原文:Multi-Label Image Classification with PyTorch - 2020.04.04
作者:Dmitry Retinskiy (Xperience.AI)
实现:Github - PyTorch-Multi-Label-Image-Classification
自从 2012 年 ImageNet 竞赛中神经网络第一次赢得比赛, Alex Krizhevsky, Ilya Sutskever 和 Geoffrey Hinton 彻底改变了图像分类领域.
如今,图像的单标签任务(即,图像识别),已经被广泛研究和解决. 然而,现实场景中,往往不局限于“每张图片仅有一个标签” 的任务,某些时候,每张图片会有更多标签.
对此,这里研究的是多输出图像分类(multi-output classification) 或图像标注(image tagging).
1. 多标签分类的场景
在图像分类领域中,可能会遇到这样的场景:判断目标的集中属性. 例如,类别、颜色、尺寸、等等. 相比较于传统图像分类,其输出将会包含2个及以上的属性.
这里关注的问题是,提前已知属性的数量(the number of the properties). 这种任务被称为多输出分类. 实际上,其是多标签分类(multi-label classification)的一种特殊形式,后者处理的也是预测几种属性,但其数量对于每个样本可能都是不同的.
2. 数据集
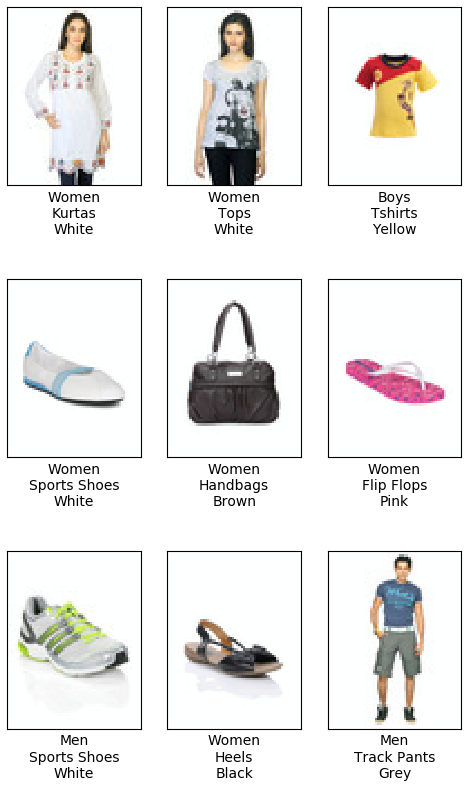
Kaggle - Fashion Product Images. 其共有超过 44000 张服装图像,每个图像包含有 9 个标签. 这里仅采用三个标签:gender, articleType 和 baseColour. 示例如下:

数据提取后,分布情况为:
[1] - 5 个 gender 标签:Boys, Girls, Men, Unisex, Women
[2] - 47 种 colors
[3] - 143 种类目,如Sports Sandals, Wallets, Sweaters.
基于该数据集,下面会创建神经网络模型,并进行训练,预测数据集中图片的三种标签(gender, article, and color).
2.1. 数据集划分
数据集共采用 40000 张图像,其中 320000 训练数据集,8000 测试数据集.
