原文:当达摩院大牛学会抠图,这一切都不受控制了 - 2019.12.31
出处:阿里云云栖号
作者:机器智能技术
在外界人眼中,达摩院人才济济,大多是奇人异士,做着神秘且高端的研究,有如扫地僧一般的存在,但是如果有一天,当神秘专家不再神秘,你发现他们也开始玩抠图,且这一切都朝着不受控制的方向发展了的时候,那么抠他们能玩出哪些花样?
图片抠图:

部分图片来源淘宝商品图
视频抠图:
1. 为什么开始研究抠图
这要从阿里巴巴智能设计实验室自主研发的一款设计产品鹿班说起.
鹿班的初衷是改变传统的设计模式,使其在短时间内完成大量banner图、海报图和会场图的设计,提高工作效率. 商家上传的宝贝图参差不齐,直接投放效果不佳,通过鹿班制图可以保证会场风格统一、高质视觉效果传达,从而提升商品吸引力和买家视觉体验,达到提升商品转化率的目的.
而在制图的过程中,我们发现商品抠图是一项不可避免且繁琐的工作,一张人像精细抠图平均需要耗费设计师2h以上的时间,这样无需创意的纯体力工作亟需被AI所取代,我们的抠图算法应运而生.
近几年图像抠图算法逐渐进入人们的视野,如腾讯(天天P图)、百度(人像抠图、汽车分割)等. 而潜藏在其背后的行业:泛文娱,电商行业、垂直行业,诸如在线餐饮、媒体、教育等行业商业价值不容小觑,可以满足各种战报、在线课程教师抠图、视频封面制作等不同形式的图片制作需求拓展. 市面上的一些抠图算法效果在人像发丝细节处理均不是很好,且对一些通用场景(电商等)支持也不是很好. 我们针对这两个问题一方面设计更具有泛化能力的系统、一方面深化发丝和高度镂空相关算法,均有更好的效果.
2. 遇到的难题和解决方案
最开始在上手鹿班“批量抠图”需求时,发现用户上传的图像质量、来源、内容五花八门,想用一个模型实现业务效果达到一劳永逸很难. 在经过对场景和数据的大量分析后,定制整体框架如下:
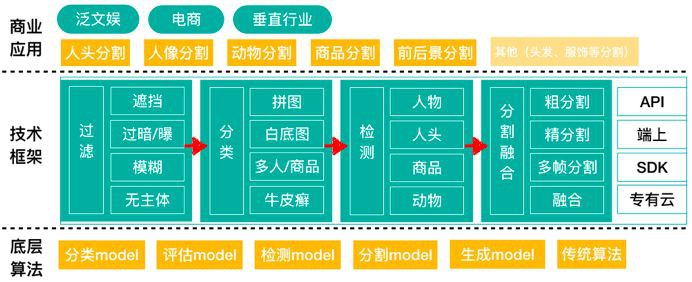
主要涵盖了过滤、分类、检测、分割四个模块:
[1] - 过滤:滤掉差图(过暗、过曝、模糊、遮挡等),主要用到分类模型和一些基础图像算法;
[2] - 分类:瓶饮美妆等品类商品连通性比较好,3C、日用、玩具等品类则反之,另外场景(如人头、人像、动物)需求也是各具差异,故而设计不同的分割模型提升效果;
[3] - 检测:在鹿班场景用户数据多来自于商品图,很多是经过高度设计的图像,一图多商品、多品类、主体占比小,也不乏文案、修饰、logo等冗余信息,增加一步检测裁剪再做分割效果更精准;
[4] - 分割:先进行一层粗分割得到大致mask,再进行精细分割得到精确mask,这样一方面可以提速,一方面也可以精确到发丝级;
如何让效果更精准?
目前分类、检测模型相对比较成熟,而评估模型则需要根据不同场景做一些定制(电商设计图、天然摄影图等),分割精度不足,是所有模块中最薄弱的一个环节,因此成为了我们的主战场. 详述如下:
[1] - 分类模型:分类任务往往需要多轮的数据准备,模型优化,数据清洗才能够落地使用. 据此,我们设计完成了一个自动分类工具,融合最新的优化技术,并借鉴autoML的思想,在有限GPU资源的情况下做参数和模型搜索,简化分类任务中人员的参与,加速分类任务落地.
