-解码器(encoder-decoder)网络. 编码器通常是一个预训练的分类网络,像 VGG、ResNet,然后是一个解码器网络. 这些架构之间的不同主要在于解码器网络. 解码器的任务是将编码器学习到的可判别特征(较低分辨率)从语义上映射到像素空间(较高分辨率),以获得密集分类.
不同于分类任务中深度网络的最终结果(即类存在的概率)被视为唯一重要的事,语义分割不仅需要在像素级有判别能力,还需要有能将编码器在不同阶段学到的可判别特征映射到像素空间的机制. 不同的架构采用不同的机制(跳远连接、金字塔池化等)作为解码机制的一部分.
一些上述架构和加载数据的代码可在以下链接获得:
Pytorch:https://github.com/meetshah1995/pytorch-semseg
这篇论文对语义分割(包括 Recurrent Style Networks)作了一个总结.
Fully Convolution Networks (FCNs) 全卷积网络
Fully Convolutional Networks for Semantic Segmentation - CVPR2015
将当前分类网络(AlexNet, VGG net 和 GoogLeNet)修改为全卷积网络,通过对分割任务进行微调,将它们学习的表征转移到网络中.
然后,定义了一种新架构,它将深的、粗糙的网络层语义信息和浅的、精细的网络层的表层信息结合起来,来生成精确的分割.
全卷积网络 FCNs 在 PASCAL VOC(在 2012 年相对以前有 20% 的提升,达到了62.2% 的平均 IU),NYUDv2 和 SIFT Flow 上实现了最优的分割结果,对于一个典型的图像,推断只需要三分之一秒的时间.
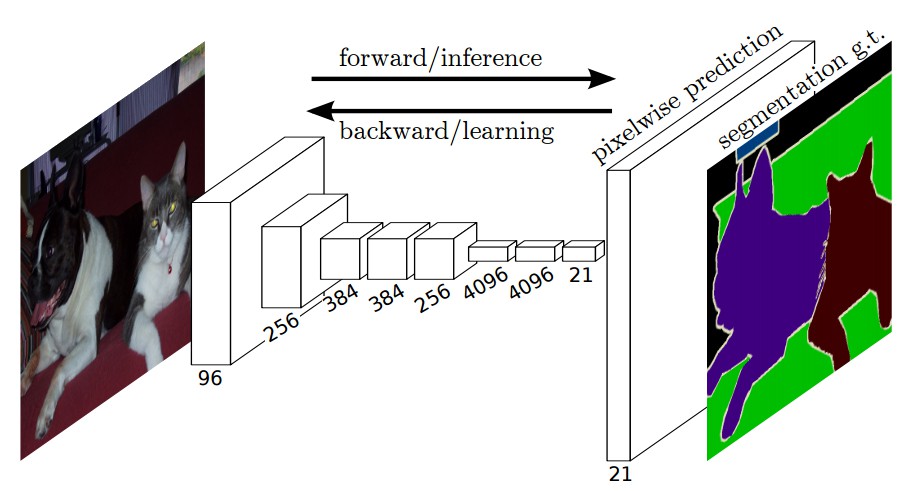
图2:FCN 端到端密集预测流程
关键特点:
- 特征是由编码器中的不同阶段合并而成的,它们在语义信息的粗糙程度上有所不同。
- 低分辨率语义特征图的上采样使用通过双线性插值滤波器初始化的反卷积操作完成。
- 从 VGG16、Alexnet 等现代分类器网络进行知识转移的优秀样本来实现语义细分。
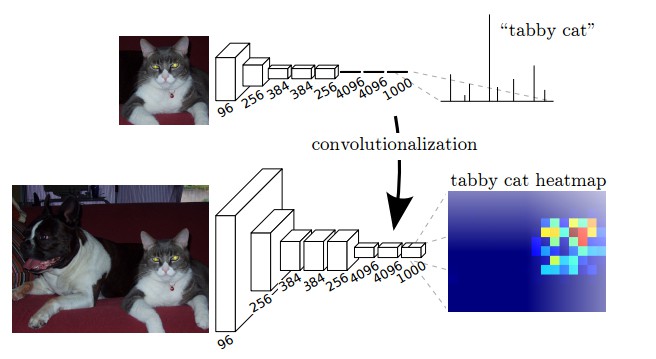
图3:将全连接层转换成卷积层,使得分类网络可以输出一个类的热图.
如上图所示,像 VGG16 分类网络的全连接层(fc6,fc7)被转换为全卷积层. 它生成了一个低分辨率的类的热图,然后用双线性初始化的反卷积,并在上采样的每一个阶段通过融合(简单地相加)VGG16 中的低层(conv4和conv3)的更加粗糙但是分辨率更高的特征图进一步细化特征.
在传统的分类 CNNs 中,池化操作用来增加视野,同时减少特征图的分辨率. 这对于分类任务来说非常有用,因为分类的最终目标是找到某个特定类的存在,而物体的空间位置无关紧要.因此,在每个卷积块之后引入池化操作,以使后续块能够从已池化的特征中提取更多抽象、突出类的特征.
