原文 - A Meta-analysis of DAVIS-2017 Video Object Segmentation Challenge
在 Video Object Segmentation — The Basics, 视频分割 - 简介与数据集及DAVIS挑战赛 中,简述了视频目标分割的定义,评价度量;并介绍了 [DAVIS-2016] 数据集上的两种方法:MaskTrack and OSVOS.
这里介绍 DAVIS-2017 数据集挑战赛涉及的算法.

DAVIS-2017: 多实例视频目标分割挑战赛
精度方面,DAVIS-2017 中有了明显提升. 作为参考的 DAVIS-2016 优秀方法,OSVOS,在 DAVIS-2017 中得到的区域相似度(Region Similarity) 约为 46;但在 DAVIS-2017 的最佳方法的区域相似度是 67.9.
DAVIS-2017 挑战赛中,22 个参赛队伍中,排名前 9 个结果.
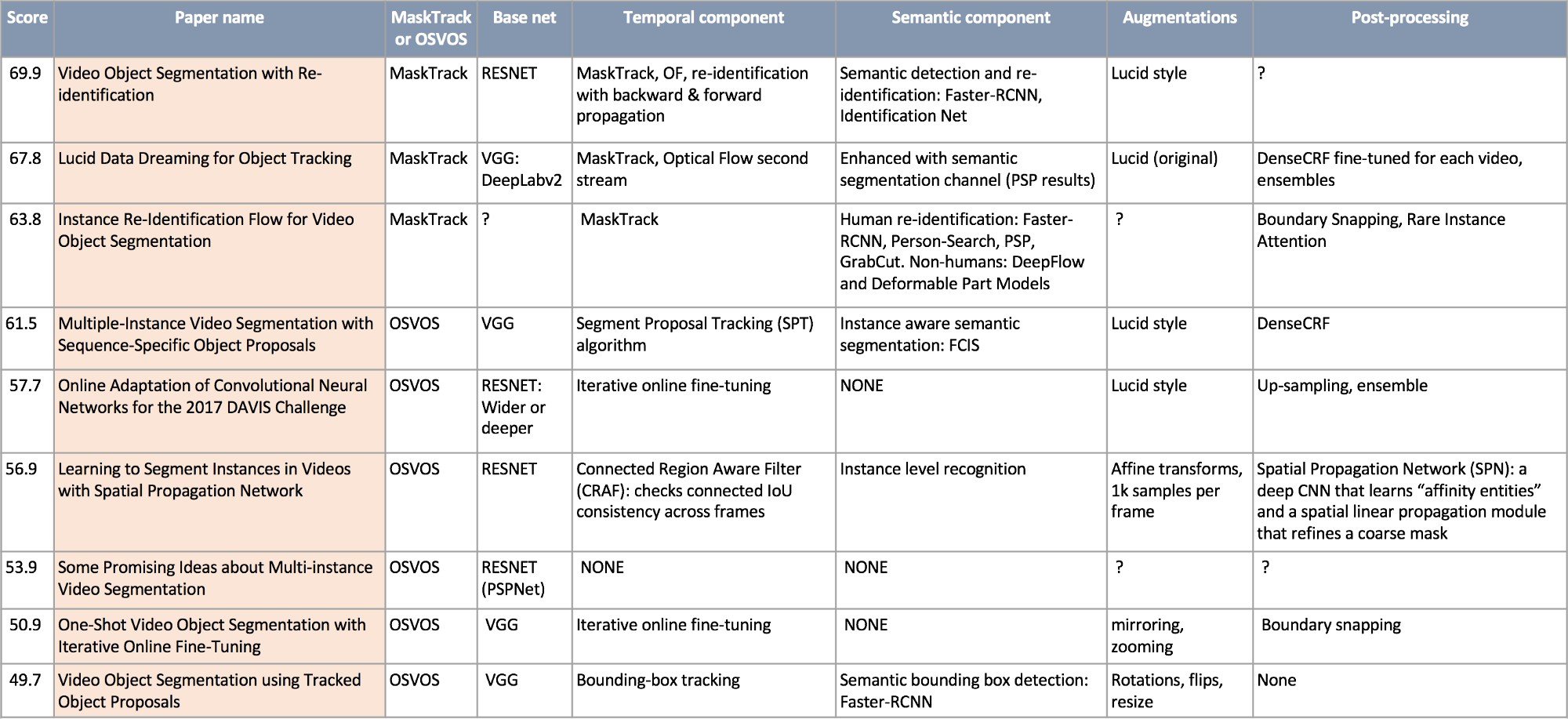
从表格中可以看出,DAVIS-2017 的一些趋势:
- [1] - 所有领先的工作成果都是基于 MaskTrack 或 OSVOS.
