原文:Carvana Image Masking Challenge–1st Place Winner's Interview
Github - Code for a 1st place model in Carvana Image Masking Challenge
Kaggle 车辆分割竞赛 - Carvana Image Masking Challenge on car segmentaion
竞赛的 Top-1 团队成员:
- Albu: Alexander Buslaev
- Asanakoy: Artsiom Sanakoyeu
- Ternaus: Vladimir Iglovikov
团队的三个成员刚开始是分别独立参赛,
- kaggle_carvana_segmentation Buslaev - Albu
- kaggle_carvana_segmentation - Asanakoy
- kaggle_carvana_segmentation - Ternaus
团队每个成员都专注了该比赛两周,在一张 Titan X Pascal 显卡上完全复现其解决方案大概需要 90 天来训练,13 天来测试.
不过,他们采用了大约 20 个 GPUs. 采用 PyTorch 深度学习框架,OpenCV 图像处理,以及 imgaug 数据增强.
竞赛问题综述

该竞赛的目标是,构建高分辨率 car 图片的二值分割模型(create a model for binary segmentation of high-resolution car images).
- 每张图片的尺寸 1918x1280.
每辆 car 被摆放于 16 个不同的固定方向.

训练数据集 5088 张图片.
测试数据集 1200 in Public, 3664 in Private, 95200 were added to prevent hand labeling.
数据存在的问题
一般来说,竞赛数据集的质量非常高.
该 Top-1 团队的成绩(0.997332)与第二名的成绩(0.997331) 相差仅仅是 0.00001,其可以解释为,每 2500000-pixel 的图像,仅有 2.5-pixel 的提升.
为了分析理解模型的局限所在,对预测结果进行了可视化检查.
对于训练数据集,重新复查了 lowest validation scores 的样本.
观察到的错误情况大部分是由于类别标注的不一致性(inconsistent labeling) 所导致的. 其中最普遍的是关于车轮的标注. 在某些 car 的标注中,标注了车轮细节;而有的没有标注.

该团队没有计算测试集的 validation score,但,他们通过计算网络预结果中置信度(confidence)较低的像素的个数.
考虑到图片中 cars 的尺寸的不同,其将计算的低置信度的像素数除以背景的面积(divided this number by the area of the background).
这种 'unconfidence' 度量的计算是,像素置信度在 [0.3, 0.8] 区间的像素个数,除以像素置信度在 [0, 0.3) + (0.8, 0.9] 区间的像素个数. 其它信息论的方法可能更鲁棒,但这里的方法也比较有效.
unconfidence = (像素置信度在 [0.3, 0.8] 区间的像素个数) / (像素置信度在 [0, 0.3) + (0.8, 0.9] 区间的像素个数)
然后,根据 'unconfidence' score 对图像进行排名,并可视化检查 top 的预测结果. 该团队发现,大部分错误是由于对
白色厢式货车(white van)类别的错误人工标注导致的. 训练的网络会对这些图片预测出低置信度的结果.
其它团队也遇到了类似的问题 - forum disscussion.
另外,也有一些明显错误的训练标注 masks.

团队成员 Vladimir 的方案
首先进行的尝试是,采用与 Sergey Mushinskiy 在 Satellite Imagery Feature Detection using Deep Convolutional Neural Network: A Kaggle Competition 中采用的 UNet 网络.
Vladimir 先前采用过该 UNet 网络处理 DSTL Satellite Imagery Feature Detection 竞赛.
在 DSTL 竞赛中,UNet 网络采用预训练 encoder 权重初始化和随机权重初始化的精度很一致. 在其它竞赛中,不采用训练的模型权重初始化,同样可以取得很好的结果. 鉴于对 UNet 的理解,预训练的模型权重初始化是不必要的,且益处不明显.
现在发现,UNet 类型网络的权重初始化,采用预训练的模型权重,有助于网络训练收敛,提升对 8-bit RGB 输入图像的二值分割的精度.
基于 VGG-11 encoder 的 UNet,很轻易就取得了 0.972(top-10) 的结果.
图像数据增强部分,采用水平翻转(horizontal flips),颜色增强(color augmentations) 以及将 car(前景 car,不是背景) 转换为灰度(grayscale).

