论文主要通过采用 Attention Model 学习图像的多标签间的关系,然后作为多标签图像分类的空间正则项进行模型训练.
1. 摘要
多标签图像分类问题通过利用标签间的语义关联性 ,精度得到较大提高. 但由于一般情况下标签间的没有标注空间信息,故难以利用标签间的潜在空间关系.
论文提出一个统一的深度网络结构,以同时了挖掘标签间的语义和空间关联性. 给定多标签图像,提出空间正则化网络(Spatial Regularization Network, SRN),学习所有标签间的注意力图(attention maps),并通过可学习卷积挖掘标签间的潜在关系. 结合正则化分类结果和 ResNet-101 网络的分类结果,可以持续提高图像分类表现.
基于图像级标注,End-to-end 训练.
当网络模型对具有空间相关标签的图片训练后,注意力机制(attention mechanism) 自适应地关注图像的相关区域.
2. 方法
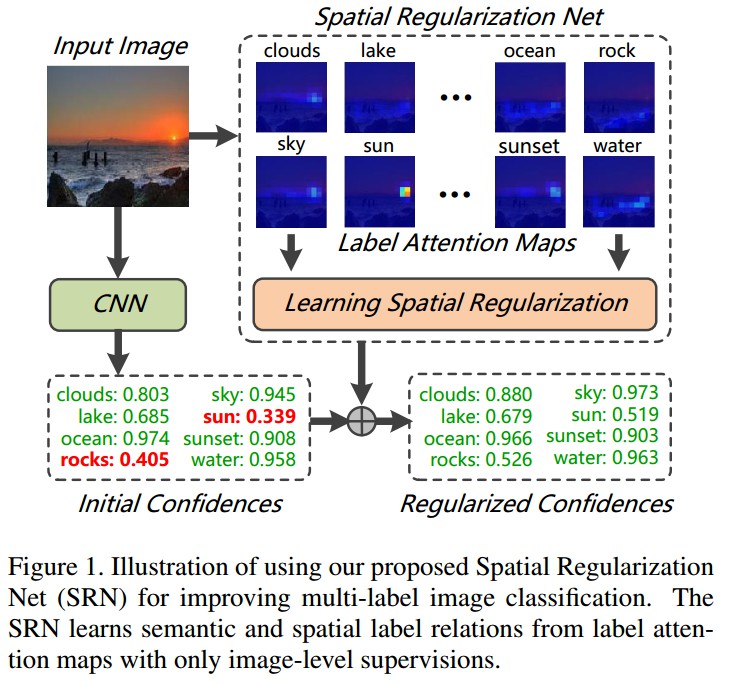
Figure1. SRN结构例示. SRN只利用图像级监督信息,从标签注意力图学习标签间的语义和空间关系.
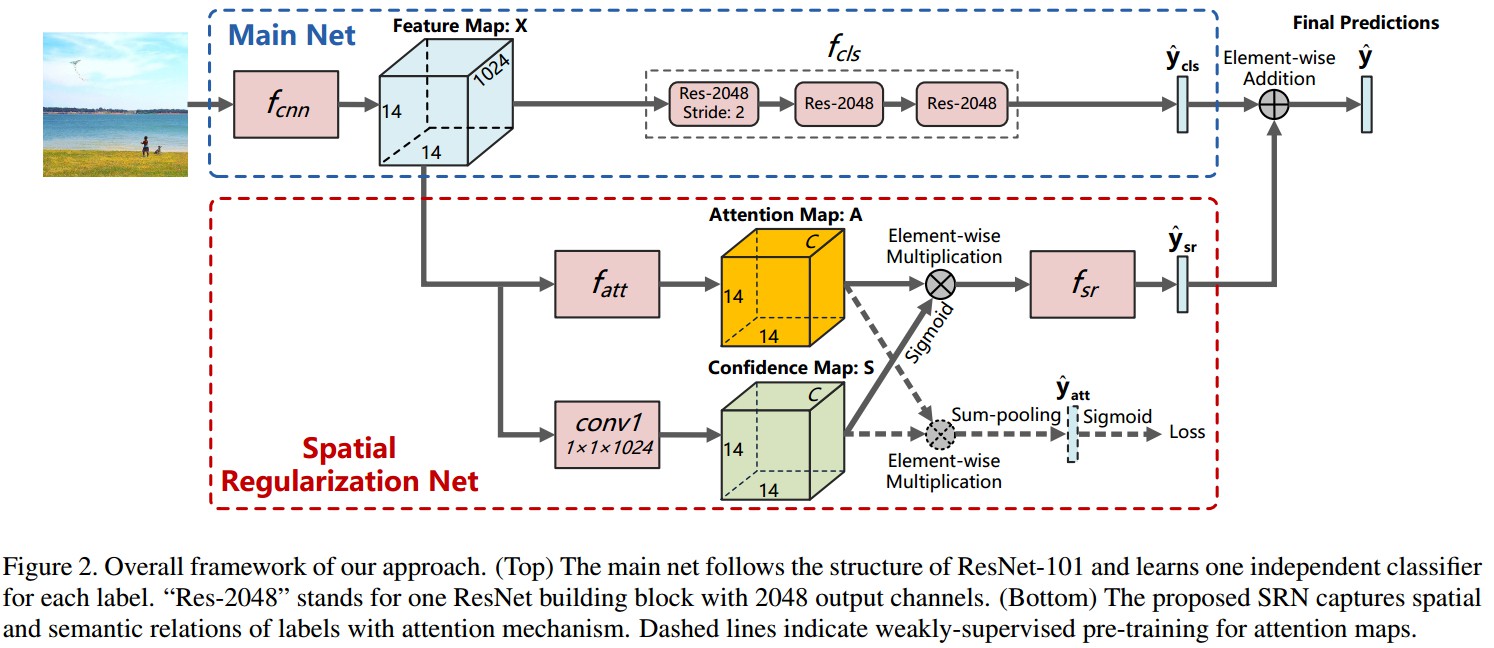