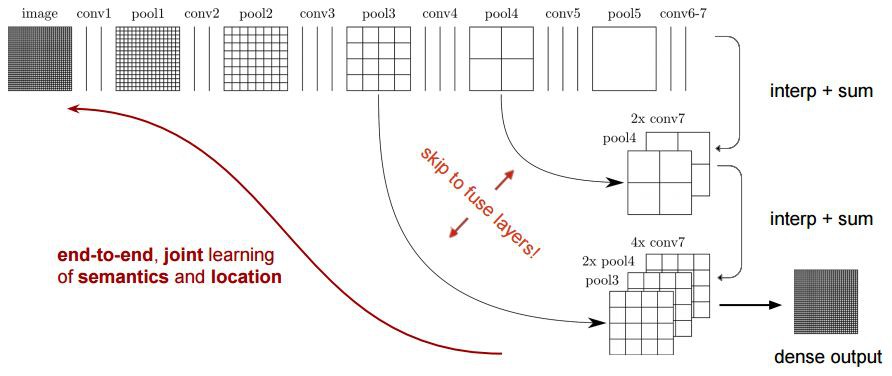
图4:FCN-8s 网络架构
另一方面,池化和带步长的卷积对语义分割是不利的,因为这些操作造成了空间信息的丢失.下面列出的大多数架构主要在解码器中使用了不同的机制,但目的都在于恢复在编码器中降低分辨率时丢失的信息. 如上图所示,FCN-8s 融合了不同粗糙度(conv3、conv4和fc7)的特征,利用编码器不同阶段不同分辨率的空间信息来细化分割结果.
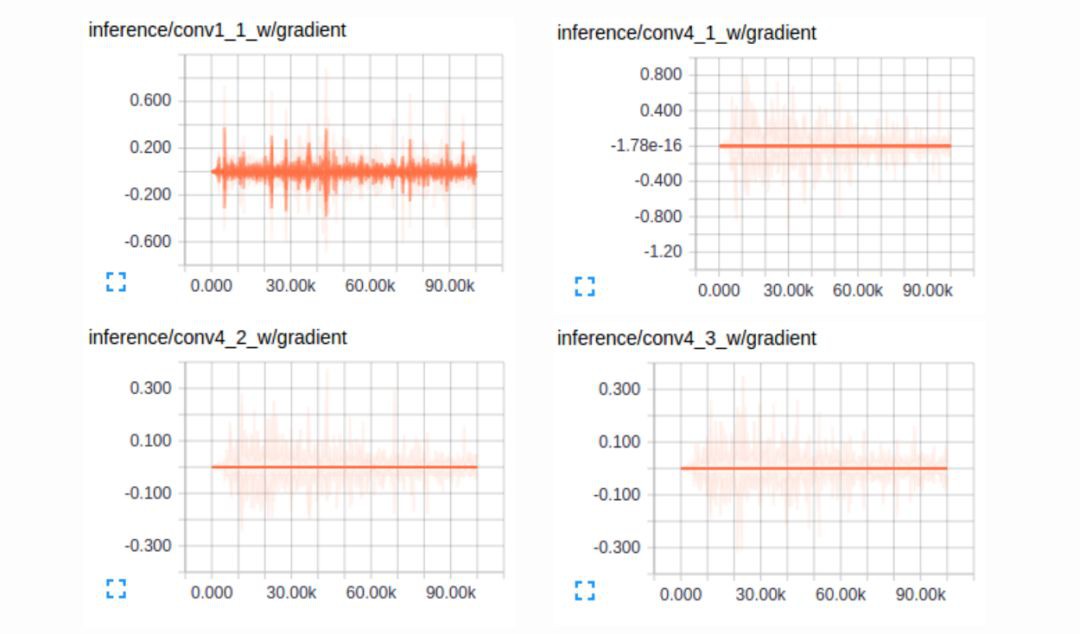
图5:训练 FCNs 时卷积层的梯度
第一个卷积层捕捉低层次的几何信息,因为这完全依赖数据集,可以注意到梯度调整了第一层的权重以使模型适应数据集. VGG 中更深层的卷积层有非常小的梯度流,因为这里捕获的高层次的语义概念足够用于分割.
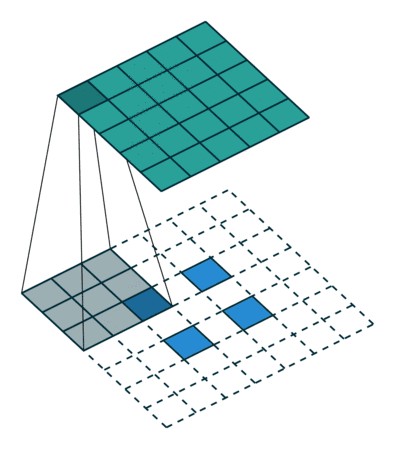
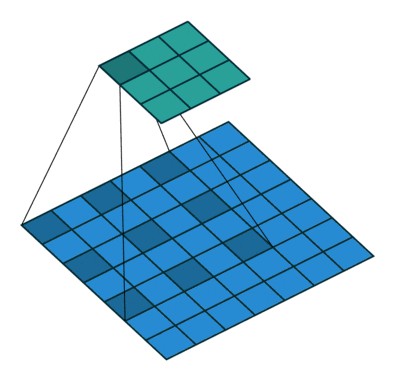
图6:(上)反卷积(卷积转置)Deconvolution (Transposed Convolution) (下)空洞卷积Dilated (Atrous) Convolution
From conv_arithmetic
语义分割架构的另一个重要方面是,对特征图使用反卷积,将低分辨率分割图上采样至输入图像分辨率机制,或者花费大量计算成本,使用空洞卷积在编码器上部分避免分辨率下降. 即使在现代 GPUs 上,空洞卷积的计算成本也很高.