(左上)原图;(右上)灰度格式的 car;(下) HSV 空间的数据增强.
原始图像的尺寸为 (1918, 1280),补零(padded)到 (1920, 1280)作为输入尺寸,保证 height 和 width 都可以被 32 整除(网络输入要求).
基于该 UNet 结构和图像尺寸,在单张 GPU 上仅能处理一张图片,且不能采用较深的编码器,如 VGG16/19. batch size 被限制到了 4 张图像.
一种可行的解决方案是,裁剪图片进行训练并在整张图片上进行预测. 然而,当目标物体比输入图片较小时,能够取得较好的效果. 但,该数据集中,某些 cars 目标会占满图像的宽度(width),因此,决定不采用裁剪图片的方案.
另一种方案是,(其它参赛人员所采用的),下采样输入图片. 但,会导致精度降低. 由于其 scores 都比较接近,因此不希望损失单个像素的精度.(Top-1 团队的成绩(0.997332)与第二名的成绩(0.997331) 相差仅仅是 0.00001)
为了减少预测结果的方差,采用 5 folders 上分别训练网络进行集成学习(bagging),然后平均五个网络的预测结果.
模型训练中,采用的 loss 函数为:
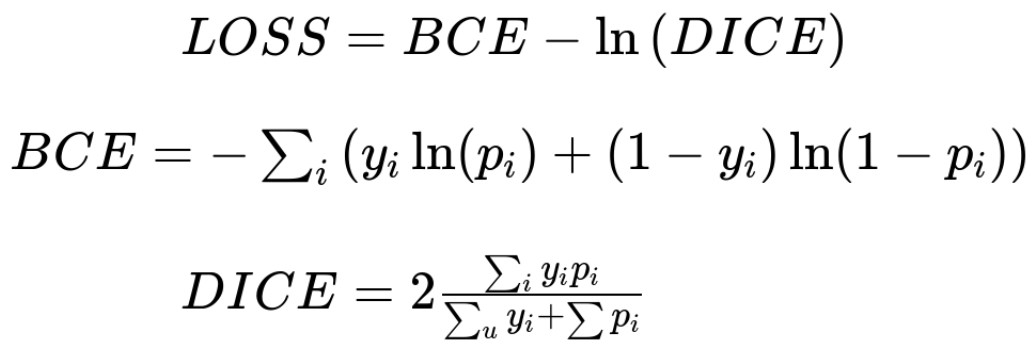
该 loss 函数被普遍用于二值图像分割中,其简化阈值化,预测结果范围为 [0, 1] 区间.
采用 Adam Optimizer 优化. 当 validation loss 在 2 个 epochs 不再提升时,前 30 个 epochs 将学习率减少一半.
然后,对于另外 20 个 epochs,采用周期的学习率,在 1e-4 和 1e-6 间摆动:1e-6, 1e-5, 1e-4, 1e-5, 1e-6. 每两个 epochs 学习率改变一次.
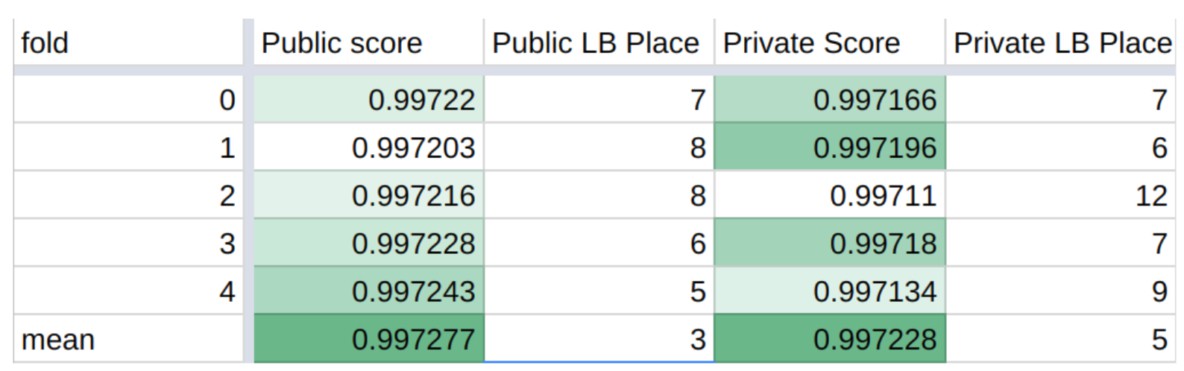
每个 fold 的预测结果,不包括后处理:
团队成员 Alexander 的方案
与其他参赛着一样,Alexander 也是从 UNet 网络结构入手. 但很快发现,其硬件局限性,不得不调整输入图片,或者对图片裁剪进行学习.
然后进行的尝试是,只沿着边界(border) 裁剪生成粗略的 masks. 但是,网络学习的很慢.
接着,开始着眼于新的网络结构,意外发现一个机器学习训练视频中,关于如何采用 LinkNet 进行图像语义分割. 因此,找到源论文,并尝试实现.