Figure2. 网络基础模型基于ResNet-101. 针对各标签分别学习得到独立的分类器. "Res-2048" 表示具有2048输出的 ResNet 网络模块. 下面红色虚线框为,SRN 采用ResNet-101的视觉特征作为输入,利用注意力机制学习得到标签间的正则空间关系. 结合主网络和SRN的分类结果得到最终的分类置信度.
当图像存在某个标签时,更多的注意力应该放在相关的区域.
标签注意力图编码了标签对应的丰富空间信息,且所有标签的加权注意力图是空间对齐的,因此采用堆积卷积操作能够容易地捕捉标签间的相对关联性.
为了能够捕捉标签间复杂空间关系,卷积应该具有足够大的接受野.
这里在不同卷积层解耦标签语义关联性学习和空间关联性学习. 直观性解释,一个标签可能只与其它标签中的一少部分语义相关,而对于语义无关的标签的注意力图进行空间关联性估计是没有必要的.

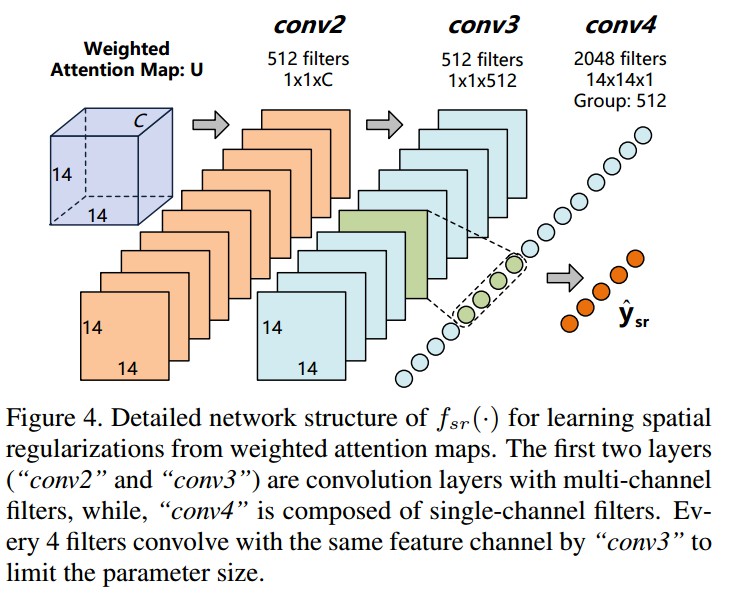
Figure4. 从加权注意力图学习空间正则因子的详细网络结构. 前两个卷积核为 1×1 的卷积层捕捉标签的语义相关性,第三个卷积层的卷积核为14×14,2048输出,学习标签间的空间关联性. 对第三个卷积层的 filters 进行分类分组,各小类具有 4 个核,对应输入特征图的一个 feature channel. 同一组下的4个核分别卷积相同的 feature channel,不同的核捕捉语义相关标签间的空间关联性.