split_data.py:
import argparse
import csv
import os
import numpy as np
from PIL import Image
from tqdm import tqdm
def save_csv(data, path,
fieldnames=['image_path',
'gender',
'articleType',
'baseColour']):
with open(path, 'w', newline='') as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
writer.writeheader()
for row in data:
writer.writerow(dict(zip(fieldnames, row)))
def split_data():
input_folder = "fashion-product-images"
output_folder = "fashion-product-images"
annotation = os.path.join(input_folder, 'styles.csv')
# open annotation file
all_data = []
with open(annotation) as csv_file:
reader = csv.DictReader(csv_file)
# each row in the CSV file corresponds to the image
for row in tqdm(reader, total=reader.line_num):
# we need image ID to build the path to the image file
img_id = row['id']
#
gender = row['gender']
articleType = row['articleType']
baseColour = row['baseColour']
img_name = os.path.join(input_folder, 'images', str(img_id) + '.jpg')
if os.path.exists(img_name):
# check if the image has 80*60 pixels with 3 channels
img = Image.open(img_name)
if img.size == (60, 80) and img.mode == "RGB":
all_data.append([img_name, gender, articleType, baseColour])
# for reproduce the results
np.random.seed(42)
# construct a Numpy array from the list
all_data = np.asarray(all_data)
# Take 40000 samples in random order
inds = np.random.choice(40000, 40000, replace=False)
# split the data into train/val and save them as csv files
save_csv(all_data[inds][:32000], os.path.join(output_folder, 'train.csv'))
save_csv(all_data[inds][32000:40000], os.path.join(output_folder, 'val.csv'))
if __name__ == '__main__':
split_data()3. 构建模型
3.1. 数据加载
由于每张图片不止一个标注标签,因此需要调整数据读取和加载到内存的方式.
创建继承自 PyTorch Dataset 的函数类,以便于解析标注数据,并提取标签. multi-output 分类和 single-class 分类的关键区别是:返回数据集中每个样本的多个标签.
dataset.py:
import csv
import numpy as np
from PIL import Image
from torch.utils.data import Dataset
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
class AttributesDataset():
def __init__(self, annotation_path):
color_labels = []
gender_labels = []
article_labels = []
with open(annotation_path) as f:
reader = csv.DictReader(f)
for row in reader:
color_labels.append(row['baseColour'])
gender_labels.append(row['gender'])
article_labels.append(row['articleType'])
self.color_labels = np.unique(color_labels)
self.gender_labels = np.unique(gender_labels)
self.article_labels = np.unique(article_labels)
self.num_colors = len(self.color_labels)
self.num_genders = len(self.gender_labels)
self.num_articles = len(self.article_labels)
self.color_id_to_name = dict(zip(range(len(self.color_labels)), self.color_labels))
self.color_name_to_id = dict(zip(self.color_labels, range(len(self.color_labels))))
self.gender_id_to_name = dict(zip(range(len(self.gender_labels)), self.gender_labels))
self.gender_name_to_id = dict(zip(self.gender_labels, range(len(self.gender_labels))))
self.article_id_to_name = dict(zip(range(len(self.article_labels)), self.article_labels))
self.article_name_to_id = dict(zip(self.article_labels, range(len(self.article_labels))))
#
class FashionDataset(Dataset):
def __init__(self, annotation_path, attributes, transform=None):
super().__init__()
self.transform = transform
self.attr = attributes
# initialize the arrays to store the ground truth labels and paths to the images
self.data = []
self.color_labels = []
self.gender_labels = []
self.article_labels = []
# read the annotations from the CSV file
with open(annotation_path) as f:
reader = csv.DictReader(f)
for row in reader:
self.data.append(row['image_path'])
self.color_labels.append(self.attr.color_name_to_id[row['baseColour']])
self.gender_labels.append(self.attr.gender_name_to_id[row['gender']])
self.article_labels.append(self.attr.article_name_to_id[row['articleType']])
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
# take the data sample by its index
img_path = self.data[idx]
img = Image.open(img_path)
#
if self.transform:
img = self.transform(img)
# return the image and all the associated labels
dict_data = {
'img': img,
'labels': {
'color_labels': self.color_labels[idx],
'gender_labels': self.gender_labels[idx],
'article_labels': self.article_labels[idx]
}
}
return dict_data 3.2. 数据增强
数据增强和随机变换,有助于避免网络训练时的过拟合问题.
训练阶段主要采用:random flipping, slight color modifications, rotation, scaling, 和 translation (unified in an affine transformation).