SegNet
SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation - 2015
SegNet 的创新之处在于解码器decoder 对其较低分辨率的输入特征图进行上采样的方式. 具体地说,解码器使用了在相应编码器的最大池化步骤中计算的池化索引(pooling indices) 来执行非线性上采样. 这种方法消除了学习上采样的需要. 经上采样后的特征图是稀疏的,因此随后使用可训练的卷积核进行卷积操作,生成密集的特征图. 我们提出的架构与广泛采用的 FCN,DeepLab-LargeFOV,DeconvNet 架构进行比较. 结果揭示了在实现良好的分割性能时所涉及的内存与精度之间的权衡.

图7:SegNet 架构
关键点:
- SegNet 在解码器中使用去池化(unpooling)对特征图进行上采样,并在分割中保持高频细节的完整性.
- 编码器不使用全连接层(和 FCN 一样进行卷积),因此是拥有较少参数的轻量级网络.
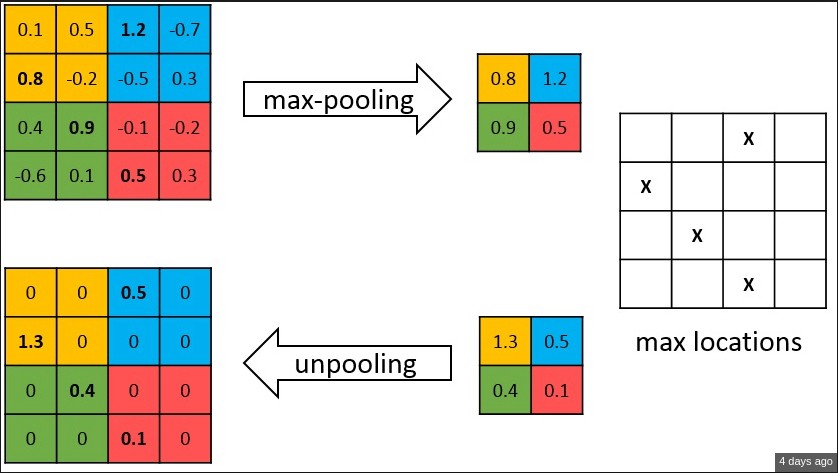
图8:去池化 unpooling
如上图所示,编码器中的每一个最大池化层的索引都存储了起来,用于之后在解码器中使用那些存储的索引来对相应特征图进行去池化操作. 这有助于保持高频信息的完整性,但当对低分辨率的特征图进行去池化时,它也会忽略邻近的信息.
U-Net
U-Net: Convolutional Networks for Biomedical Image Segmentation - MICCAI2015
U-Net 架构包括一个捕获上下文信息的收缩路径和一个支持精确本地化的对称扩展路径. 我们证明了这样一个网络可以使用非常少的图像进行端到端的训练,并且在 ISBI 神经元结构分割挑战赛中取得了比以前最好的方法(一个滑动窗口的卷积网络)更加优异的性能. 我们使用相同的网络,在透射光显微镜图像(相位对比度和 DIC)上进行训练,以很大的优势获得了 2015 年 ISBI 细胞追踪挑战赛。此外,网络推断速度很快. 一个 512x512 的图像分割在最新的 GPU 上花费了不到一秒.