2.1 概述
fcnn - ResNet,
输入: image, 224x224x3;
输出: feature map X, 14x14x1024
fcls - 多标签分类,Res-2048(stride=2) - Res-2048 - Res-2048
输入: feature map X, 14x14x1024
输出: 预测的标签置信度 ${ \hat{y}_{cls} }$
fatt - Attention MapsConv(512, kenel 1x1) - Conv(512, kenel 3x3) - ReLU - Conv(C, kernel 1x1) - Softmax
输入: feature map X, 14x14x1024
输出: label attention values Z, 14x14xC;最终的 label attention maps A, 14x14xC. 其中, A=Softmax(Z)
fsr - Spatial Regularizations
输入: label attention maps A, 14x14xC; confidence map S, 14x14xC (由 feature map X 经 Conv(C, kernel1x1) 得到.)
输出: weighted attention maps U, 14x14xC
${ U = \sigma(S) \circ A }$
2.2 训练
采用交叉熵cross-entropy loss.
分四个阶段:
[1] - 只训练主网络, 基于 ResNet, pretrained on ImageNet. fcnn 和 fcls.
[2] - 固定 fcnn 和 fcls, 训练 fatt.
[3] - 固定 fcnn, fcls 和 fatt, 训练 fsr.
[4] - 联合训练整个网络.
4 NVIDIA Titan X GPUs.
MS-COCO, 16 hours.
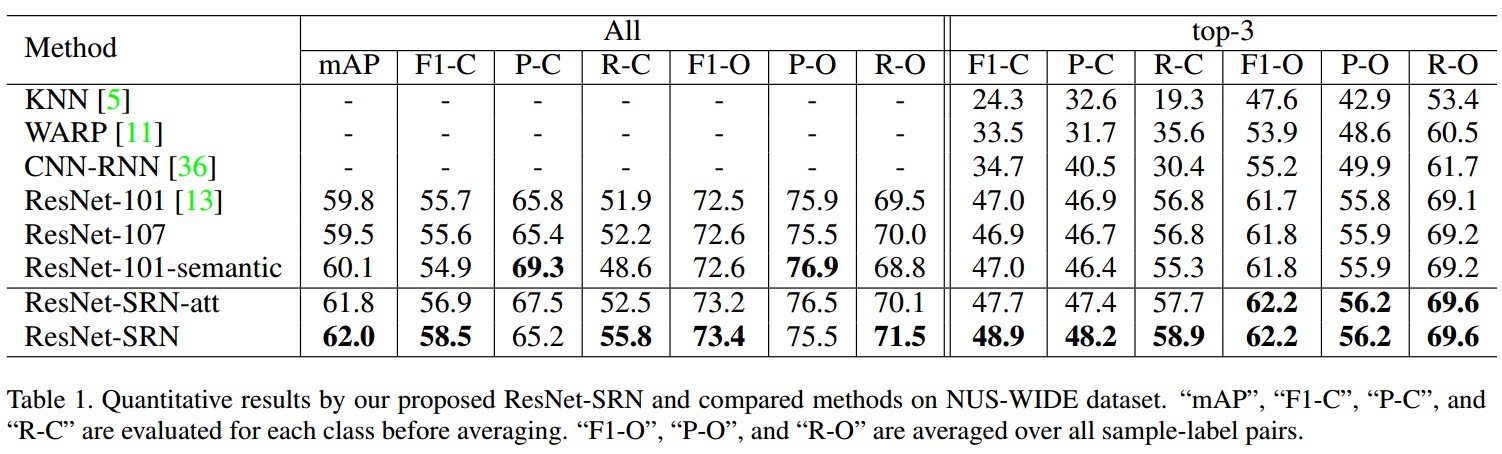
3. Results
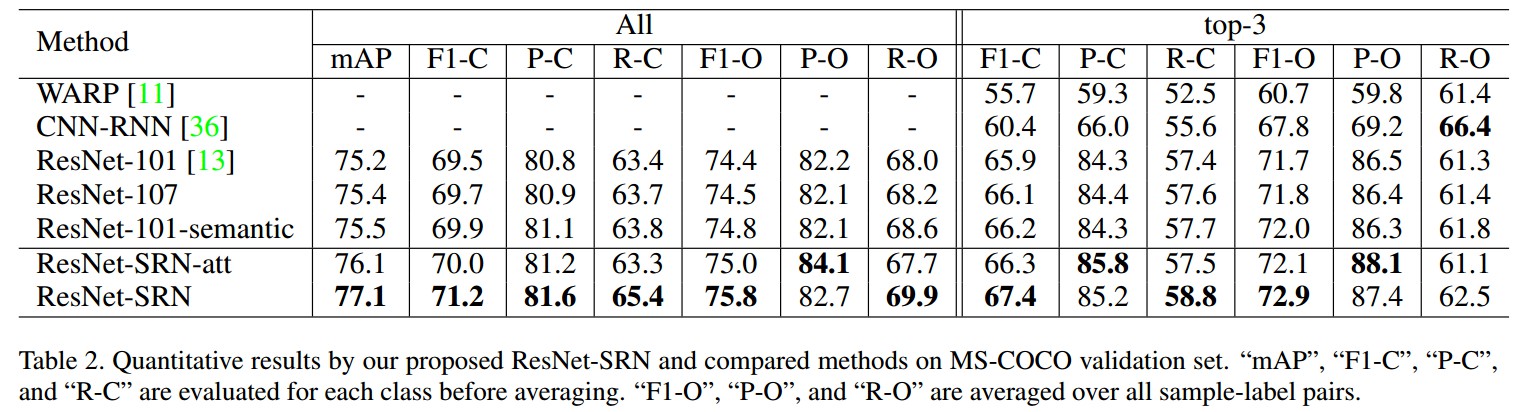
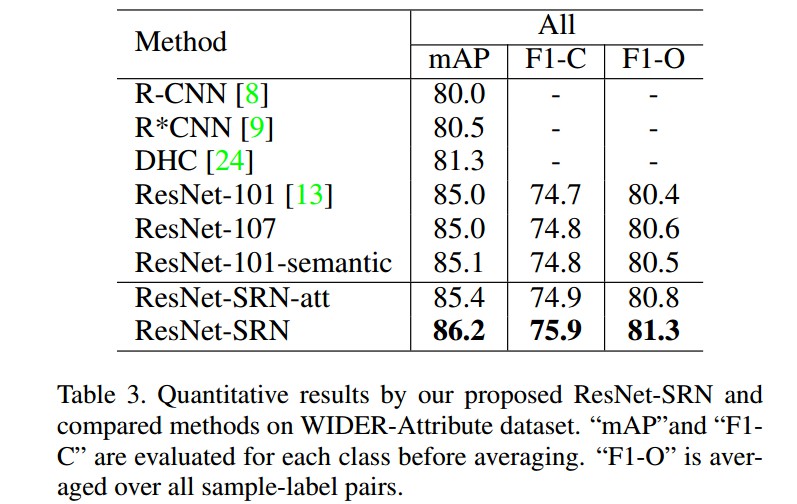


4. Related
[1] - Caffe实践 - 单标签图片分类的训练与部署
[2] - Caffe实践 - 多标签图片分类的训练与部署