此外,在加载进网络前,进行数据归一化.
train_transform = transforms.Compose([
transforms.RandomHorizontalFlip(p=0.5),
transforms.ColorJitter(brightness=0.3, contrast=0.3, saturation=0.3, hue=0),
transforms.RandomAffine(degrees=20, translate=(0.1, 0.1), scale=(0.8, 1.2),
shear=None, resample=False, fillcolor=(255, 255, 255)),
transforms.ToTensor(),
transforms.Normalize(mean, std)
])验证阶段,不对数据进行随机化处理,仅归一化及格式转换操作:
val_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean, std)
])3.3. 模型构建
首先是模型类定义. 以 torchvision.models 中的 mobilenet_v2 为例. mobilenet_v2 是单标签分类器.
为了适应 multi-output 任务,调整 mobilenet_v2 网络,以同时预测三种属性,其 head 网络分别为:color,gender 和 article. 每个 head 分别接对应的 cross-entropy loss. 如图:

具体实现为 - model.py:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.models as models
class MultiOutputModel(nn.Module):
def __init__(self,
n_color_classes,
n_gender_classes,
n_article_classes):
super().__init__()
# take the model without classifier
self.base_model = models.mobilenet_v2().features
# size of the layer before classifier
last_channel = models.mobilenet_v2().last_channel
# the input for the classifier should be two-dimensional, but we will have
# [batch_size, channels, width, height]
# so, let's do the spatial averaging: reduce width and height to 1
self.pool = nn.AdaptiveAvgPool2d((1, 1))
# create separate classifiers for our outputs
self.color = nn.Sequential(
nn.Dropout(p=0.2),
nn.Linear(in_features=last_channel, out_features=n_color_classes)
)
self.gender = nn.Sequential(
nn.Dropout(p=0.2),
nn.Linear(in_features=last_channel, out_features=n_gender_classes)
)
self.article = nn.Sequential(
nn.Dropout(p=0.2),
nn.Linear(in_features=last_channel, out_features=n_article_classes)
)
def forward(self, x):
x = self.base_model(x)
x = self.pool(x)
# reshape from [batch, channels, 1, 1] to [batch, channels] to put it into classifier
x = torch.flatten(x, 1)
return {
'color': self.color(x),
'gender': self.gender(x),
'article': self.article(x)
}
def get_loss(self, net_output, ground_truth):
color_loss = F.cross_entropy(net_output['color'], ground_truth['color_labels'])
gender_loss = F.cross_entropy(net_output['gender'], ground_truth['gender_labels'])
article_loss = F.cross_entropy(net_output['article'], ground_truth['article_labels'])
loss = color_loss + gender_loss + article_loss
return loss, {'color': color_loss,
'gender': gender_loss,
'article': article_loss}3.4. 模型训练
multi-output 分类网络的训练与 single-output 分类任务是相同的,具体可参考:
首先定义几个辅助函数:
import matplotlib.pyplot as plt
#
def visualize_gt_data(dataset, attributes):
imgs = []
gt_labels = []
n_cols = 5
n_rows = 3
# store the original transforms from the dataset
transforms = dataset.transform
# and not use them during visualization
dataset.transform = None
for img_idx in range(n_cols * n_rows):
sample = dataset[img_idx]
img = sample['img']
labels = sample['labels']
gt_color = attributes.color_id_to_name[labels['color_labels']]
gt_gender = attributes.gender_id_to_name[labels['gender_labels']]
gt_article = attributes.article_id_to_name[labels['article_labels']]
imgs.append(img)
gt_labels.append("{}\n{}\n{}".format(gt_gender, gt_article, gt_color))
title = "Ground truth labels"
fig, axs = plt.subplots(n_rows, n_cols, figsize=(10, 10))
axs = axs.flatten()
for img, ax, label in zip(imgs, axs, gt_labels):
ax.set_xlabel(label, rotation=0)
ax.get_xaxis().set_ticks([])
ax.get_yaxis().set_ticks([])
ax.imshow(img)
plt.suptitle(title)
plt.tight_layout()
plt.show()
# restore original transforms
dataset.transform = transforms具体实现如 - train.py:
import argparse
import os
from datetime import datetime
import torch
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