[2] - 评估模型:直接使用回归做分数拟合,训练效果并不好. 该场景下作为一个前序过滤任务,作为分类问题处理则比较合理. 实际我们也采用一些传统算法,协助进行过暗、过曝等判断.
[3] - 检测模型:主要借鉴了FPN检测架构.
- 对特征金字塔每一层featuremap都融合上下相邻层特征,这样输出的特征潜在表征能力更强;
- 特征金字塔不同层特征分别预测,候选anchors可增加对尺度变化的鲁棒性,提升小尺度区域召回;
- 对候选anchor的设定增加一些可预见的scale,在商品尺寸比例比较极端的情况下大幅提升普适性;
[4] - 分割融合模型:
参考论文:A Late Fusion CNN for Digital Matting - CVPR2019
Github - FusionMatting
与传统的只需要分别前景、背景的图像分割(segmentation)问题不同,高精度抠图算法需要求出某一像素具体的透明度是多少,将一个离散的0-1分类问题变成[0, 1]之间的回归问题. 在我们的工作中,针对图像中某一个像素p,我们使用这样一个式子来进行透明度预测:
$$ \alpha_p = \beta_p \bar{\mathbf{F}}_p + (1 - \beta_p)(1 - \bar{\mathbf{B}}_p) $$
其中 $\bar{\mathbf{F}}_p$ 和 $\bar{\mathbf{B}}_p$ 分别代表了这个像素属于前景和背景的概率,$\beta_p$ 是混合权重. 我们的网络可整体分为两部分,分割网络和融合网络,如下图:
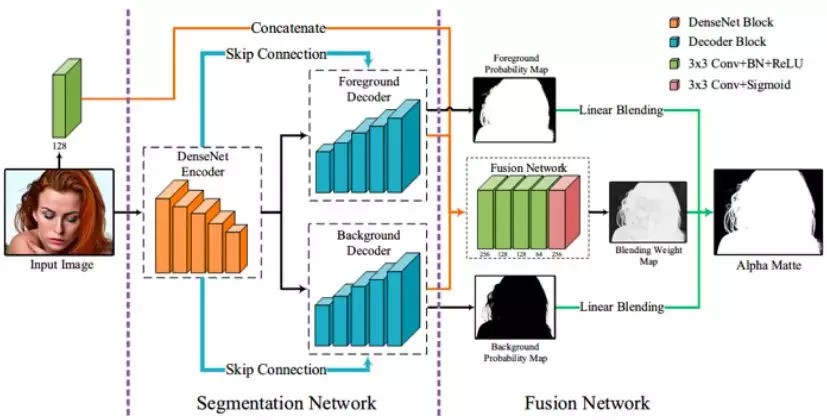
分割网络:使用了在图像分割任务中常用的编-解码器结构作为我们的基础结构,但与传统结构不同,网络中使用了双解码器分别来预测前、背景概率 $\bar{\mathbf{F}}_p$ 和 $\bar{\mathbf{B}}_p$. 如果像素 p 在图像的实心区域(透明度为0或1),我们预测像素透明度的真实值;如果p在图像的半透明区域(透明度值在0到1之间),我们预测像素透明度真实值的上下界. 通过在半透明区域使用加权的交叉熵损失函数,使 $\bar{\mathbf{F}}_p$ 和 $\bar{\mathbf{B}}_p$ 的值相应升高,即可将透明度的真实值“包裹”在[ $1-\bar{\mathbf{B}}_p$, $\bar{\mathbf{F}}_p$ ]这一区间中.

右图中红色部分即是被前背景概率包住的像素
融合网络:由数个连续卷积层构成,它负责预测混合权重$\beta_p$. 注意,在图像的实心区域,像素的前背景预测往往容易满足 Fp+Bp=1 这一条件,此时 $\alpha_p$ 和 $\beta_p $ 求导恒为 0,这一良好性质令融合网络在训练时可以自动“聚焦”于半透明区域.
3. 应用产品化开放
得以商业应用的基础是我们在应用层单点能力,如人像/人头/人脸/头发抠图、商品抠图、动物抠图,后续还会逐步支持卡通场景抠图、服饰抠图、全景抠图等. 据此我们也做了一些产品化工作,如鹿班的批量白底图功能、E应用证件照/战报/人物换背景(钉钉->我的->发现->小程序->画蝶)等.