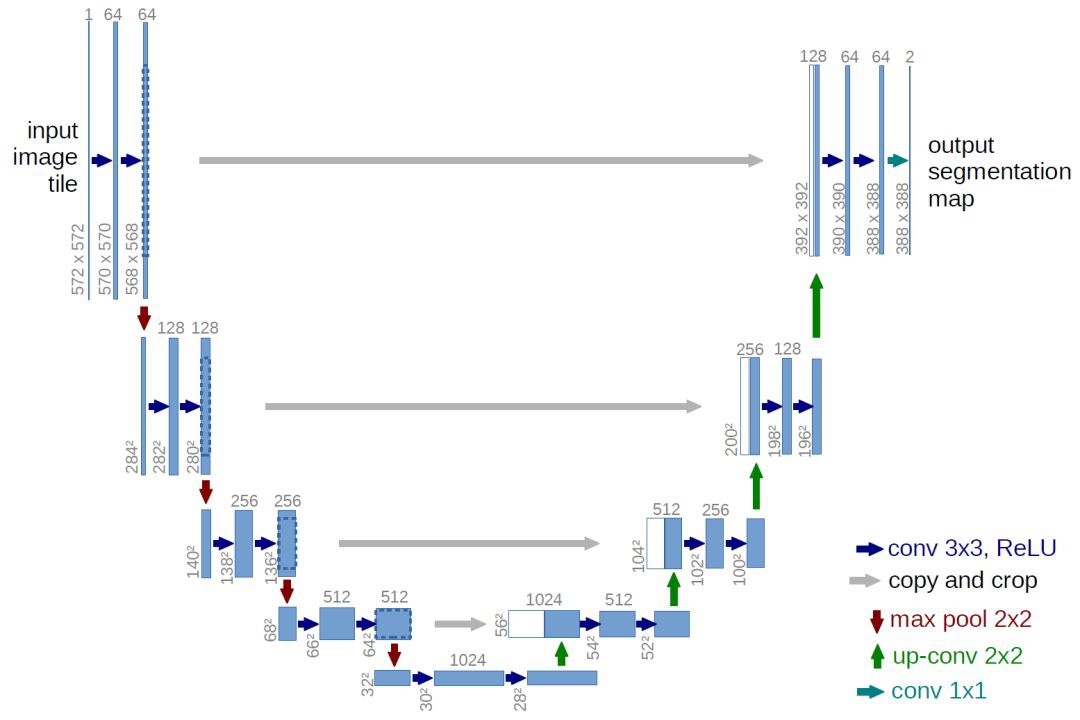
图9:U-Net 架构
关键点:**
- U-Net 简单地将编码器的特征图拼接至每个阶段解码器的上采样特征图,从而形成一个梯形结构. 该网络非常类似于 Ladder Network 类型的架构.
- 通过跳跃拼接(skip connection)连接的架构,在每个阶段都允许解码器学习在编码器池化中丢失的相关特性.
U-Net 在 EM 数据集上取得了最优异的结果,该数据集只有 30 个密集标注的医学图像和其他医学图像数据集,U-Net 后来扩展到 3D 版的 3D-U-Net. 虽然 U-Net 的发表是因为在生物医学领域的分割、网络实用性以及从非常少的数据中学习的能力,但现在已经成功应用在其他几个领域,例如卫星图像分割,同时也成为许多 kaggle 竞赛中关于医学图像分割获胜的解决方案中的一部分.
Fully Convolutional DenseNet
The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation - 2016
Fully Convolutional DenseNet 扩充了 DenseNets,以解决语义分割的问题. 在城市场景基准数据集(如 CamVid 和 Gatech )上获得了最优异的结果,不需要使用进一步的后处理模块和预训练模型. 此外,由于模型的优异结构,我们的方法比当前发布的在这些数据集上取得最佳的网络参数要少得多.
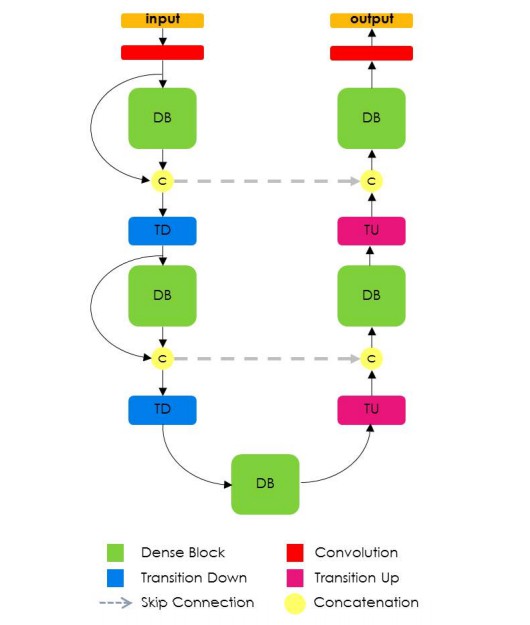
图10:全卷积 DenseNet 架构
全卷积 DenseNet 使用 DenseNet 作为它的基础编码器,并且也以类似于 U-Net 的方式,在每一层级上将编码器和解码器进行拼接.
E-Net 和 Link-Net
ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation - 2016
- ENet 论文里提出的一种新的深度神经网络架构,称为 ENet(efficient neural network),专门为需要低延迟操作(low latency operation)的任务创建. ENet 比当前网络模型快 18 倍,少了 75 倍的 FLOPs,参数数量降低了 79 倍,并且提供相似甚至更好的准确率. 在 CamVid、Cityscapes 和 SUN 数据集上进行了测试,展示了与现有的最优方法进行比较的结果,以及网络准确率和处理时间之间的权衡.
- LinkNet 可以在 TX1 和 Titan X 上,分别以 2fps 和 19fps 的速率处理分辨率为 1280x720 的图像.