def get_cur_time():
return datetime.strftime(datetime.now(), '%Y-%m-%d_%H-%M')
def checkpoint_save(model, name, epoch):
f = os.path.join(name, 'checkpoint-{:06d}.pth'.format(epoch))
torch.save(model.state_dict(), f)
print('Saved checkpoint:', f)
return f
def train(start_epoch=1, N_epochs=50, batch_size=16, num_workers=8):
attributes_file = 'fashion-product-images/styles.csv'
device = torch.device('cuda')
# attributes variable contains labels for the categories in the dataset and mapping between string names and IDs
attributes = AttributesDataset(attributes_file)
# specify image transforms for augmentation during training
train_transform = transforms.Compose([
transforms.RandomHorizontalFlip(p=0.5),
transforms.ColorJitter(brightness=0.3, contrast=0.3, saturation=0.3, hue=0),
transforms.RandomAffine(degrees=20, translate=(0.1, 0.1), scale=(0.8, 1.2),
shear=None, resample=False, fillcolor=(255, 255, 255)),
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
# during validation we use only tensor and normalization transforms
val_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
train_dataset = FashionDataset('fashion-product-images/train.csv', attributes, train_transform)
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers)
val_dataset = FashionDataset('fashion-product-images/val.csv', attributes, val_transform)
val_dataloader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, num_workers=num_workers)
model = MultiOutputModel(n_color_classes=attributes.num_colors,
n_gender_classes=attributes.num_genders,
n_article_classes=attributes.num_articles)\
.to(device)
optimizer = torch.optim.Adam(model.parameters())
logdir = os.path.join('logs', get_cur_time())
print(logdir)
savedir = os.path.join('checkpoints', get_cur_time())
print(savedir)
os.makedirs(logdir, exist_ok=False)
os.makedirs(savedir, exist_ok=False)
logger = SummaryWriter(logdir)
n_train_samples = len(train_dataloader)
visualize_gt_data(val_dataset, attributes)
print("\nAll gender labels:\n", attributes.gender_labels)
print("\nAll color labels:\n", attributes.color_labels)
print("\nAll article labels:\n", attributes.article_labels)
print("Starting training ...")
checkpoint_path = None
for epoch in range(start_epoch, N_epochs + 1):
total_loss = 0
accuracy_color = 0
accuracy_gender = 0
accuracy_article = 0
for batch in train_dataloader:
optimizer.zero_grad()
img = batch['img']
target_labels = batch['labels']
target_labels = {t: target_labels[t].to(device) for t in target_labels}
output = model(img.to(device))
loss_train, losses_train = model.get_loss(output, target_labels)
total_loss += loss_train.item()
batch_accuracy_color, batch_accuracy_gender, batch_accuracy_article = \
calculate_metrics(output, target_labels)
accuracy_color += batch_accuracy_color
accuracy_gender += batch_accuracy_gender
accuracy_article += batch_accuracy_article
loss_train.backward()
optimizer.step()
print("epoch {:4d}, loss: {:.4f}, color: {:.4f}, gender: {:.4f}, article: {:.4f}".format(
epoch,
total_loss / n_train_samples,
accuracy_color / n_train_samples,
accuracy_gender / n_train_samples,
accuracy_article / n_train_samples))
logger.add_scalar('train_loss', total_loss / n_train_samples, epoch)
if epoch % 25 == 0:
checkpoint_path = checkpoint_save(model, savedir, epoch)
if epoch % 5 == 0:
validate(model, val_dataloader, device, logger, epoch)
checkpoint_path = checkpoint_save(model, savedir, epoch - 1)
return checkpoint_path3.5. 模型验证
首先,回顾下 single-output 分类任务中度量标准 - 准确度(accuracy),其计算比较简单,所有数据中,模型所正确预测的结果.
$$ accuracy = \frac{correct \ predictions}{dataset \ size} $$
那么,对于 multi-output 分类任务呢,仍然是可以使用准确度作为度量标准的. 只需每个输出单独计算.