- [2] - DAVIS-2017 中,MaskTrack 取得了胜利.
- [3] - Lucid Data Dreaming 数据增强逐渐流行.
- [4] - 大约一半的工作成果采用的 base 网络为 ResNet.
- [5] - 几乎每个工作都采用了时序信息,利用了连续视频帧趋势的相似性.
- [6] - 大约一半的工作成果采用了语义信息,利用了语义分割或检测网络(边界框).
下面简单介绍一些优秀的工作成果.
1. Lucid Data Dreaming 目标追踪
MaskTrack 作者的一个重要的工作是,Lucid Data Dreaming,其旨在,改变需要多少训练样本和解决这个问题所需要的一般“目标”的心态.
change the mindset regarding how many training samples and general “objectness” knowledge is required to approach this problem.
- [1] - MaskTrack 的作者从 DAVIS-2017 数据集和每一个视频的第一帧的标注来生成 "in-domain" 训练数据. 对于 per-video fine-tuning,他们从单个标注的视频帧合成了 2500 增强数据,表示了可用的未来视频帧.
- [2] - MaskTrack 的数据增强处理过程是,先裁剪(cutting-out)前景目标,修复(in-painting) 背景,打乱前景和背景,最后再重组场景. 随机采用变换参数两次,重复该处理过程. 得到视频帧对(Iτ−1, Iτ ) 和对应的 groun-truth 像素级 mask 标注 (Mτ−1, Mτ ),光流 Fτ,和遮挡区域,因为采用的变换是已知的.
- [3] - DAVIS-2016 中,MaskTrack 表明了未在 ImageNet 上预训练,其结果仅会降低 2~5%. 因此,只采用第一帧标注作为训练数据,实际上也可以取得很好的结果.
- [4] - MaskTrack 采用了 DeepLabV2 结构,改变了其输入,以处理更大的输入通道:[3(rgb) + n(amount of instance masks) + 1(optical flow) + 1(semantic segmentation)],分别对每个视频进行训练.