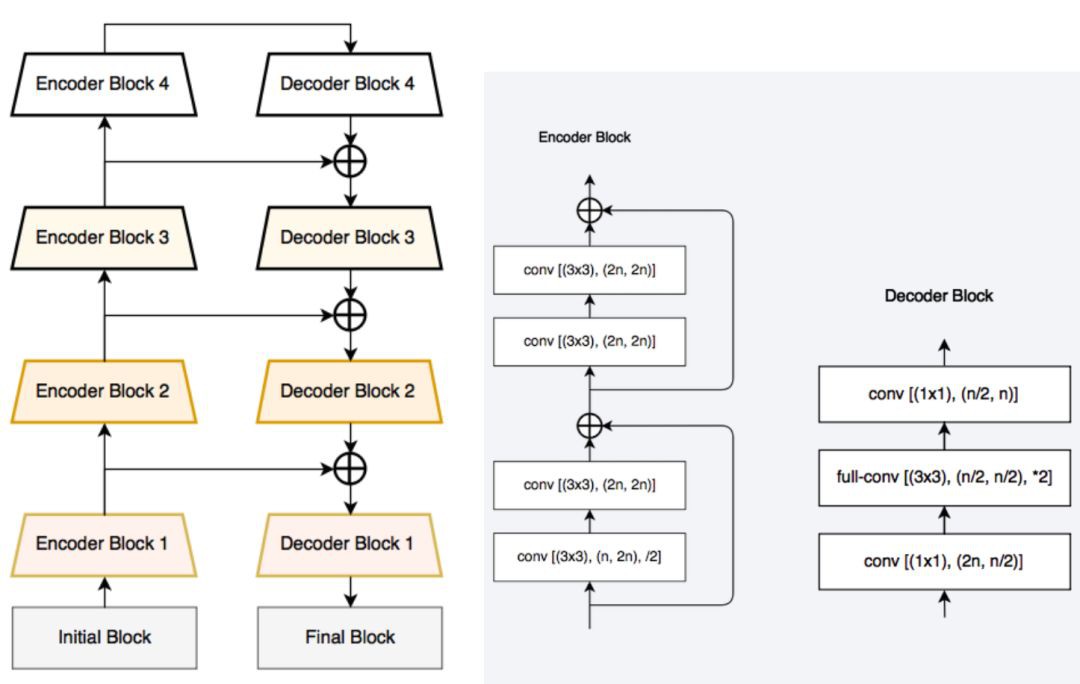
图11:(左)LinkNet 架构,(右)LinkNet 中使用的编码器和解码器模块
LinkNet 架构类似于一个梯形网络架构,编码器的特征图(横向)和解码器的上采样特征图(纵向)相加。还需要注意的是,由于它的通道约减方案(channel reduction scheme),解码器模块包含了相当少的参数。大小为 [H, W, n_channels] 的特征图先通过 1x1 卷积核得到大小为 [H, W, n_channels / 4] 的特征图,然后使用反卷积将其变为 [2xH, 2xW, n_channels /4],最后使用 1x1 卷积使其大小变为 [2xH, 2xW, n_channels / 2],因此解码器有着更少的参数. 这些网络在实现相当接近于最优准确率的同时,可以实时地在嵌入式 GPU 上进行分割。.
Mask R-CNN
Mask R-CNN,以 Faster R-CNN 为基础,在现有边界框识别分支基础上添加一个并行的预测目标掩码的分支. Mask R-CNN 很容易训练,仅仅在 Faster R-CNN 上增加了一点小开销,运行速度为 5fps. 此外,Mask R-CNN 很容易泛化至其他任务,如,可以使用相同的框架进行姿态估计. 在 COCO 所有的挑战赛中都获得了最优结果,包括实例分割,边界框目标检测,和人关键点检测. 在没有使用任何技巧的情况下,Mask R-CNN 在每项任务上都优于所有现有的单模型网络,包括 COCO 2016 挑战赛的获胜者.
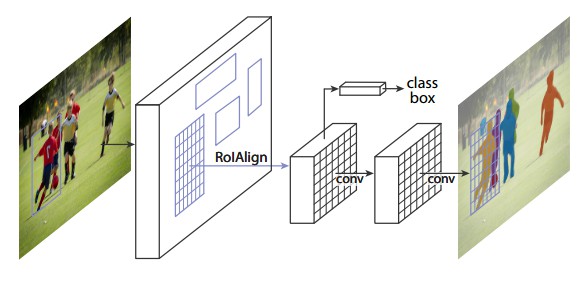
图12:Mask R-CNN 分割流程
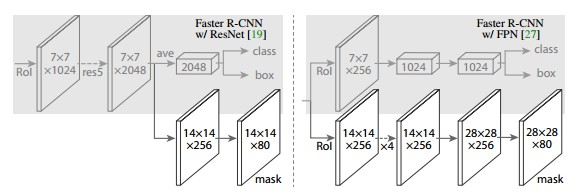
原始 Faster-RCNN 架构和辅助分割分支
Mask R-CNN 架构相当简单,它是流行的 Faster R-CNN 架构的扩展,在其基础上进行必要的修改,以执行语义分割.
关键点:
- 在 Faster R-CNN 上添加辅助分支以执行语义分割.
- 对每个实例进行的 RoIPool 操作已经被修改为 RoIAlign ,它避免了特征提取的空间量化,因为在最高分辨率中保持空间特征不变对于语义分割很重要.