import warnings
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay, accuracy_score
def calculate_metrics(output, target):
_, predicted_color = output['color'].cpu().max(1)
gt_color = target['color_labels'].cpu()
_, predicted_gender = output['gender'].cpu().max(1)
gt_gender = target['gender_labels'].cpu()
_, predicted_article = output['article'].cpu().max(1)
gt_article = target['article_labels'].cpu()
with warnings.catch_warnings(): # sklearn may produce a warning when processing zero row in confusion matrix
warnings.simplefilter("ignore")
accuracy_color = accuracy_score(y_true=gt_color.numpy(), y_pred=predicted_color.numpy())
accuracy_gender = accuracy_score(y_true=gt_gender.numpy(), y_pred=predicted_gender.numpy())
accuracy_article = accuracy_score(y_true=gt_article.numpy(), y_pred=predicted_article.numpy())
return accuracy_color, accuracy_gender, accuracy_article
##
def checkpoint_load(model, name):
print('Restoring checkpoint: {}'.format(name))
model.load_state_dict(torch.load(name, map_location='cpu'))
epoch = int(os.path.splitext(os.path.basename(name))[0].split('-')[1])
return epoch
def net_output_to_predictions(output):
_, predicted_colors = output['color'].cpu().max(1)
_, predicted_genders = output['gender'].cpu().max(1)
_, predicted_articles = output['article'].cpu().max(1)
return predicted_colors.numpy().tolist(), predicted_genders.numpy().tolist(), predicted_articles.numpy().tolist()
def validate(model, dataloader, device, logger=None, epoch=None, checkpoint=None):
if checkpoint is not None:
checkpoint_load(model, checkpoint)
model.eval()
color_predictions = []
gender_predictions = []
article_predictions = []
with torch.no_grad():
avg_loss = 0
accuracy_color = 0
accuracy_gender = 0
accuracy_article = 0
for batch in dataloader:
img = batch['img']
target_labels = batch['labels']
target_labels = {t: target_labels[t].to(device) for t in target_labels}
output = model(img.to(device))
val_train, val_train_losses = model.get_loss(output, target_labels)
avg_loss += val_train.item()
batch_accuracy_color, batch_accuracy_gender, batch_accuracy_article = \
calculate_metrics(output, target_labels)
accuracy_color += batch_accuracy_color
accuracy_gender += batch_accuracy_gender
accuracy_article += batch_accuracy_article
(batch_color_predictions,
batch_gender_predictions,
batch_article_predictions) = net_output_to_predictions(output)
color_predictions.extend(batch_color_predictions)
gender_predictions.extend(batch_gender_predictions)
article_predictions.extend(batch_article_predictions)
n_samples = len(dataloader)
avg_loss /= n_samples
accuracy_color /= n_samples
accuracy_gender /= n_samples
accuracy_article /= n_samples
print('-' * 72)
print("Validation loss: {:.4f}, color: {:.4f}, gender: {:.4f}, article: {:.4f}\n".format(
avg_loss, accuracy_color, accuracy_gender, accuracy_article))
if logger is not None and epoch is not None:
logger.add_scalar("val_loss", avg_loss, epoch)
logger.add_scalar("val_accuracy/color", accuracy_color, epoch)
logger.add_scalar("val_accuracy/gender", accuracy_gender, epoch)
logger.add_scalar("val_accuracy/article", accuracy_article, epoch)
model.train()
return color_predictions, gender_predictions, article_predictions3.6. 模型评价
混淆矩阵.