- [5] - lucid dreaming 的另一个好处是,能够对每个视频进行 CRF 后处理的微调(fine-tune).
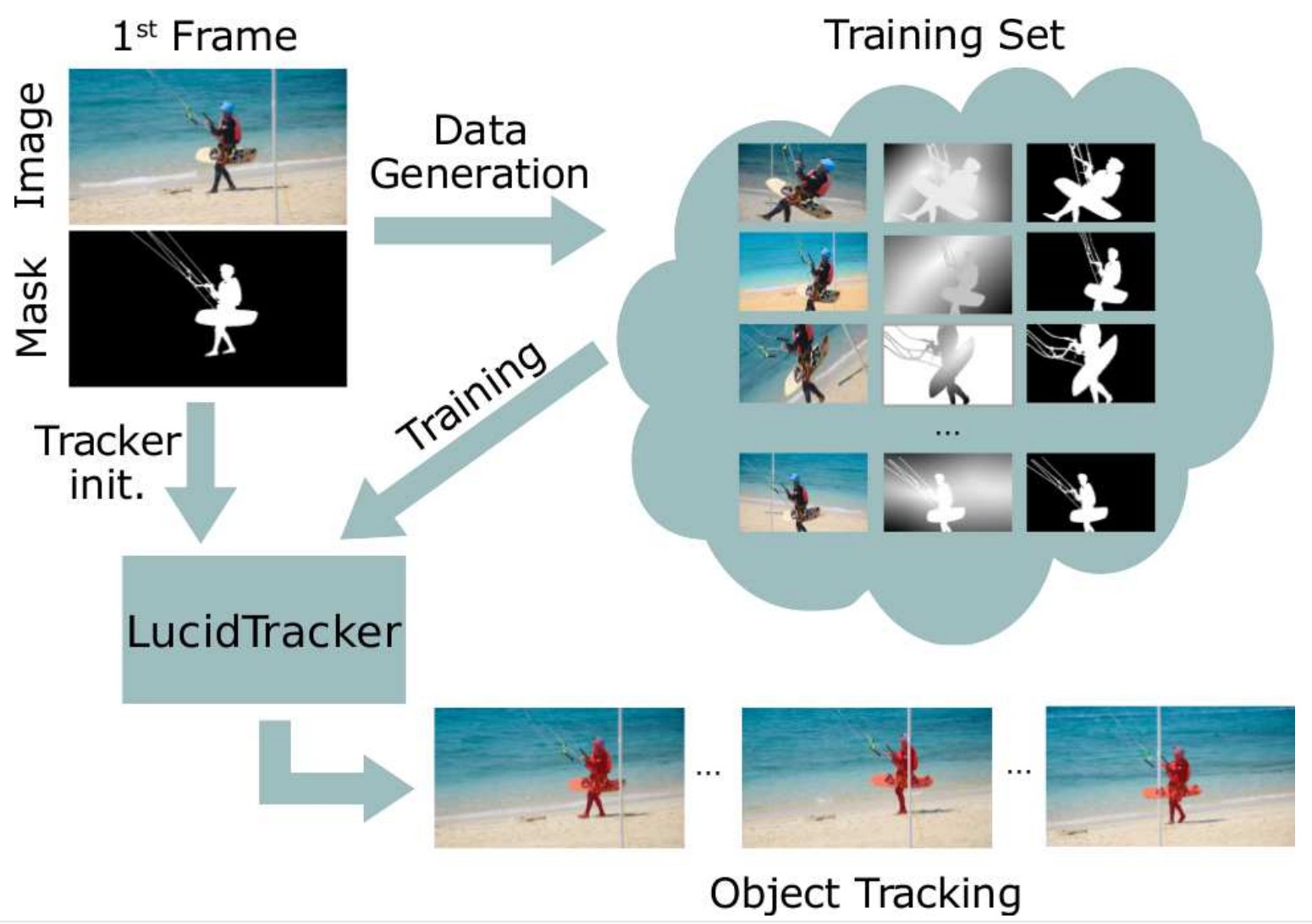
Lucid Data Dreaming pipeline
注:由于其它 DAVIS 选手,包括 #1 的团队,都引用了Lucid Dreaming,因此这里首先对 Lucid Dreaming 进行介绍.
2. 基于重识别(Re-identification) 的视频目标分割
DAVIS-2017 挑战赛第一名的工作成果 基于 MaskTrack 和 Lucid Dream,进行短时间(short-term)内的目标追踪,其新增了重识别来恢复长时间(long-term)内丢失的实例.
- [1] - 改进 MaskTrack 方法:
- base 网络是 ResNet.
- MaskTrack 采用整张图片作为网络输入,而这里只采用根据目标物体的边界框裁剪后,尺寸归一化的图像部分作为输入,提升了对于小物体目标追踪的效果.

改进的 MaskTrack 结构.
- [2] - 重识别(Re-identification)处理. 对于每一视频帧,
- 采用 Faster-RCNN 检测候选目标边界框,然后与已知实例进行对比,以采用 Joint detection and identification feature learning for person search 来检查其是否需要"恢复recovered";对于通用物体进行重新训练.
- 然后,恢复的实例被 forward 和 back propagated 到过去和未来的视频帧.

重识别过程, forward 和 backward propagation
3. 基于特定序列目标Proposals的多实例视频分割
Multiple-Instance Video Segmentation with Sequence-Specific Object Proposals.
这是基于 OSVOS 方法的排名最靠前的方法.
其思想是,从不同源生成 “object proposals”,然后采用后处理组合 proposals.
- [1] - 改进的 OSVOS 用于寻找 "object proposals".
- [2] - 对 balanced-cross-entropy loss 函数进行小改进,以更好的对小目标能够收敛.

