阿里巴巴淘系技术部与北京大学前沿计算研究中心CVDA实验室、英国爱丁堡大学等合作,开源了业界首个大规模的多模态直播服饰检索数据集(Watch and Buy),以推动视频多模态检索技术的研究.
Watch and Buy数据集开源链接(需要发邮件申请索取):
https://tianchi.aliyun.com/dataset/dataDetail?dataId=75730
淘宝直播商品识别天池大赛(已结束)链接:https://tianchi.aliyun.com/competition/entrance/231772/introduction
1. 数据集介绍
直播带货是淘宝连接商品和消费者的重要方式,通过对直播视频中商品进行实时识别和推荐,可实现商品购买的更高效转化.
通常情况下直播对应的数百款商品之间相似程度高,且直播画面中存在大量的背景信息和灯光变化,给直播画面中商品的匹配识别带来很大的挑战. 为了提升直播中商品匹配识别的效果,依托淘宝直播海量数据,构建了业界最大规模的多模态视频商品检索数据集: Watch and Buy (WAB).
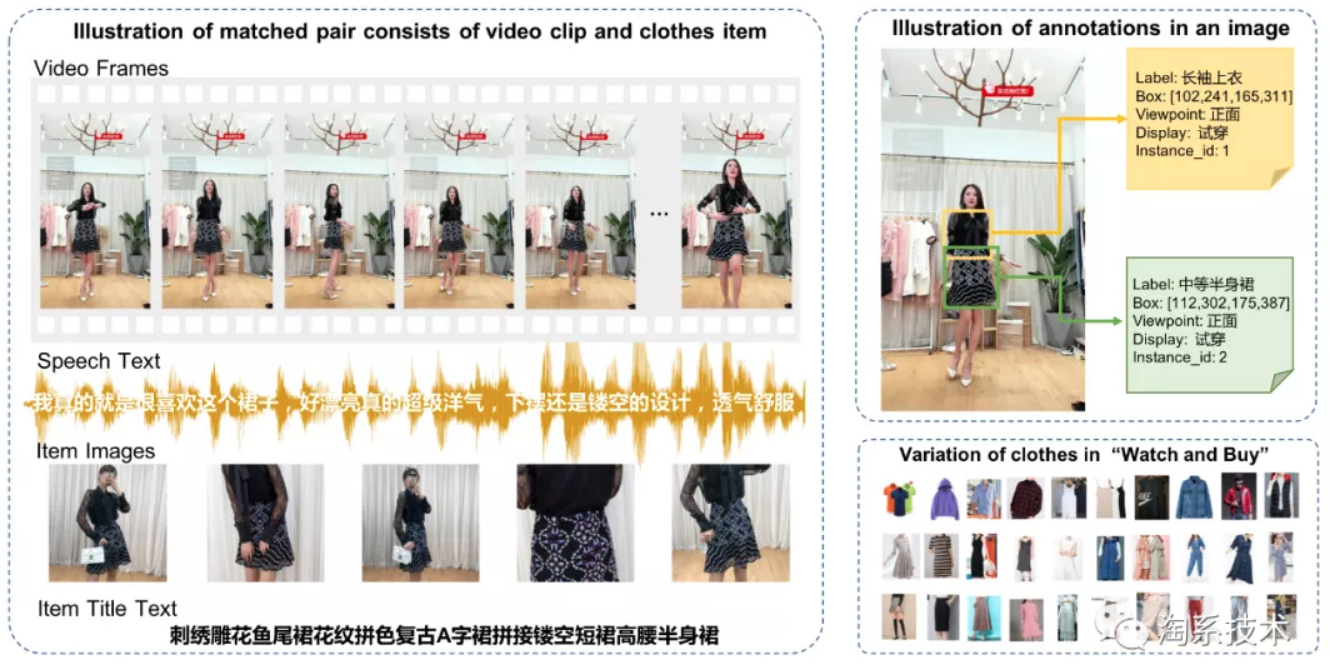
该数据集以直播视频片段和对应讲解商品匹配对的形式构成. 视频侧包括固定帧率、固定时长的视频片段,间隔两秒的关键帧图像框级标注,以及片段对应的语音转录文本;商品侧包括商品的多张商品图,全部图像的框级标注,以及商品标题描述文本.