test.py:
import argparse
import os
import numpy as np
import torch
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
def visualize_grid(dataset, attributes, color_predictions, gender_predictions, article_predictions):
imgs = []
labels = []
predicted_color_all = []
predicted_gender_all = []
predicted_article_all = []
gt_labels = []
gt_color_all = []
gt_gender_all = []
gt_article_all = []
# store the original transforms from the dataset
transforms = dataset.transform
# and not use them during visualization
dataset.transform = None
for (sample,
predicted_color,
predicted_gender,
predicted_article) in zip(
dataset, color_predictions, gender_predictions, article_predictions):
predicted_color = attributes.color_id_to_name[predicted_color]
predicted_gender = attributes.gender_id_to_name[predicted_gender]
predicted_article = attributes.article_id_to_name[predicted_article]
gt_color = attributes.color_id_to_name[sample['labels']['color_labels']]
gt_gender = attributes.gender_id_to_name[sample['labels']['gender_labels']]
gt_article = attributes.article_id_to_name[sample['labels']['article_labels']]
predicted_color_all.append(predicted_color)
predicted_gender_all.append(predicted_gender)
predicted_article_all.append(predicted_article)
gt_color_all.append(gt_color)
gt_gender_all.append(gt_gender)
gt_article_all.append(gt_article)
imgs.append(sample['img'])
labels.append("{}\n{}\n{}".format(predicted_gender, predicted_article, predicted_color))
gt_labels.append("{}\n{}\n{}".format(gt_gender, gt_article, gt_color))
# restore original transforms
dataset.transform = transforms
# Draw confusion matrices
# color
cn_matrix = confusion_matrix(
y_true=gt_color_all,
y_pred=predicted_color_all,
labels=attributes.color_labels,
normalize='true')
plt.rcParams.update({'font.size': 5})
plt.rcParams.update({'figure.dpi': 300})
ConfusionMatrixDisplay(cn_matrix, attributes.color_labels).plot(
include_values=False, xticks_rotation='vertical')
plt.title("Colors")
plt.tight_layout()
plt.show()
# gender
cn_matrix = confusion_matrix(
y_true=gt_gender_all,
y_pred=predicted_gender_all,
labels=attributes.gender_labels,
normalize='true')
ConfusionMatrixDisplay(cn_matrix, attributes.gender_labels).plot(