[3] - 对第一帧的标注数据进行 Lucid-Dreaming-style 数据增强,在线训练(online training).
- [4] - 从图像实例分割方法得到语义 proposals.
- [5] - 采用 “组合分组(combinatorial grouping)” 寻找 OSVOS 给定的建议 proposals 的连接部分,然后根据 distance-based 准则来决定保留和丢弃的 proposals.
- [6] - 采用 Semantic Proposal Tracker 来进行目标追踪,并处理遮挡情况. 基于论文:Video Segmentation by Tracking Many Figure-Ground Segments,Robust Video Segment Proposals with Painless Occlusion Handling
4. DAVIS-2017 挑战赛中 CNN 的在线自适应(Online Adaptation)
onAVOS - Online Adaptation of Convolutional Neural Networks for Video Object Segmentation 已经开源了代码实现,其采用在线自适应的思想,通过采用先前分割帧上fine-tuned 的模型来分割未来的视频帧.

onAVOS 训练管道
- [1] - 采用的 base 网络为 ResNet (基于Wider or Deeper: Revisiting the ResNet Model for Visual Recognition ),在 PASCAL VOC 数据集进行模型预训练.
- [2] - 对于在线训练,采用 Lucid Data Dreaming style 对第一帧进行数据集增强.
- [3] - 因为每一帧已经分割,高置信度的前景像素进一步被作为 positive 训练样本;与最后假设的目标物体位置距离最远的像素被作为 negative 样本. 然后对新获取的数据执行另一轮微调.
- [4] - 换句话说,第二帧的分割是根据在第一帧标注数据上的 fine-tuning 得到的;第三帧的分割是根据在第二帧的预测结果上训练得到的;分割模型对每一个新视频帧保持逐步更新.
- [5] - 最终的迁移学习链比较长,类似于:base net (imagenet) → objectness net (pascal voc) → domain specific (DAVIS) → test net (video) → online adapted test net (rolling fine-tune on high confidence pixels)
从代码中发现,该作者好像更关注与实现细节,例如,支持低内存 GPUs,提供多种运行配置.
5. 结论
回归 DAVIS-2017 视频分割挑战赛的工作成果,有一些通用策略:
- 结合 MaskTrack,比较擅长于短时目标追踪,但可能会丢失某些目标物体,采用重识别(re-identification) 机制重新开始追踪.
- 结合 OSVOS,比较擅长于目标物体分割,但是难以处理极端的外观变化,采用周期的 rolling fine-tune 机制更新模型进行视频处理.
- 采用实例分割升级 OSVOS,例如语义实例分割网络.
- 采用更优的 base 网络(如 ResNet) 和 in-domain 数据增强(如,Lucid Data Dreaming.)
6. 下一步工作
一个方向是,使用记忆模块(memory modules): 不像其它视频任务,分割是一种密集问题,因此,采用 CNN 从每一帧提取稀疏特征,然后作为可分离 RNN 网络的输入的方法不能起效果. 一些有意思的工作,如,Learning Video Object Segmentation with Visual Memory 提出卷积记忆模块进行无监督视频分割. 是否可以用于半监督情况呢?
虽然是视频分割已经出现多年,但还远没有被解决. 视频分割技术对于现实场景很有帮助,精度,泛化以及最重要的是运行速度,仍有较大的提升空间. DAVIS-2017 中的一些解决方法分割单个 5 秒视频耗费的时间是小时级的,还没有达到快速的水平.
希望新开源的更简单和专注的 GyGO 电商数据集 能够吸引更多对于效率的关注,尤其是实时解决方案.
参考文献
[1] - Lucid data dreaming for object tracking. arXiv:1703.09554, 2017Papers 1–8
[2] - Video Object Segmentation with Re-identification. The 2017 DAVIS Challenge on Video Object Segmentation — CVPR Workshops, 2017
[3] - Instance Re-Identification Flow for Video Object Segmentation. The 2017 DAVIS Challenge on Video Object Segmentation — CVPR Workshops, 2017
[4] - Online Adaptation of Convolutional Neural Networks for Video Object Segmentation, BMVC 2017
[5] - DAVIS-2017 contestant papers: http://davischallenge.org/challenge2017/publications.html