框级标注信息丰富多样,包括商品的检测框、类别、视角、展示方式、同款编号等. 除了视觉标注,还对主播讲解语音进行了人工文本转录,同时提供了商品的标题文本信息. 该数据集可用于物体检测的算法、商品重识别算法、主播意图识别、跨模态检索和多模态检索等多种算法的研究.
与业界开源数据集对比,该数据集具有如下特点:
- 大规模:数据集包括7万对视频商品匹配对,标注图像1,042,178张,标注检测框实例1,654,780个,转录标注视频文本7万段.
- 多模态:数据集面向实际直播视频场景,既包括视频画面也包括对应的主播讲解文本,商品侧则包括商品图和商品标题文本两个模态的数据.
- 多样性:框级标注信息丰富多样,包括商品检测框、类别、视角、展示方式、实例编号等. 其中实例编号在一个视频商品匹配对的图像标注框之间起到同款标识的作用.
- 多功能:数据标注了23类服饰检测类别和检测框位置,可用于物体检测的算法研究. 数据标注了框级实例编号,构建了约8万组同款商品序列,可用于物体检索识别算法研究. 此外,数据集提供了片段对应文本和商品标题描述文本,可用于视觉文本多模态检索算法的研究.

2. 数据集统计分析
从多个维度进行了统计分析.
2.1. 标注框类目分布
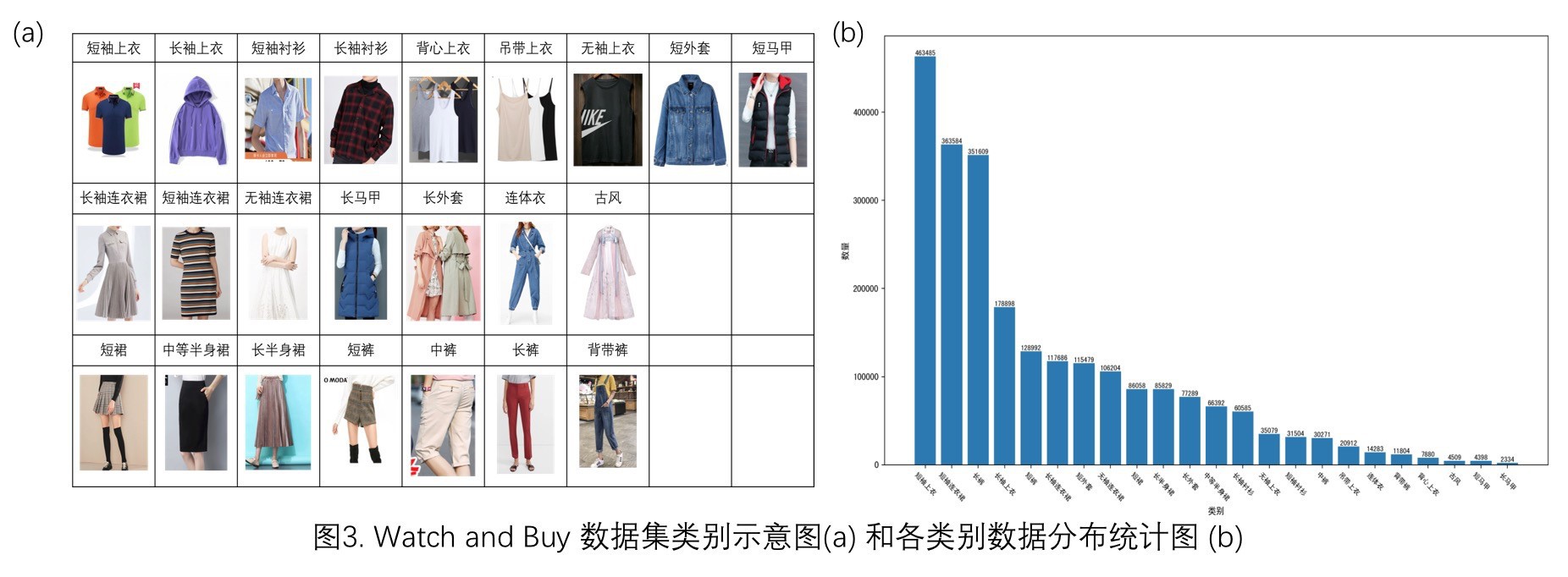
定义了23类标注类别,在148万张标注图像上总计标注236万商品检测框,服饰类别和分布图如图3所示:
2.2. 标注框统计分布
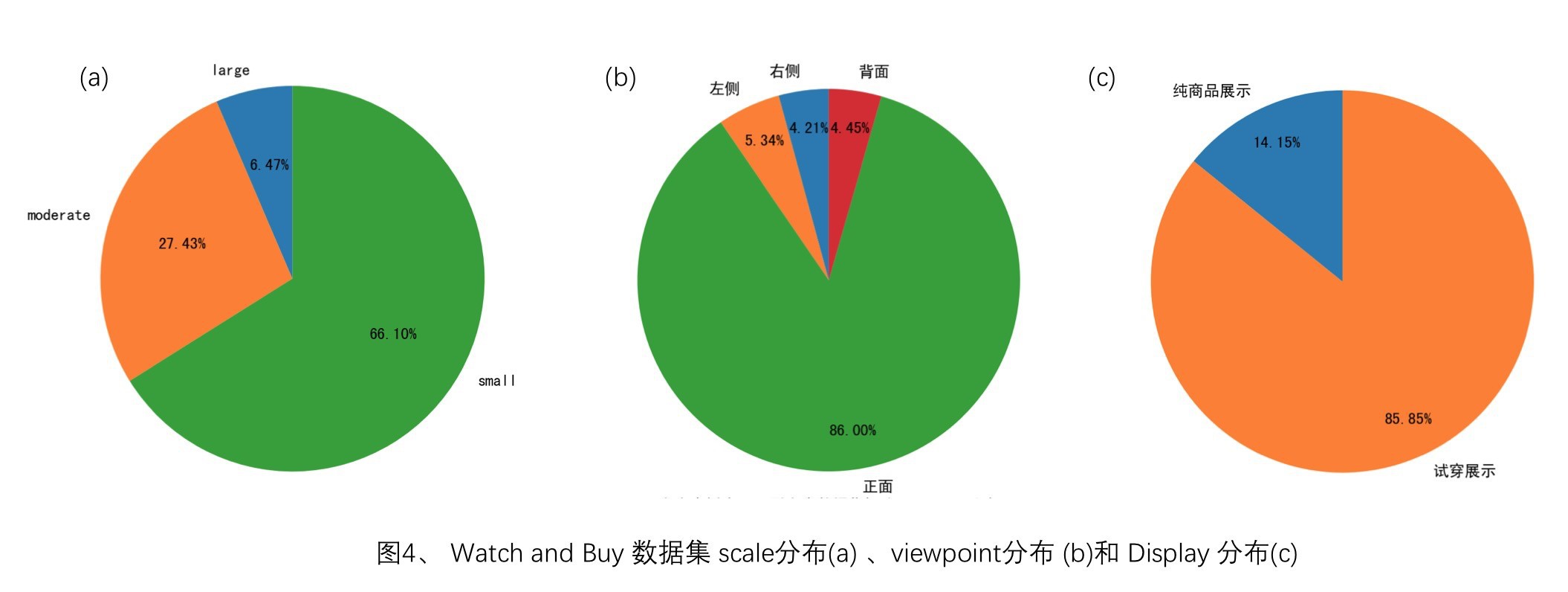
Scale分布:对于全部的商品检测框,按照标注框在整副图像中的面积占比划分为:large、moderate、small. 其中面积占比小于10%的定义为small,面积占比介于10%到40%的定义为moderate,面积占比大于40%的定义为large,分布如图4(a)所示. scale信息可以有效的应用于检测及特征训练,提升算法精度.
Viewpoint分布:在商品框标注时,标注了商品展示的视角(viewpoint: 0-正面,1-背面,2-左侧,3-右侧)信息,分布如图4(b)所示. 其中86%的商品都是以正面展示为主. 在商品识别阶段引入视角信息,避免不同视角的商品误匹配可以有效提升识别精度.
Display分布:在商品框标注时,标注了商品的展示方式(display: 0-纯商品展示,1-试穿展示)信息,分布如图4( c )所示. 纯商品展示至渲染商品图、主播手提展示等情况,试穿展示指模特或者主播试穿展示.
参考
[1] - 阿里巴巴淘系开源首个多模态直播服饰检索数据集 - 2020.07.20
附:

2 comments
你好,这个数据集现在还能申请吗,license怎么才能搞到?
应该是可以的,license 可能需要填一下表格