xticks_rotation='horizontal')
plt.title("Genders")
plt.tight_layout()
plt.show()
plt.rcParams.update({'font.size': 2.5})
cn_matrix = confusion_matrix(
y_true=gt_article_all,
y_pred=predicted_article_all,
labels=attributes.article_labels,
normalize='true')
ConfusionMatrixDisplay(cn_matrix, attributes.article_labels).plot(
include_values=False, xticks_rotation='vertical')
plt.title("Article types")
plt.show()
plt.rcParams.update({'font.size': 5})
plt.rcParams.update({'figure.dpi': 100})
title = "Predicted labels"
n_cols = 5
n_rows = 3
fig, axs = plt.subplots(n_rows, n_cols, figsize=(10, 10))
axs = axs.flatten()
for img, ax, label in zip(imgs, axs, labels):
ax.set_xlabel(label, rotation=0)
ax.get_xaxis().set_ticks([])
ax.get_yaxis().set_ticks([])
ax.imshow(img)
plt.suptitle(title)
plt.tight_layout()
plt.show()
#
def test(checkpoint_path):
attributes_file = 'fashion-product-images/styles.csv'
device = torch.device("cuda")
# attributes variable contains labels for the categories in the dataset and mapping between string names and IDs
attributes = AttributesDataset(attributes_file)
# during validation we use only tensor and normalization transforms
val_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
test_dataset = FashionDataset('fashion-product-images/val.csv', attributes, val_transform)
test_dataloader = DataLoader(test_dataset, batch_size=16, shuffle=False, num_workers=8)
model = MultiOutputModel(n_color_classes=attributes.num_colors, n_gender_classes=attributes.num_genders,
n_article_classes=attributes.num_articles).to(device)
model_predictions = validate(model, test_dataloader, device, checkpoint=checkpoint_path)
# Visualization of the trained model
visualize_grid(test_dataset, attributes, *model_predictions)\
if __name__ == '__main__':
test(last_checkpoint_path)测试结果示例:
color混淆矩阵如下:
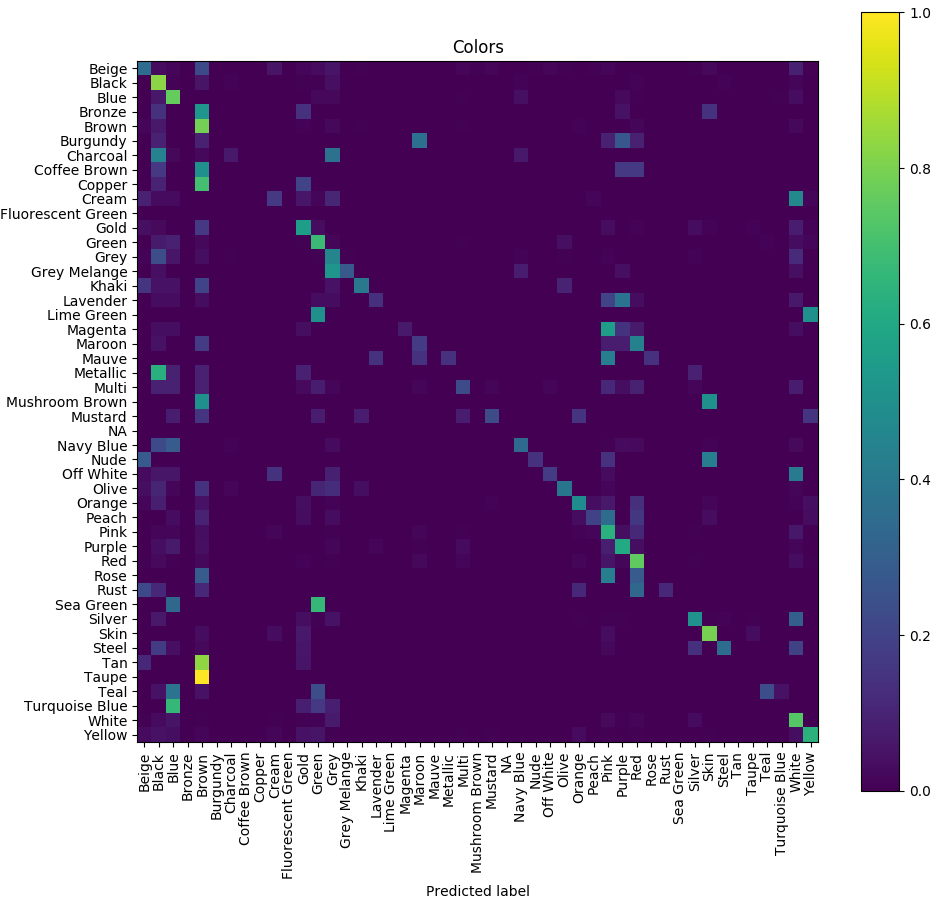
可以看出模型对于比较相似的颜色产生了混淆,例如:magenta, pink 和 purple,即使对于人而言,也很难识别数据集中的47种颜色. 比如,

因此,对于颜色来说,低准确度不是大问题的. 如果项解决该问题,只需减少数据集中的颜色种类数,例如,10 种,重新将相似颜色合并为一个类,然后再次训练模型. 应该就可以得到更好的结果.
gender 混淆矩阵如下:
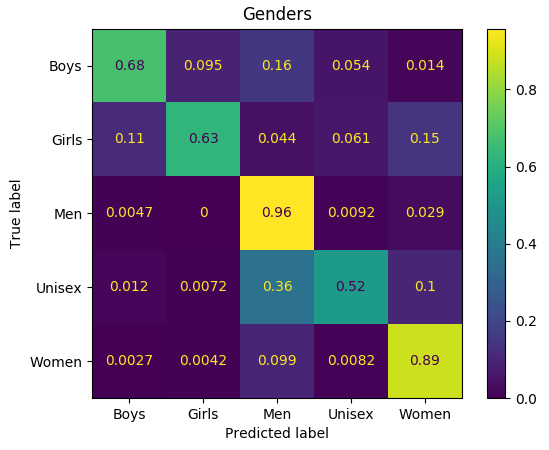
可以看出,模型混淆了 ‘girls’ 和 ‘women’ 、“men” 和 “unisex” 标签. 同样的,对于人而言,这些都可能很难区分.