LinkNet 是一种经典的 encoder-decoder 分割结构,其特点如下:
解码器decoer 包含 3 个 Blocks:convolution 1x1 with n // 4 filters,transposed convolution 3x3 with stride 2 and n // 4 filters 和最后的一个 1x1 卷积层以匹配输入尺寸的 filters 的数量.
具有相同 feature maps 尺寸的编码器层和解码器层采用 plus 操作进行连接. 尝试以 filters dimension 进行连接,并采用 conv1x1 来降低下一网络的 filters 数量.(效果更好一点)
LinkNet 结构的主要缺点是,其开始就将输入图片尺寸降低了 4x,可能影响提取的特征和精度.
Alexander 选择 ResNet-34 作为编码器. 也试过 ResNet-18,但不够好;ResNet-50,参数比较多,难以训练. 编码器endoer 在 ImageNet 数据集进行预训练. 一个 epoch 的训练仅耗时 9 分钟,两三个 epoches 后就有明显降低. 建议尝试下 LinkNet,其平衡了速度和内存小概率. 训练时,一个 batch,采用全分辨率的 1920x1280 图片作为输入,每张 GPU (7.5G) 一张图片.
训练时,采用了 soft 数据增强:水平翻转(horizontal flips), 10% 缩放(scalings),5 度旋转(rotations) 和 HSV 数据增强. 采用 Adam(和 RMSProp) Optimizer 优化,前 12 个 epochs 中,learning rate=1e-4,再 6 个 epochs 中,learning rate=1e-5. Loss 函数:1 + BCE - Dice.
测试时,仅有水平翻转.
另外,这里也采用了 bagging 方法减少预测结果的方差. 由于训练速度较快,因此可以训练更多的网络,并平均各网络模型的预测结果. 最终,采用了 6 个不同网络,每个网络在 5 folder 上训练,共有 30 个模型.