- Mask R-CNN 与 Feature Pyramid Networks(类似 于PSPNet,它对特征使用了金字塔池化)相结合,在 MS COCO 数据集上取得了最优结果.
在 2017-06-01 的时候,在网络上还没有 Mask R-CNN 的工作实现,而且也没有在 Pascal VOC 上进行基准测试,但是它的分割掩码显示了它与真实标注非常接近.
PSPNet
利用基于不同区域的上下文信息集合,通过我们的金字塔池化模块,使用金字塔场景解析网络(PSPNet)来发挥全局上下文信息的能力. 我们的全局先验表征在场景解析任务中产生了良好的质量结果,而 PSPNet 为像素级的预测提供了一个更好的框架,该方法在不同的数据集上达到了最优性能.它首次在 2016 ImageNet 场景解析挑战赛 PASCAL VOC 2012 基准和 Cityscapes 基准中出现.
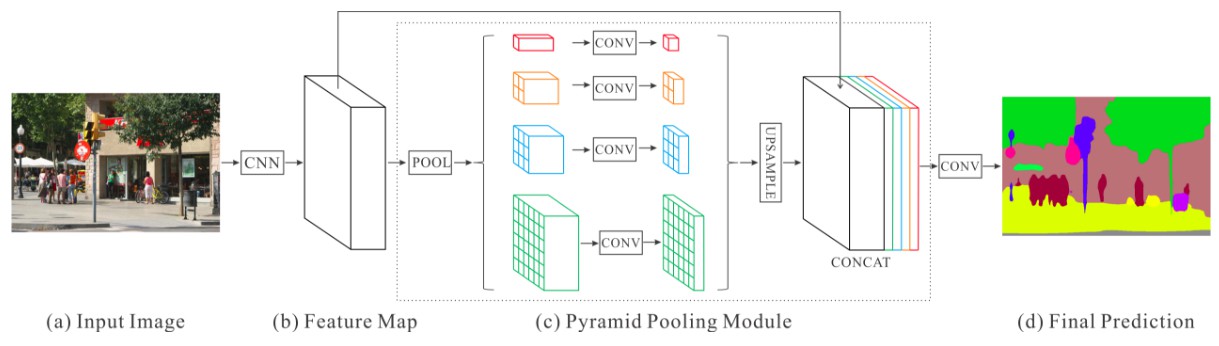
图13:PSPNet 架构
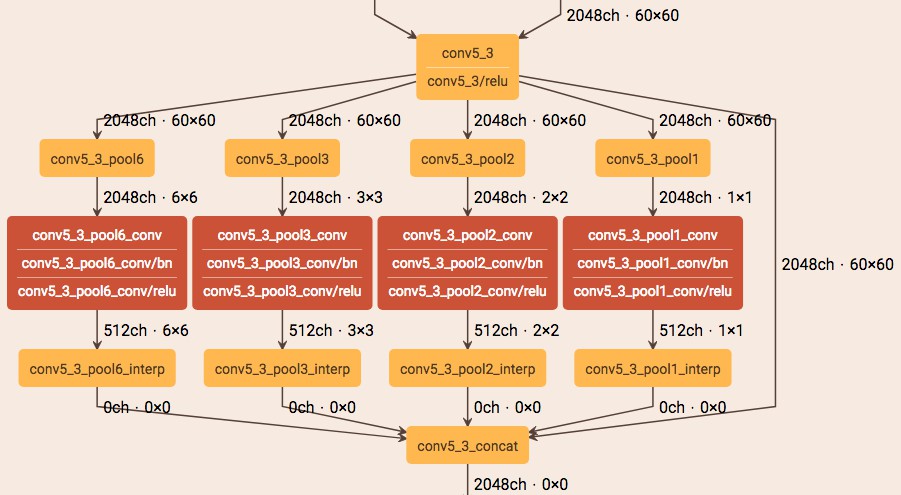
使用 netscope 实现的可视化的空间金字塔池化
关键点:
- PSPNet 通过引入空洞卷积(dilated convolutions) 来修改基础的 ResNet 架构,特征经过最初的池化,在整个编码器网络中以相同的分辨率进行处理(原始图像输入的 1/4),直到它到达空间池化模块.
- 在 ResNet 的中间层中引入辅助损失,以优化整体学习.
- 在修改后的 ResNet 编码器顶部的空间金字塔池化(Spatial Pyramid Pooling)聚合全局上下文.
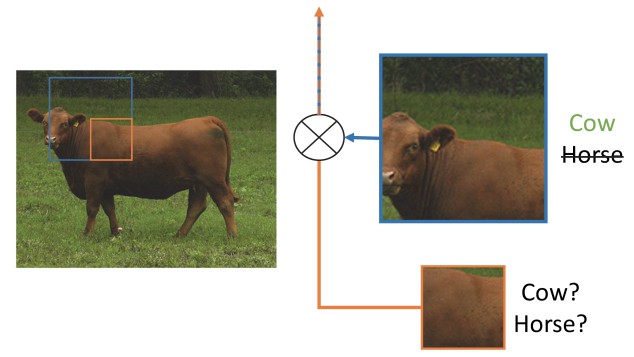
图 14:图片展示了全局空间上下文对语义分割的重要性. 它显示了层之间感受野和大小的关系. 在这个例子中,更大、更加可判别的感受野(蓝)相比于前一层(橙)可能在细化表征中更加重要,这有助于解决歧义.