clothes 和 accessories 的混淆矩阵如下:
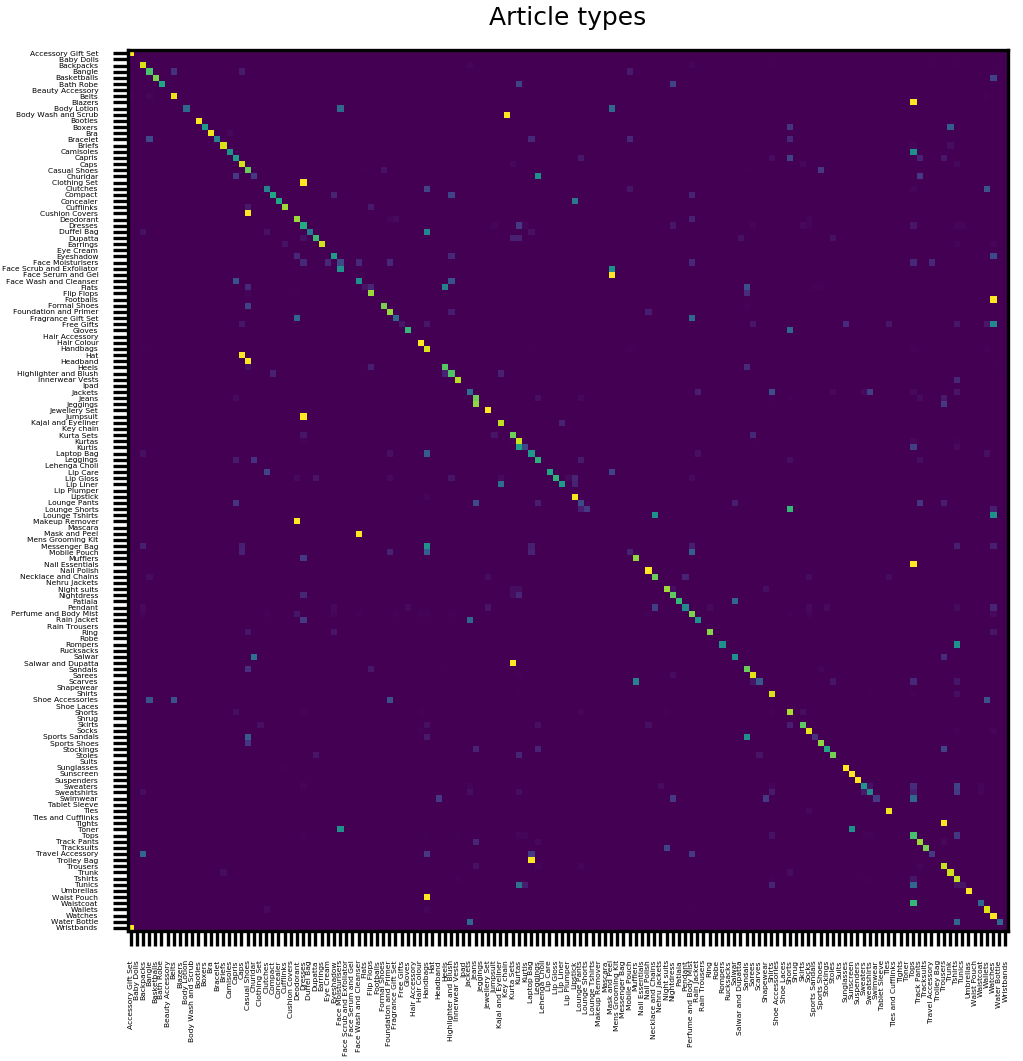
某些类目确实是难以区分,比如下面的两个 bags:

4. 总结
这里主要是对基于 single-output 模型进行 multi-output 模型的构建进行介绍. 此外,还介绍了基于混淆矩阵的模型预测结果的验证.
One comment
大佬,可以出一个视频嘛,哭了哭了