不太普遍的技巧:
- [1] - 替换 LinkNet 中跳跃链接中 plus 操作替换为 concat 和 conv1x1.
- [2] - 难样本选择(Hard negative mining): 重复 10 batches 中最差的 batch.
- [3] - 对比度受限自适应直方图均衡(Contrast-limited adaptive histogram equalization, CLAHE) 预处理:用来增加与黑底的对比度(used to add contrast to the black bottom).
- [4] - 循环的学习率(Cyclic learning rate): (2 epoch 1e-4, 2 epoch 1e-5, 1 epoch 1e-6). 正常来说,应该每个 cycle 选择一个断点模型,但,推断时间起见,只选择最佳断点模型.
团队成员 Artsiom 的方案
Artsiom 训练了两个网络,是最终提交的版本中的部分.
与团队另外两个成员 Vladimir 和 Alexander 不同的是,Artsiom 调整了输入图片尺寸,采用 1024x1024 作为输入图片尺寸,推断时,将预测的 masks 上采样恢复为原来的图像尺寸.
第一个网络:从零训练 UNet
定义了 6 Up/Down 卷积 blocks 的 UNet.
每一个 Down block 包含 2 个卷积层和 2 个 max-pooling 层.
每一个 Up block 包含一个双线性上采样层(bilinear upscaling) 和 3 个卷积层.
网络权重随机进行初始化.
Loss 函数采用 f(x) = BCE + 1 - DICE.
计算 BCE loss 时,,mask 的每个像素点权重根据其距离 car 边界的距离进行加权( Heng CherKeng 提出的 tick.) 边界处的像素的权重是在 car 里面像素的 3 倍.
When calculating BCE loss, each pixel of the mask was weighted according to the distance from the boundary of the car.
Pixels on the boundary had 3 times larger weight than deep inside the area of the car.
数据集分为 7 个 folds(without stratification). 网络采用 SGD 从零开始训练了 250 个 epochs. 每 100 个 epochs,学习率减半(x0.5).
第二个网络:UNet-VGG-11
采用 VGG-11 的 UNet 作为编码器,类似于 Vladimir 所采用的,但编码器更宽.
VGG-11 ('VGG-A') 是 11-layer 卷积网络,其可以在 ImageNet 数据集上预训练权重,提供好的模型初始化.
交叉验证时,采用 7 folds,在所有的 16 个方向中的每个 car 的 masks 的总面积来分层.
网络训练了 60 个 epochs,采用 加权loss,类似于第一个网络所采用的 loss;cyclic learning rate.
One learning loop is 20 epochs: 10 epochs with base_lr, 5 epochs with base_lr * 0.1, and 5 epochs with base_lr * 0.01.
有效的 batch size 是 4. 当 GPU 内存不够时,采用几次迭代的梯度累积计算.
两种类型的数据增强:
- Heavy - 随机平移(random translation),缩放(scaling),旋转(rotation),改变光照(brightness change),改变饱和度(saturation change),转换为灰度(conversion to grayscale).
- Light - 随机平移,缩放和旋转.
第一个模型采用 heavy 数据增强进行训练.
第二个模型 15 个 epochs 采用 heavy 数据增强,45 个 epochs 采用 light 数据增强.
总共训练了 14 个模型(2 中网络结构,每个 7 folds).
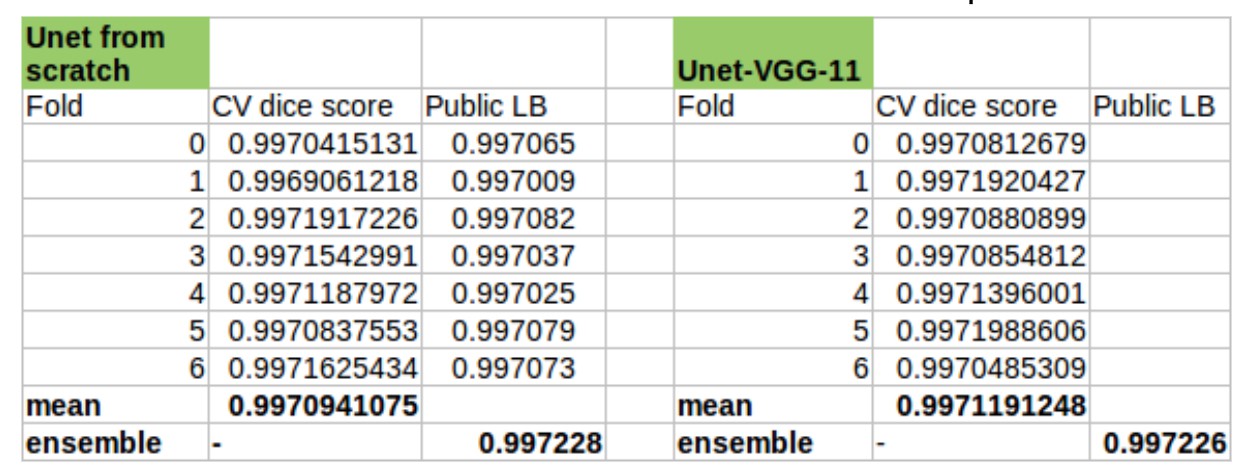
可以看出,两种 UNet 基本上具有一样的结果 - 0.9972.
但由于不同的网络结构和权重初始化,最终这两个模型的组合对于该团队最终的成绩有着明显作用.
合并与后处理
该团队采用了简单的像素级平均模型结果作为简答的合并策略.
首先,对 Alexander 的 6x5=30 个模型进行平均,然后,再与其它的模型进行平均.
该团队也尝试寻找 outliers 和难样本. 对此,首先,检查平均化的预测结果,查找概率范围在 [0.3, 0.8] 区间的像素,并标记其为不可信(unreliable). 然后,根据不可信的像素面积进行排序,对最差的进行额外处理. 此时,选择最佳表现的模型,调整概率边界. 另外,还对低可靠性区域上的凸包进行了处理. 对于网络模型处理不好的情况,能够给出看起来不错的 masks.
Extra materials
[1] - Video from Roman Solovyov (https://www.youtube.com/watch?v=hwCUY4mwX1I)
[2] - Presentation at Yandex by Sergey Mushinsky (4th place solution) (English subtitles)
[3] - 6th place JbestDeepGooseFlops solution overview