PSPNet 架构目前在 CityScapes、ADE20K 和 Pascal VOC 2012 中有最优结果.
RefineNet
RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation - CVPR2017
RefineNet,一个通用的多路径优化网络,它明确利用了整个下采样过程中可用的所有信息,使用远程残差连接实现高分辨率的预测. 通过这种方式,可以使用早期卷积中的细粒度特征来直接细化捕捉高级语义特征的更深的网络层. RefineNet 的各个组件使用遵循恒等映射思想的残差连接,这允许网络进行有效的端到端训练.
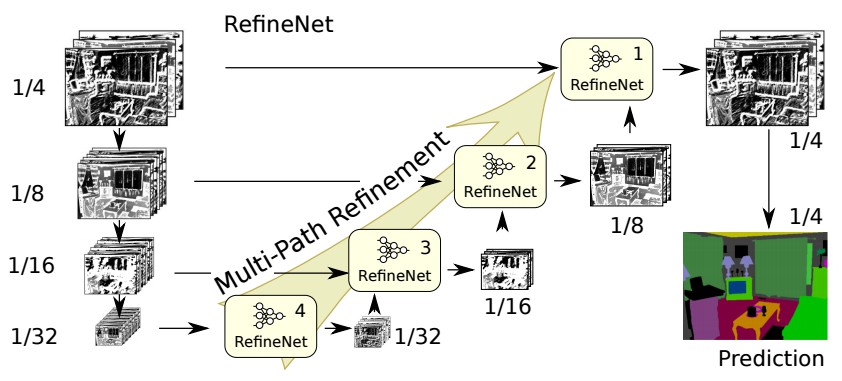
图15:RefineNet 架构

建立 RefineNet 的块 - 残差卷积单元,多分辨率融合和链式残差池化(Building Blocks of RefineNet - Residual Conv Units, Multiresolution Fusion and Chained Residual Pooling)
RefineNet 解决了传统卷积网络中空间分辨率减少的问题,与 PSPNet(使用计算成本高的空洞卷积)使用的方法非常不同. 提出的架构迭代地池化特征,利用特殊的 RefineNet 模块增加不同的分辨率,并最终生成高分辨率的分割图.
关键点:
- 使用多分辨率(multiple resolutions)作为输入,将提取的特征融合在一起,并将其传递到下一个阶段.
- 引入链式残差池化(Chained Residual Pooling),可以从一个大的图像区域获取背景信息. 它通过多窗口尺寸有效地池化特性,利用残差连接和学习权重方式融合这些特征.
- 所有的特征融合都是使用 sum(ResNet 方式)来进行端到端训练.
- 使用普通 ResNet 的残差层,没有计算成本高的空洞卷积(dilated convolutions).
G-FRNet
G-FRNet: Gated Feedback Refinement Network for Dense Image Labeling - CVPR2017
Gated Feedback Refinement Network (G-FRNet),是一种用于密集标记任务的端到端深度学习框架,解决了现有方法的局限性. 最初,GFRNet 进行粗略地预测,然后通过在细化阶段有效地集成局部和全局上下文信息,逐步细化细节. 引入了控制信息前向传递的门控单元,以过滤歧义.
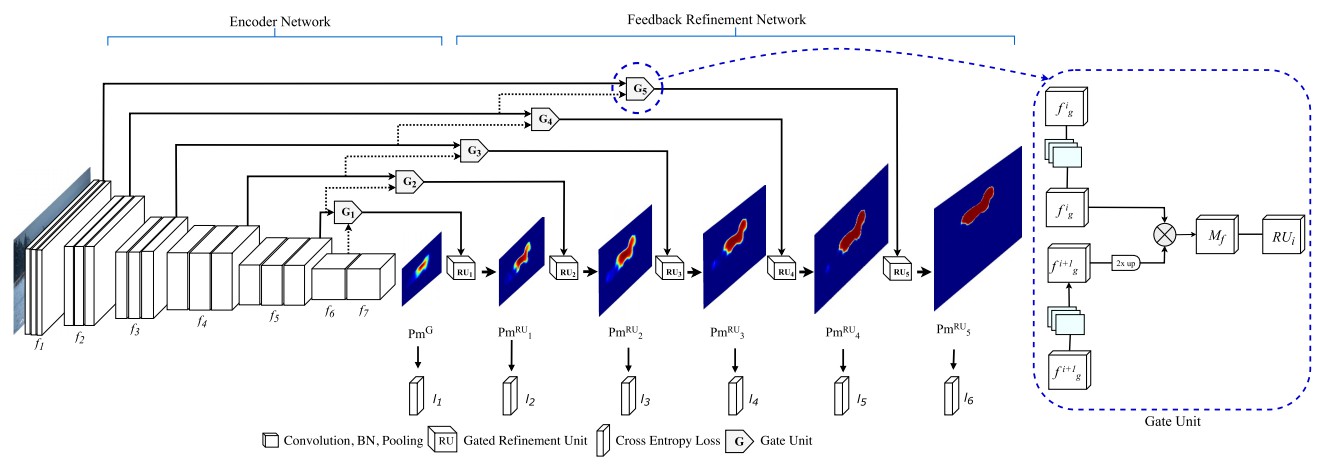
图16:G-FRNet 架构
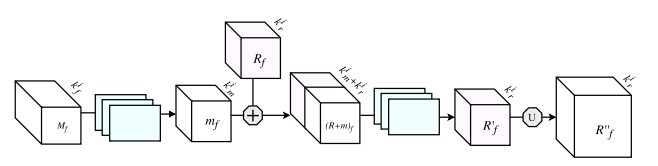
门控细化单元
上述大多数架构都依赖于从编码器到解码器的简单特征,使用拼接、去池化或简单的加和. 然而,在编码器中,从高分辨率(较难判别)层到对应的解码器中相应的上采样特征图的信息,不确定是否对分割有用. 在每个阶段,通过使用门控细化反馈单元,控制从编码器传送到解码器的信息流,这样可以帮助解码器解决歧义,并形成更相关的门控空间上下文.
另一方面,本文的实验表明,在语义分割任务中,ResNet 是一个远优于 VGG16 的编码器. 这是在以前的论文中找不到的.
Semi-Supervised Semantic Segmentation
DecoupledNet
Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation - NIPS2015
与现有的将语义分割作为基于区域分类的单一任务的方法相反,该算法将分类和分割分离,并为每个任务学习一个单独的网络. 在这个架构中,通过分类网络识别与图像相关的标签,然后在分割网络中对每个识别的标签执行二进制分割. 它通过利用从桥接层获得的特定类的激活图来有效地减少用于分割的搜索空间.

图17:DecoupledNet 架构
这也许是第一个使用全卷积网络进行语义分割的半监督方法.
关键点:
- 分离分类和分割任务,从而使预训练的分类网络能够即插即用(plug and play).
- 分类和分割网络之间的桥接层生成突出类的特征图(k 类),然后输入分割网络,生成一个二进制分割图(k 类).
- 但是,这个方法在一张图像中分割 k 类需要传递 k 次。
GAN Based Approaches
Semi and Weakly Supervised Semantic Segmentation Using Generative Adversarial Network - 2017
基于生成对抗网络(GANs),提出的一种半监督框架,它包含一个生成器网络以提供用于多类别分类器的额外训练样本,以此作为 GAN 框架中的判别器,从 K 个可能的类中为样本分配一个标签 y 或者将其标记为一个假样本(额外的类). 为了确保 GANs 生成的图像质量更高,并改进像素分类,我们通过添加弱标注数据来扩展上述框架,即我们向生成器提供类级别的信息.
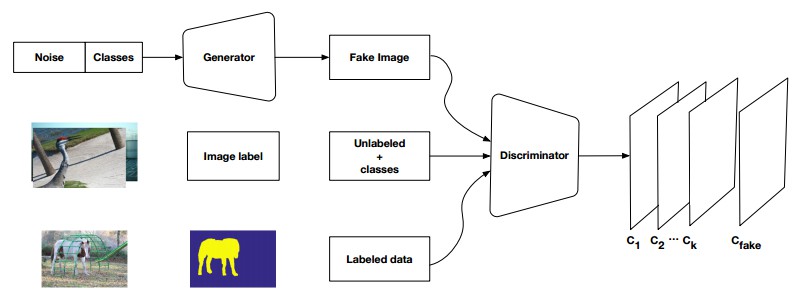
图18:弱监督(类级别标签) GAN
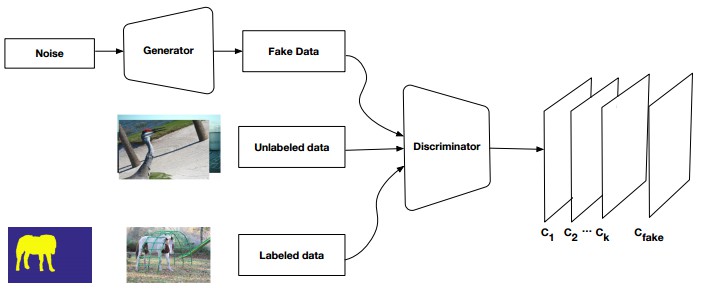
图19:半监督GAN
数据集
| Dataset | Training | Testing | #Classes |
|---|---|---|---|
| CamVid | 468 | 233 | 11 |
| PascalVOC 2012 | 9963 | 1447 | 20 |
| NYUDv2 | 795 | 645 | 40 |
| Cityscapes | 2975 | 500 | 19 |
| Sun-RGBD | 10355 | 2860 | 37 |
| MS COCO ‘15 | 80000 | 40000 | 80 |
| ADE20K | 20210 | 2000 | 150 |
结果

图20:FCN-8s 生成的样本语义分割图(使用 pytorch-semseg 训练)来自 Pascal VOC 验证集